Python之爬虫(十四) Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍
Scrapy目前已经可以很好的在python3上运行
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。对于会阻塞线程的操作包含访问文件、数据库或者Web、产生新的进程并需要处理新进程的输出(如运行shell命令)、执行系统层次操作的代码(如等待系统队列),Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。
Scrapy data flow(流程图)
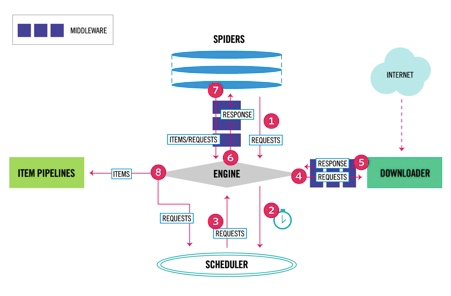
Scrapy数据流是由执行的核心引擎(engine)控制,流程是这样的:
1、爬虫引擎ENGINE获得初始请求开始抓取。
2、爬虫引擎ENGINE开始请求调度程序SCHEDULER,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器DOWNLOADER,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎ENGINE。
6、爬虫引擎ENGINE将下载器DOWNLOADER的响应通过中间件MIDDLEWARES返回给爬虫SPIDERS进行处理。
7、爬虫SPIDERS处理响应,并通过中间件MIDDLEWARES返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器SCHEDULER,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
各个组件介绍
爬虫引擎(ENGINE)
爬虫引擎负责控制各个组件之间的数据流,当某些操作触发事件后都是通过engine来处理。
调度器(SCHEDULER)
调度接收来engine的请求并将请求放入队列中,并通过事件返回给engine。
下载器(DOWNLOADER)
通过engine请求下载网络数据并将结果响应给engine。
Spider
Spider发出请求,并处理engine返回给它下载器响应数据,以items和规则内的数据请求(urls)返回给engine。
管道项目(item pipeline)
负责处理engine返回spider解析后的数据,并且将数据持久化,例如将数据存入数据库或者文件。
下载中间件
下载中间件是engine和下载器交互组件,以钩子(插件)的形式存在,可以代替接收请求、处理数据的下载以及将结果响应给engine。
spider中间件
spider中间件是engine和spider之间的交互组件,以钩子(插件)的形式存在,可以代替处理response以及返回给engine items及新的请求集。
如何创建Scrapy项目
创建Scrapy项目
创建scrapy项目的命令是scrapy startproject 项目名,创建一个爬虫
进入到项目目录scrapy genspider 爬虫名字 爬虫的域名,例子如下:
zhaofandeMBP:python_project zhaofan$ scrapy startproject test1
New Scrapy project 'test1', using template directory '/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/scrapy/templates/project', created in:
/Users/zhaofan/Documents/python_project/test1 You can start your first spider with:
cd test1
scrapy genspider example example.com
zhaofandeMBP:python_project zhaofan$
zhaofandeMBP:test1 zhaofan$ scrapy genspider shSpider hshfy.sh.cn
Created spider 'shSpider' using template 'basic' in module:
test1.spiders.shSpider
scrapy项目结构
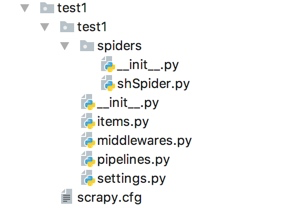
items.py 负责数据模型的建立,类似于实体类。
middlewares.py 自己定义的中间件。
pipelines.py 负责对spider返回数据的处理。
settings.py 负责对整个爬虫的配置。
spiders目录 负责存放继承自scrapy的爬虫类。
scrapy.cfg scrapy基础配置
Python之爬虫(十四) Scrapy框架的架构和原理的更多相关文章
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫知识点四--scrapy框架
一.scrapy结构数据 解释: 1.名词解析: o 引擎(Scrapy Engine)o 调度器(Scheduler)o 下载器(Downloader)o 蜘蛛(Spiders)o 项目管 ...
- PYTHON网络爬虫与信息提取[scrapy框架应用](单元十、十一)
scrapy 常用命令 startproject 创建一个新的工程 scrapy startproject <name>[dir] genspider 创建一个爬虫 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection) Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数 ...
- 第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制
第三百四十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—craw母版l创建自动爬虫文件—以及 scrapy item loader机制 用命令创建自动爬虫文件 创建爬虫文件是根据scrap ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
随机推荐
- 03 . Jenkins构建之代码扫描
Sonar简介 Sonar 是一个用于代码质量管理的开放平台.通过插件机制,Sonar可以集成不同的测试工具,代码分析工具,以及持续集成工具.与持续集成工具(例如 Hudson/Jenkins 等)不 ...
- 淘宝官网css初始化
body, h1, h2, h3, h4, h5, h6, hr, p, blockquote, dl, dt, dd, ul, ol, li, pre, form, fieldset, legend ...
- python基础--函数全解析
函数(重点) (1)初始函数 在认识函数之前,我们先做如下的需求: 让你打印10次"我爱中国,我爱祖国".我们在接触函数之前是这样写的. print('我爱中国,我爱祖国') pr ...
- [ C++ ] 勿在浮沙筑高台 —— 内存管理(18~31p) std::alloc
部分内容个人感觉不是特别重要,所以没有记录了.其实还是懒 embedded pointers 把对象的前四字节当指针用. struct obj{ struct obj *free_list_link; ...
- springboot集成jpa操作mybatis数据库
数据库如下 CREATE TABLE `jpa`.`Untitled` ( `cust_id` bigint() NOT NULL AUTO_INCREMENT, `cust_address` var ...
- centos 6.5 dhcp桥接方式上网络设置
首先虚拟机和主机之间采用桥接模式 然后在虚拟机中进行设置,首先进入到目录 /etc/sysconfig/network-scripts/ [root@localhost ~]# cd /etc/sys ...
- linuxshell编程之环境变量配置文件 Tony Linux系统工程师
视频参考慕课网 如果修改了环境变量的配置文件,要使得修改的环境变量生效可以使用下面的两个命令 下面是点后面加上了一个空格然后再加上配置文件,这里一定要注意下 这里要注意和隐藏文件的区别: 在linux ...
- 僵尸扫描-scapy、nmap
如果不知道僵尸扫描是什么,请参考我的这篇博客 实验环境: kali(攻击者) 192.168.0.103 metasploitable2(目标主机) 192.168.0.104 win xp sp2( ...
- sklearn机器学习算法--线性模型
线性模型 用于回归的线性模型 线性回归(普通最小二乘法) 岭回归 lasso 用于分类的线性模型 用于多分类的线性模型 1.线性回归 LinearRegression,模型简单,不同调节参数 #2.导 ...
- Mybatis学习笔记(1)
CRUD操作 1.从实体类参数中取值 #{属性名} select * from user where username = #{username} 2.当sql语句只有一个参数且参数类型是基本类型或基 ...