go语言之反射
---恢复内容开始---
一 :并发基础
1 并发和并行
并发和并行是两个不同的概念:
并行意味着程序在任意时刻都是同时运行的:
并发意味着程序在单位时间内是同时运行的
详解:
并行就是在任一粒度的时间内都具备同时执行的能力:最简单的并行就是多机,多台机器
并行处理;SMP 表面上看是并行的,但由于是共享内存,以及线程间的同步等,不可能完全做
到并行
并发是在规定的时间内多个请求都得到执行和处理,强调的是给外界的感觉,实际上内部
可能是分时操作的 。并发重在避免阻塞,使程序不会因为 个阻 而停止处理。并发典型的应
用场景:分时操作系统就是一种并发设计(忽略多核 CPU )。
并行是硬件和操作系统开发者重点考虑的问题,作为应用层的程序员,唯一可以选择的就
是充分借助操作系统提供的 API 和程序语言特性,结合实际需求设计出具有良好并发结构的程
序,提升程序的并发处理能力。现代操作系统能够提供的最基础的并发模型就是多线程和多进
程;编程语言这一层级可以进一步封装来提升程序的井发处理能力。
在当前的计算机体系下:并行具有瞬时性,并发具有过程性;并发在于结构,井行在于执
行。应用程序具备好的并发结构,操作系统才能更好地利用硬件并行执行,同时避免阻塞等待,
合理地进行调度,提升 CPU 利用率。应用层程序员提升程序并发处理能力的一个重要手段就是
为程序设计良好的并发结构。
2 go语言之并发
go从语言层面就支持了并发,简化了并发程序的编写
3 goroutine 是什么
它是go并发设计的核心
goroutine就是协程,它比线程更小,十几个goroutine在底层可能就是五六个线程
go语言内部实现了goroutine的内存共享,执行goroutine只需极少的栈内存(大概是4~5KB)
4 创建goroutine
只需要在语句前添加go关键字,就可以创建并发执行单元
开发⼈员无需了解任何执⾏细节,调度器会自动将其安排到合适的系统线程上执行
package main import (
"fmt"
"time"
) //子协程
func newTask() {
i :=
for {
i++
fmt.Printf("new goroutin:i=%d\n", i)
time.Sleep( * time.Second)
}
} func main() {
//启动子协程
go newTask()
i :=
for {
i++
fmt.Printf("main goroutin:i=%d\n", i)
time.Sleep( * time.Second)
}
}
主线程退出 其他任务就不会执行了
package main import (
"fmt"
"time"
) func main() {
go func() {
i :=
for {
i++
fmt.Printf("new goroutin:i=%d\n", i)
time.Sleep( * time.Second)
}
}() i :=
for {
i++
fmt.Printf("main goroutin:i=%d\n", i)
time.Sleep( * time.Second)
if i == {
break
}
}
}
main里面没有东西,其他任务也不会执行
package main
import (
"fmt"
"time"
)
func main() {
go func() {
i:=
for {
i++
fmt.Printf("new goroutine:i=%d\n",i)
time.Sleep(* time.Second)
}
}()
}
5 runtime包
runtime.Gosched():出让CPU时间片,等待重新安排任务
package main import (
"fmt"
"runtime"
)
func main() {
go func(s string) {
for i:=;i<;i++{
fmt.Println(s)
}
}("world")
for i :=;i<;i++{
//出让时间片
runtime.Gosched()
fmt.Println("hello")
}
}
/* 打印结果
world
world
hello
hello
*/
runtime.Goexit():立刻结束当前携程的执行
package main import (
"fmt"
"runtime"
"time"
) func main() {
go func() {
defer fmt.Println("A.defer")
//匿名函数
func () {
defer fmt.Println("A.defer")
runtime.Goexit()
fmt.Println("B")
}()
fmt.Println("A")
}()
for {
time.Sleep(time.Second)
}
}
runtime.GOMAXPROCS():设置并行计算的CPU最大核数
