【SpringBoot】前缀树 Trie 过滤敏感词
1、过滤敏感词
Spring Boot实践,开发社区核心功能
完成过滤敏感词
Trie
- 名称:Trie也叫做字典树、前缀树(Prefix Tree)、单词查找树
- 特点:查找效率高,消耗内存大
- 应用:字符串检索、词频统计、字符串排序等
Trie 搜索字符串的效率主要跟字符串的长度有关
最大的特点就是共享字符串的公共前缀来达到节省空间的目的了
更多Trie 相关的数据结构和算法
Double-array Trie、Suffix Tree、Patricia Tree、Crit-bit Tree、AC自动机
实现敏感词过滤器
- 定义前缀树
- 根据敏感词,初始化前缀树
- 编写过滤敏感词的方法
SensitiveFilter.java
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
// 替换符
private static final String REPLACEMENT = "***";
// 根节点
private TrieNode rootNode = new TrieNode();
//PostConstruct 容器实例化Bean 构造器 服务初始化
@PostConstruct
public void init() {
try (
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
while ((keyword = reader.readLine()) != null) {
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword) {
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if (subNode == null) {
// 初始化子节点
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指向子节点,进入下一轮循环
tempNode = subNode;
// 设置结束标识
if (i == keyword.length() - 1) {
tempNode.setKeywordEnd(true);
}
}
}
/**
* 过滤敏感词
*
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public String filter(String text) {
if (StringUtils.isBlank(text)) {
return null;
}
// 指针1
TrieNode tempNode = rootNode;
// 指针2
int begin = 0;
// 指针3
int position = 0;
// 结果
StringBuilder sb = new StringBuilder();
while (position < text.length()) {
char c = text.charAt(position);
// 跳过符号
if (isSymbol(c)) {
// 若指针1处于根节点,将此符号计入结果,让指针2向下走一步
if (tempNode == rootNode) {
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
continue;
}
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
} else if (tempNode.isKeywordEnd()) {
// 发现敏感词,将begin~position字符串替换掉
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = rootNode;
} else {
// 检查下一个字符
position++;
}
}