package main
import (
"fmt"
"runtime"
)
func main() {
n :=runtime.GOMAXPROCS()
fmt.Printf("n=%d\n",n)
for {
go fmt.Println()
fmt.Println()
}
}
6 通道
概述:
goroutine 运行在相同的地址空间,因此访问共享内存必须做好同步,处理好线程安全问题
goroutine奉行通过通信来共享内存,而不是共享内存来通信
channel是一个引用类型,共用多个goroutine通讯,其内部实现了同步,确保并发安全
channel的基本使用
channel可以用内置make()函数创建
定义一个channel时,也需要定义发送到channel的值的类型
make(chan 类型)
make(chan 类型, 容量)
当 capacity= 时,channel 是无缓冲阻塞读写的,当capacity> 时,channel 有缓冲、是非阻塞的,直到写满 capacity个元素才阻塞写入
channel通过操作符<-来接收和发送数据,发送和接收数据语法:
channel <- value //发送value到channel
<-channel //取出数据扔掉
x := <-channel //取出数据,给x
x, ok := <-channel //功能同上,顺便检查一下通道
package main
import "fmt"
func main() {
c := make(chan int) //创建一个通道
go func() {
defer fmt.Println("子携程结束")
fmt.Println("子携程正在运行。。。")
c <-
}()
<-c
num := <-c
fmt.Println("num=",num)
fmt.Println("main结束")
}
无反冲的channel
无缓冲的通道是指在接收前没有能力保存任何值的通道

package main
import (
"fmt"
"time"
)
func main() {
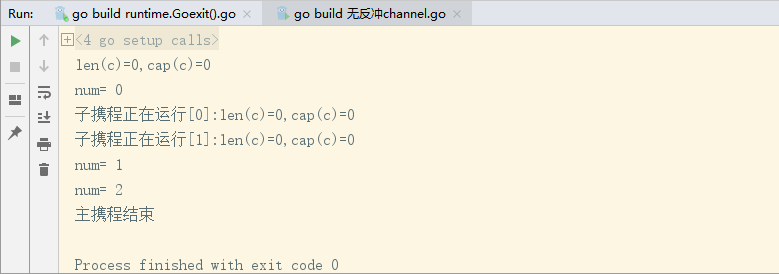
//无反冲通道
c := make(chan int,)
fmt.Printf("len(c)=%d,cap(c)=%d\n",len(c),cap(c))
//子携程存数据
go func() {
defer fmt.Println("子携程结束")
//向通道添加数据
for i := ; i<;i++ {
c <- i
fmt.Printf("子携程正在运行[%d]:"+"len(c)=%d,cap(c)=%d\n",i,len(c),cap(c))
}
}()
time.Sleep(*time.Second)
//主携程取数据
for i :=;i<;i++{
num :=<- c
fmt.Println("num=",num)
}
fmt.Println("主携程结束")
}
运行结果
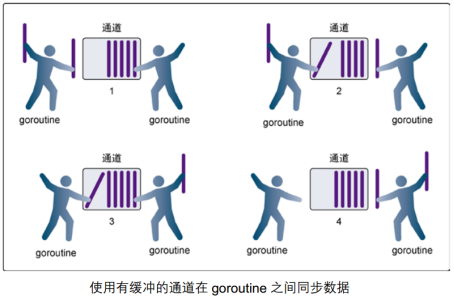
有换成的channel
有缓冲的通道是一种在被接收前能存储一个或者多个值的通道
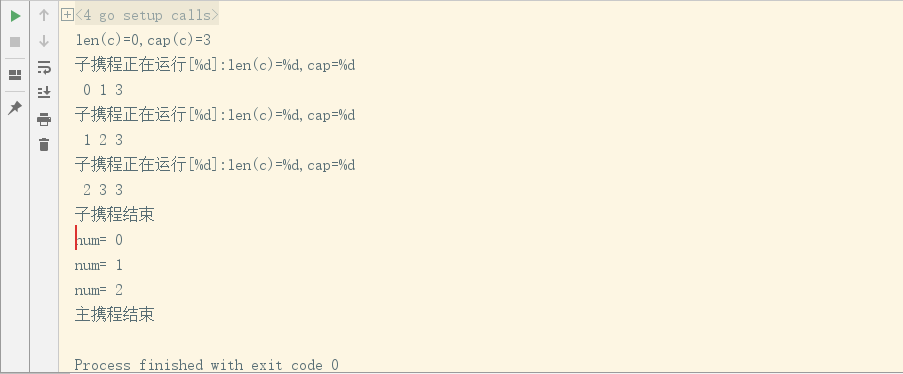
package main import (
"fmt"
"time"
) func main() {
//无缓冲通道
c := make(chan int,)
fmt.Printf("len(c)=%d,cap(c)=%d\n",len(c),cap(c))
//字携程存数据
go func() {
defer fmt.Println("子携程结束")
//向通道添加数据
for i :=;i <;i++{
c<-i
fmt.Println("子携程正在运行[%d]:"+"len(c)=%d,cap=%d\n",i,len(c),cap(c))
}
}()
time.Sleep(*time.Second)
//主携程取数据
for i :=;i<;i++{
num :=<- c
fmt.Println("num=",num)
}
fmt.Println("主携程结束")
}
7 关闭通道
可以通过内置的close()函数关闭channel
package main import (
"fmt"
) func main() {
c := make(chan int)
//子协程存数据
go func() {
for i := ; i < ; i++ {
c <- i
}
close(c)
}()
//主协程取数据
for {
if data, ok := <-c; ok {
fmt.Println(data)
} else {
break
}
}
fmt.Println("主协程结束")
}
8,单方向的channel
默认情况下,通道是双向的,也就是,既可以往里面发送数据也可以接收数据
go可以定义单方向的通道,也就是只发送数据或者只接收数据,声明如下
var ch1 chan int //正常
var ch2 chan<- float64 //只能写float64
var ch3 <-chan int //只能读int类型数据
可以将 channel 隐式转换为单向队列,只收或只发,不能将单向 channel 转换为普通channel
package main
func main() {
//定义个正常的
c:=make(chan int,)
//转换为只写的通道
var send chan <-int =c
//转换为只读
var recv <-chan int = c
//写数据
send <-
//读数据
<-recv
//不能单的转回正常的
//xx :=(chan int)(send)
}
单向的有啥用?可以用作生产者和消费者问题
package main import (
"fmt"
) //生产者,只写
func producter(out chan <- int) {
defer close(out)
for i :=;i<;i++ {
out <- i
}
}
//消费者,只读
func consumer(in <- chan int){
for num :=range in{
fmt.Println(num)
}
}
func main() {
//正常通道
c:=make(chan int)
//生产者
go producter(c)
//消费者
consumer(c)
fmt.Println("done")
}
9 定时器
Timer:时间到了,响应一次
package main import (
"time"
"fmt"
) func main() {
////1.创建定时器
//timer1 := time.NewTimer(time.Second * 2)
////打印系统当前时间
//t1 := time.Now()
//fmt.Printf("t1:%v\n", t1)
//t2 := <-timer1.C
//fmt.Printf("t2:%v\n", t2) //2.timer响应
//timer2 := time.NewTimer(time.Second)
//for {
// <-timer2.C
// fmt.Println("时间到")
//} //3.timer延时
//time.Sleep(2 * time.Second)
//fmt.Println("2秒时间到")
//timer3 := time.NewTimer(3 * time.Second)
//<-timer3.C
//fmt.Println("3秒时间到") //4.停止定时器
//timer4 := time.NewTimer(3 * time.Second)
//go func() {
// <-timer4.C
// fmt.Println("定时器时间到了")
//}()
////停止定时器
//stop := timer4.Stop()
//if stop {
// fmt.Println("timer4已经关闭")
//} //5.重置定时器
timer5 := time.NewTimer( * time.Second)
timer5.Reset(time.Second)
fmt.Println(time.Now())
fmt.Println(<-timer5.C) for {
}
}
Ticker,不停地响应
package main import (
"time"
"fmt"
) func main() {
////1.创建定时器
ticker := time.NewTicker(time.Millisecond)
i :=
go func() {
for {
<-ticker.C
fmt.Println(<-ticker.C)
i++
fmt.Println("i=", i)
//停止定时器
if i == {
ticker.Stop()
}
}
}()
for {
}
}
9 select
go语言提供了select关键字,可以监听channel上的数据流动
语法与switch类似,区别是select要求每个case语句里必须是一个IO操作
select {
case <-chan1:
// 如果chan1成功读到数据,则进行该case处理语句
case chan2 <- :
// 如果成功向chan2写入数据,则进行该case处理语句
default:
// 如果上面都没有成功,则进入default处理流程
}
注意:
操作不同状态的chan会引发三种行为
panic
()向已经关闭的通道写数据会导致 panic
最佳实践是由写入者关闭通道,能最大程度地避免向已经关闭的通道写数据而导致的 panic
()重复关闭的通道会导致 panic
10 阻塞与非阻塞
阻塞:
向未初始化的通道写数据或读数据都会导致当前goroutine的永久阻塞
向缓冲区已满的通道写入数据会导致goroutine阻塞
通道中没有数据,读取该通道会导致goroutine阻塞
非阻塞:
读取已经关闭的通道不会引发阻塞,而是立即返回通道元素类型的零值,comma.ok 语法判断通道是否已经关闭
向有缓冲且没有满的通道读/写不会引发阻塞
二:并发范式
1,生成器
应用场景:
是调用一个统 的全局的生成器服务, 于生成全
局事务号、订单号、序列号和随机数等
(1)带缓冲的生成器
package main
import (
"fmt"
"math/rand"
)
func GenerateIntA()chan int{
ch :=make(chan int,)
//启动一个goroutine 用于生成随机数
go func() {
for {
ch <- rand.Int() //读取一个随机数
}
}()
return ch
} func main() {
ch := GenerateIntA()
fmt.Println(<-ch)
fmt.Println(<-ch)
}
(2) 多个goroutine增强型生成器
package main import (
"fmt"
"math/rand" ) func GenerateIntA() chan int {
ch := make(chan int,)
go func() {
for {
ch<-rand.Int()
}
}()
return ch
}
func GenerateIntB() chan int {
ch :=make(chan int,)
go func() {
for {
ch <-rand.Int()
}
}()
return ch
} func GenerateInt() chan int{
ch :=make(chan int,)
go func() {
for {
//使用 selecet聚合多条通道服务;所谓的扇出是指将一条通道发散到多条通道中处理,
//在Go语言里面具体实现就是使用go关键字启动多个goroutine并发处理。
select {
case ch <- <- GenerateIntA(): //监听通道数据
case ch <- <-GenerateIntB():
}
}
}()
return ch
}
func main() {
ch :=GenerateInt()
for i :=; i<;i++{
fmt.Println(<-ch)
}
}
运行效果

(3) 有时需要生成器自动退出,可以借助go通道的退出机制(close channel to broadcast)来实现
package main import (
"fmt"
"math/rand"
) func GenerateIntA(done chan struct{}) chan int {
ch := make(chan int)
go func() {
lable:
for {
//通过select监听一个信号chan 来确定是否停止生成
select {
case ch <- rand.Int():
case <- done:
break lable
}
}
close(ch)
}()
return ch
}
func main() {
done := make(chan struct{})
ch := GenerateIntA(done)
fmt.Println(<-ch)
fmt.Println(<-ch)
//不在需要生成器通过close chan 发送一个通知给生成器
close(done)
for v :=range ch{
fmt.Println(v)
}
}
(4) 一个融合了并发、缓冲、退出通知等多重特性的生成器
package main import (
"fmt"
"math/rand"
) //done 接收通知退出信号
func GenerateIntA(done chan struct{}) chan int {
ch := make(chan int,)
go func() {
label:
for {
select {
case ch <- rand.Int():
case <- done:
break label
}
}
close(ch)
}()
return ch
}
func GenerateIntB(done chan struct{}) chan int {
ch :=make(chan int,)
go func() {
label:
for {
select {
case ch <-rand.Int():
case <-done:
break label
}
}
close(ch)
}()
return ch
} //通过select 执行扇入操作
func GenerateInt( done chan struct{}) chan int {