// 将最后一批字符计入结果
sb.append(text.substring(begin));
return sb.toString();
}
// 判断是否为符号
private boolean isSymbol(Character c) {
// 0x2E80~0x9FFF 是东亚文字范围
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
// 前缀树
private class TrieNode {
// 关键词结束标识
private boolean isKeywordEnd = false;
// 子节点(key是下级字符,value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node) {
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c) {
return subNodes.get(c);
}
}
}
要过滤的单词sensitive-words.txt
shit
傻逼
笨蛋
...
敏感词
测试
SensitiveTests.java
@RunWith(SpringRunner.class)
@SpringBootTest
@ContextConfiguration(classes = CommunityApplication.class)
public class SensitiveTests {
@Autowired
private SensitiveFilter sensitiveFilter;
@Test
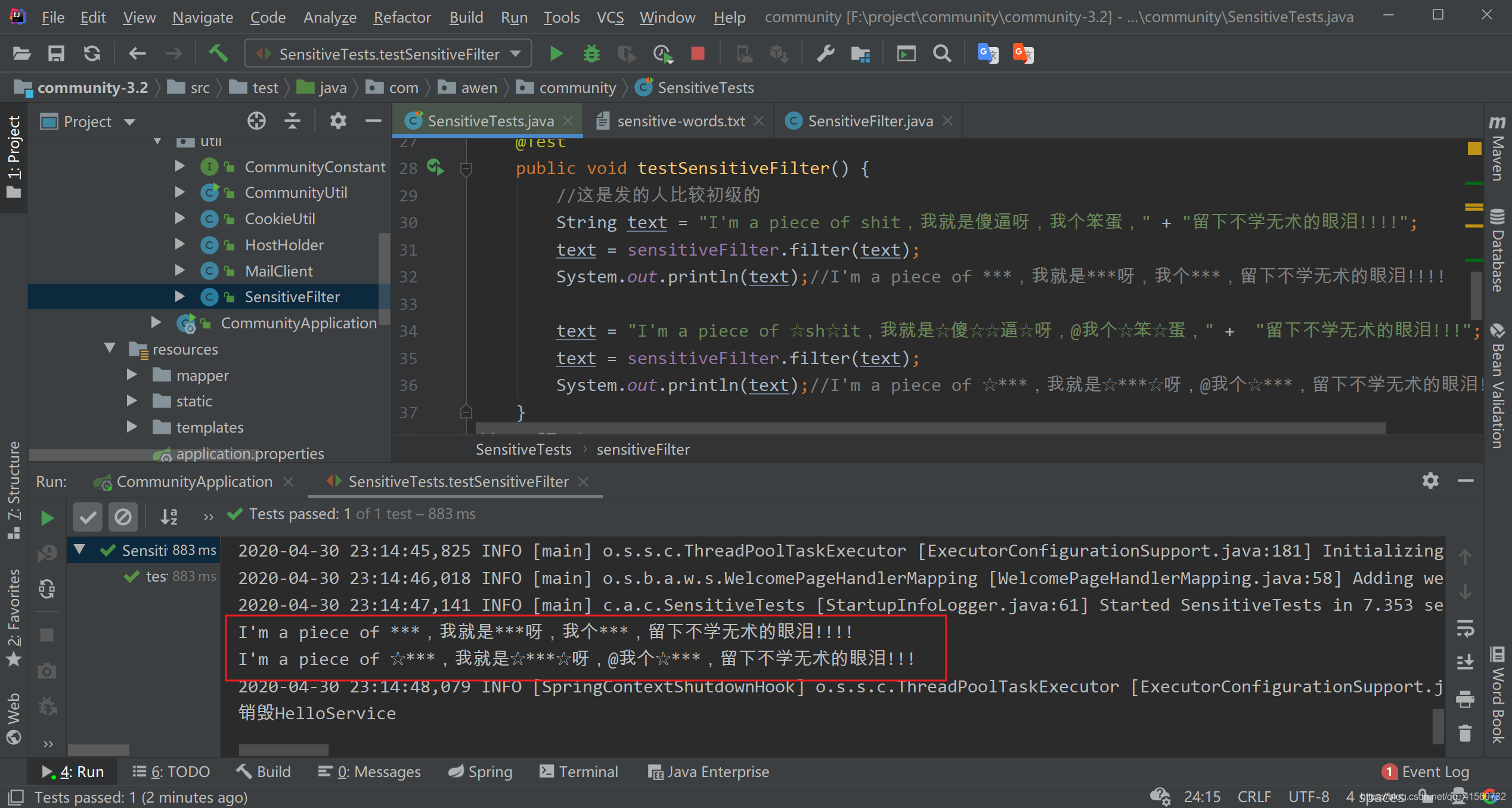
public void testSensitiveFilter() {
//这是发的人比较初级的
String text = "I'm a piece of shit,我就是傻逼呀,我个笨蛋," + "留下不学无术的眼泪!!!!";
text = sensitiveFilter.filter(text);
System.out.println(text);//I'm a piece of ***,我就是***呀,我个***,留下不学无术的眼泪!!!!
text = "I'm a piece of ☆sh☆it,我就是☆傻☆☆逼☆呀,@我个☆笨☆蛋," + "留下不学无术的眼泪!!!";
text = sensitiveFilter.filter(text);
System.out.println(text);//I'm a piece of ☆***,我就是☆***☆呀,@我个☆***,留下不学无术的眼泪!!!
}
}
Result
记录
1、高薪求职项目课 - vol.7 - https://www.nowcoder.com/courses/semester/senior
是记录这个社区项目的笔记。
Github : https://github.com/liuawen/play-community
【SpringBoot】前缀树 Trie 过滤敏感词的更多相关文章
- SpringBoot开发十四-过滤敏感词
项目需求-过滤敏感词 利用 Tire 树实现过滤敏感词 定义前缀树,根据敏感词初始化前缀树,编写过滤敏感词的方法 代码实现 我们首先把敏感词存到一个文件 sensitive.txt: 赌博 嫖娼 吸毒 ...
- 过滤敏感词工具类SensitiveFilter
网上过滤敏感词工具类有的存在挺多bug,这是我自己改用的过滤敏感词工具类,目前来说没啥bug,如果有bug欢迎在评论指出 使用前缀树 Trie 实现的过滤敏感词,树节点用静态内部类表示了,都写在一个 ...
- [原创] Trie树 php 实现敏感词过滤
目录 背景 简介 存储结构 PHP 其他语言 字符串分割 示例代码 php 优化 缓存字典树 常驻服务 参考文章 背景 项目中需要过滤用户发送的聊天文本, 由于敏感词有将近2W条, 如果用 str_r ...