ch := make(chan int)
send :=make(chan struct{})
go func() {
label:
for {
select {
case ch <- <- GenerateIntA(send):
case ch <- <- GenerateIntB(send):
case <-done:
send <- struct{}{}
send <- struct{}{}
break label
}
}
close(ch)
}()
return ch
}
func main() {
//创建一个作为接收退出信号的chan
done := make(chan struct{})
//启动生成器
ch :=GenerateInt(done)
//获取生成器资源
for i:=; i<;i++{
fmt.Println(<- ch)
}
//通知生产者停止生产
done <- struct{}{}
fmt.Println("stop gernarate")
}
2 固定工作池
服务器编程中使用最多的就是通过线程池来提升服务的并发处理能力,在go中一样可以轻松地构建固定数目的goroutines作为工作线程池
程序中除了主要的main goroutine,还开启了如下几类goroutine:
{1} 初始化任务的goroutine
{2} 分发任务的goroutine。
{3} 等待所有worker结束通知,然后关闭结果通道goroutine。main函数负责拉起上述goroutine并从结果通道获取最终结果。
1,传递task任务通道
2.传递task结果通道
3,接收worker处理完任务后所发送通知的通道
package main import (
"fmt"
) const (
NUMBER =
) //工作任务
type task struct {
begin int
end int
result chan<- int
}
//任务处理:计算begin到end 的和
//执行结果写入结果chan result
func (t *task) do() {
sum :=
for i :=t.begin;i<=t.end;i++{
sum += i
}
t.result <- sum
} func main() {
workers :=NUMBER
//创建通道
taskchan :=make(chan task,)
//结果通道
resultchan :=make(chan int,)
//worker 信号通道
done :=make(chan struct{},)
//初始化task的goroutine,计算100个自然数之和
go Inittask(taskchan,resultchan,)
//分发任务到NUMBER个goroutine池中
DistributeTask(taskchan,workers,done)
//获取各个goroutine 处理完成任务通知,并关闭结果通道
go CloseResult(done,resultchan,workers)
//t通过结果通道获取结果并汇总
sum :=ProcessResult(resultchan)
fmt.Println("sum=",sum)
}
//初始化待处理任务 通道 (task cham) func Inittask(taskchan chan<- task,r chan int,p int) {
qu := p/
mod :=p%
high :=qu*
for j :=; j<qu;j++{
b:=*j +
e :=*(j+)
tsk :=task{
begin:b,
end:e,
result:r,
}
taskchan <-tsk
}
if mod != {
tsk :=task{
begin:high +,
end: p,
result:r,
}
taskchan<- tsk
}
close(taskchan)
}
//读取task chan 并分发到worker goroutine 处理,总的数量是workers
func DistributeTask(taskchan <-chan task, workers int,done chan struct{}) {
for i := ; i<workers;i++{
go ProcessTask(taskchan,done)
}
}
//工作goroutine处理具体工作,并将处理结果发送到
func ProcessTask(taskchan <-chan task,done chan struct{}) {
for t :=range taskchan{
t.do()
}
done <- struct{}{}
}
//通过done channel 同步等待所有工作goroutine的结束,然后关闭结果chan
func CloseResult(done chan struct{},resultchan chan int,workers int) {
for i:= ;i <workers;i++{
<-done
}
close(done)
close(resultchan)
}
//读取结果通道
func ProcessResult(resultchan chan int) int {
sum :=
for r := range resultchan{
sum +=r
}
return sum
}
逻辑分析:
构建task并发送到task通道中
分别启动n个工作线程,不停地从task通道中获取任务,然后将结果写入到结果通道
收到结果的goroutine接收到所有task已经处理完毕的信号,主动关闭结果通道
main 中函数ProcessResult 读取并统计所有的结果

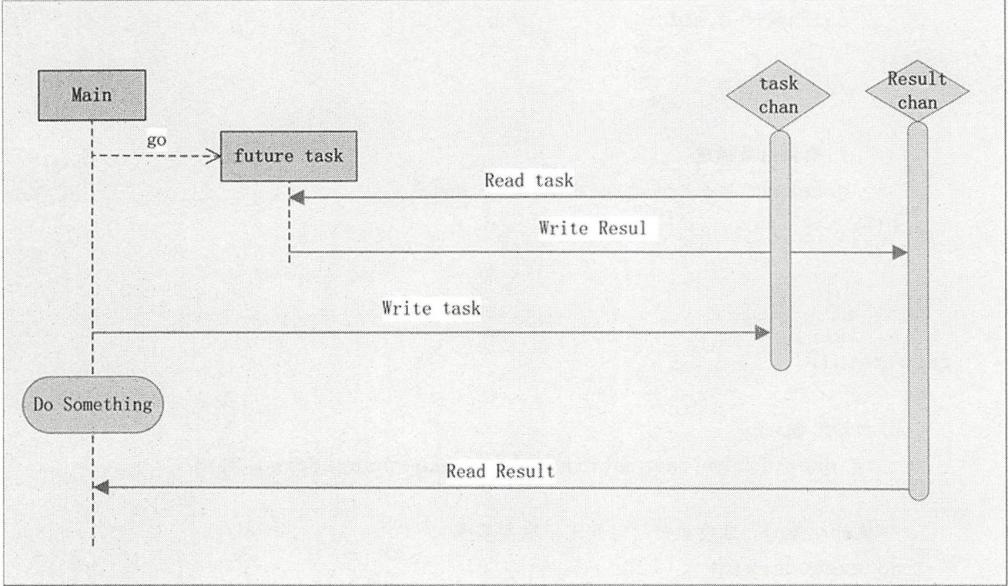
3 future模式
应用场景:
编程中经常遇到在一个流程中需要调用多个子调用的情况,这些子调用相互之间没有依赖,
如果串行地调用,则耗时会很长,此时可以使用GO并发编程中的future模式
工作原理
()使用 an 作为函数参数。
()启动 oroutine 调用函数。
()通过 han 传入参数。
()做其他可以并行处理的事情。
()通过 chan 异步获取结果
示例:
package main import (
"fmt"
"time"
) //一个查询结构体
//这里的sql 和result是一个简单抽象,具体的应用可能是更复杂的数据类型
type query struct {
//参数Channel
sql chan string
//结果channel
result chan string
}
//执行query
func execQuery(q query){
//启动协程
go func() {
//获取输入
sql :=<-q.sql
//访问数据库
//输出结果通道
q.result<-"result from " + sql
}()
} func main() {
//初始化Query
q :=query{make(chan string),make(chan string,)}
//执行query,注意执行的时候无须准备参数
go execQuery(q)
//发送参数
q.sql <-"select * from table"
//做其他事情,通过sleep描述
time.Sleep(*time.Second)
//获取结果
fmt.Println(<-q.result) } /*打印结果
result from select * from table
*/
缸” 最大的好处是将函数的同步调用转换为异步调用 适用于 个交易需要多 子调用
且这些子调用没有依赖的场景 实际情况可能比上面示例复杂得多,要考虑错误和异常的处理,
读者着重体验这种思想,而不是细节
三:context标准库
Go 中的 goroutine 之间没有父与子的关系,也就没有所谓子进程退出后的通知机制,多个
goroutine 都是平行地被调度,多个 goroutine 如何协作工作涉及通信、同步、通知和退出四个方面。
通信: chan 通道当然是 goroutine 之间通信的基础, 注意这里的通信主要是指程序的数据通道
同步:不带缓冲的 han 提供了一个天然的同步等待机制:当然 sync.WaitGroup 也为多个go routine 协同工作提供 种同步等待机制
通知:这个通知和上面通信的数据不一样,通知通常不是业务数据,而是管理、控制流数据。要处理这个也好办,在输入端绑定两个 chan,一个用于业务流数据,另 个用于异常通知
数据,然后通过 select 收敛进行处理。这个方案可以解决简 的问题,但不是一个通用的解决方案。
退出: goroutine 之间没有父子关系,如何通知 goroutine 退出?可以通过增加一个单独的通
道,借助通道和 select 的广播机制( close channel to broadcast )实现退出
---恢复内容结束---
go语言之反射的更多相关文章
- go语言通过反射获取和设置结构体字段值的方法
本文实例讲述了go语言通过反射获取和设置结构体字段值的方法.分享给大家供大家参考.具体实现方法如下: type MyStruct struct { N int } n := MyStruct{ 1 } ...
- Go语言之反射(一)
反射 反射是指在程序运行期对程序本身进行访问和修改的能力.程序在编译时,变量被转换为内存地址,变量名不会被编译器写入到可执行部分.在运行程序时,程序无法获取自身的信息.支持反射的语言可以在程序编译期将 ...
- 深度解密Go语言之反射
目录 什么是反射 为什么要用反射 反射是如何实现的 types 和 interface 反射的基本函数 反射的三大定律 反射相关函数的使用 代码样例 未导出成员 反射的实际应用 json 序列化 De ...