- (转)两种高效过滤敏感词算法--DFA算法和AC自动机算法
原文:https://blog.csdn.net/u013421629/article/details/83178970 一道bat面试题:快速替换10亿条标题中的5万个敏感词,有哪些解决思路? 有十 ...
- 【暑假】[实用数据结构]前缀树 Trie
前缀树Trie Trie可理解为一个能够快速插入与查询的集合,无论是插入还是查询所需时间都为O(m) 模板如下: +; ; struct Trie{ int ch[maxnode][sigma_siz ...
- web前端js过滤敏感词
web前端js过滤敏感词 这里是用文本输入框还有文本域绑定了失去焦点事件,然后再遍历敏感词数组进行匹配和替换. var keywords=["阿扁","呵呵", ...
- 萌新笔记——用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成"* ...
- 用KMP算法与Trie字典树实现屏蔽敏感词(UTF-8编码)
前几天写好了字典,又刚好重温了KMP算法,恰逢遇到朋友吐槽最近被和谐的词越来越多了,于是突发奇想,想要自己实现一下敏感词屏蔽. 基本敏感词的屏蔽说起来很简单,只要把字符串中的敏感词替换成“***”就可 ...
- PHP 扩展 trie-tree, swoole过滤敏感词方案
在一些app,web中评论以及一些文章会看到一些*等,除了特定的不显示外,我们会把用户输入的一些敏感字符做处理,具体显示为*还是其他字符按照业务区实现. 下面简单介绍下业务处理. 原文地址:小时刻个人 ...
随机推荐
- SpringBoot魔法堂:应用热部署实践与原理浅析
前言 后端开发的同学想必每天都在重复经历着修改代码.执行代码编译,等待--重启Tomcat服务,等待--最后测试发现还是有bug,然后上述流程再来一遍(我听不见)
- iOS10 App适配权限 Push Notifications 字体Frame 遇到的坑!!!!
添加配置权限 <!-- 相册 --> <key>NSPhotoLibraryUsageDescription</key> <string>"x ...
- js上 四、数据类型转换
1. 转布尔类型 Boolean():可以将任意类型的数据转为布尔类型: 语法:Boolean(值) 规则:
- 听说特斯拉花了4个月研发出新ERP,然后很多人都疯了
欢迎关注微信公众号:sap_gui (ERP咨询顾问之家) 最近这件事儿在SAP圈里炒的挺火的,最主要是因为这几个关键词: 放弃SAP.4个月.自研ERP: 这则新闻一出来,很多人都兴高采烈,都要疯了 ...
- Python高级语法-私有属性-名字重整(4.7.1)
@ 目录 1.说明 2.代码 关于作者 1.说明 使用__dict__魔法方法 可以看到所有的属性,包括公有的,私有的,保护的等等 不能调用的原因就是,解释器把名字属性给重组了 其实是可以访问到的 2 ...
- 容器编排系统k8s之Service资源
前文我们了解了k8s上的DemonSet.Job和CronJob控制器的相关话题,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/14157306.html:今 ...
- [从源码学设计]蚂蚁金服SOFARegistry 之 如何与Meta Server交互
[从源码学设计]蚂蚁金服SOFARegistry 之 如何与Meta Server交互 目录 [从源码学设计]蚂蚁金服SOFARegistry 之 如何与Meta Server交互 0x00 摘要 0 ...
- Solr:Slor初识(概述、Windows版本的安装、添加IK分词器)
1.Solr概述 (1)Solr与数据库相比的优势 搜索速度更快.搜索结果能够按相关度排序.搜索内容格式不固定等 (2)Lucene与Solr的区别 Lucene提供了完整的查询引擎和索引引擎,目的是 ...
- Selenium Web元素定位方法
Selenium是用于Web应用测试的自动化测试框架,可以实现跨浏览器和跨平台的Web自动化测试.Selenium通过使用WebDriver API来控制web浏览器,每个浏览器都都有一个特定的Web ...
- 安装篇八:配置 Nginx 使其支持 MySQL 应用
配置说明 (让nginx MySQL(中间件)之间建立关系) 第一个里程: 编写nginx.php首页文件 第二个里程:重启nginx 第三个里程:访问网页测试 打开浏览器访问:http://47. ...