- Go语言 8 反射
文章由作者马志国在博客园的原创,若转载请于明显处标记出处:http://www.cnblogs.com/mazg/ Go学习群:415660935 8.1概念和作用 Reflection(反射)在计算 ...
- Go语言之反射(二)
反射的值对象 反射不仅可以获取值的类型信息,还可以动态地获取或者设置变量的值.Go语言中使用reflect.Value获取和设置变量的值. 使用反射值对象包装任意值 Go语言中,使用reflect.V ...
- Go语言的反射
反射是语言里面是非常重要的一个特性,我们经常会看见这个词,但是对于反射没有一个很好的理解,主要是因为对于反射的使用场景不太熟悉. 一.理解变量的内在机制 1.类型信息,元信息,是预先定义好的,静态的. ...
- 列举java语言中反射的常用方法
package review;/*12:43 2019/7/21*/ import model.AnotherClass; import model.OneClassMore; import mode ...
- Go语言之反射(三)
结构体转JSON JSON格式是一种用途广泛的对象文本格式.在Go语言中,结构体可以通过系统提供的json.Marshal()函数进行序列化.为了演示怎么样通过反射获取结构体成员以及各种值的过程,下面 ...
- Go语言基础之反射
Go语言基础之反射 本文介绍了Go语言反射的意义和基本使用. 变量的内在机制 Go语言中的变量是分为两部分的: 类型信息:预先定义好的元信息. 值信息:程序运行过程中可动态变化的. 反射介绍 反射是指 ...
随机推荐
- P4383 [八省联考2018]林克卡特树 树形dp Wqs二分
LINK:林克卡特树 作为树形dp 这道题已经属于不容易的级别了. 套上了Wqs二分 (反而更简单了 大雾 容易想到还是对树进行联通情况的dp 然后最后结果总和为各个联通块内的直径. \(f_{i,j ...
- QT学习笔记(day01)
QT中的对象树 一定程度上简化了内存回收机制:当创建的对象 指定的父亲是由QObject或者Object派生的类时候,这个对象被加载到对象树上,当窗口关闭掉时候,树上的对象也都会被释放掉 信号和槽 通 ...
- Android中Activity启动模式探索
Android中启动模式(launchMode)分为standard, singleTop, singleTask, singleInstance四种,可通过AndroidManifest.xml文件 ...
- 好用的连接池-druid
druid连接池是阿里巴巴的数据库连接池项目.它的一个亮点强大的监控功能以及防SQL注入,同时不影响性能.这里是它的GitHub地址.感觉druid扩展的功能还是很实用的. 实用的功能 详细的监控 E ...
- C#/.Net集成RabbitMQ
RabbitMQ简介 消息 (Message) 是指在应用间传送的数据.消息可以非常简单,比如只包含文本字符串. JSON 等,也可以很复杂,比如内嵌对象. 消息队列中间件 (Message Queu ...
- 最新版CentOS8系统安装和基本配置
一.Centos8新版简介 Redhat公司在2019年5月推出了rhel8,年底推出了centos8,紧接着也会把相关的技术认证完全转换为新平台. 阿里云.华为云目前也已推出centos8的公共镜像 ...
- C#LeetCode刷题之#326-3的幂(Power of Three)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3867 访问. 给定一个整数,写一个函数来判断它是否是 3 的幂次 ...
- Android Studio && GitHub 团队多人一起开发
曾几何时,花了两天的时间搞了合并项目,搞得乱七八糟der,但最终还是被我搞定了,too 乱 to 做笔记.过了几个月,也就是前几天,抱着从头开始的决心,再次尝试,然鹅并没有结果.今天,再一次重新开始, ...
- 输入url后的加载过程~
1)查找域名对应的IP地址: 2)建立连接(TCP的三次握手): 3)构建网页: 4)断开连接(TCP的四次挥手): TCP的三次握手:为了准确无误的把数据送到目标处,TCP协议采用了三次握手策略,用 ...
- 虚拟化技术之kvm虚拟机创建工具virt-install
在前边的博客中,我们创建KVM虚拟机用到了virt-manager,这个工具是一个图形化工具,创建虚拟机很方便:除此我们还是用virsh define/create +虚拟机配置文件来创建虚拟机,这种 ...