使用Pytorch搭建模型
本来是只用Tenorflow的,但是因为TF有些Numpy特性并不支持,比如对数组使用列表进行切片,所以只能转战Pytorch了(pytorch是支持的)。还好Pytorch比较容易上手,几乎完美复制了Numpy的特性(但还有一些特性不支持),怪不得热度上升得这么快。
模型定义
和TF很像,Pytorch也通过继承父类来搭建模型,同样也是实现两个方法。在TF中是__init__()和call(),在Pytorch中则是__init__()和forward()。功能类似,都分别是初始化模型内部结构和进行推理。其它功能比如计算loss和训练函数,你也可以继承在里面,当然这是可选的。下面搭建一个判别MNIST手写字的Demo,首先给出模型代码:
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn,optim
from torchsummary import summary
from keras.datasets import mnist
from keras.utils import to_categorical
device = torch.device('cuda') #——————1—————— class ModelTest(nn.Module):
def __init__(self,device):
super().__init__()
self.layer1 = nn.Sequential(nn.Flatten(),nn.Linear(28*28,512),nn.ReLU())#——————2——————
self.layer2 = nn.Sequential(nn.Linear(512,512),nn.ReLU())
self.layer3 = nn.Sequential(nn.Linear(512,512),nn.ReLU())
self.layer4 = nn.Sequential(nn.Linear(512,10),nn.Softmax()) self.to(device) #——————3——————
self.opt = optim.SGD(self.parameters(),lr=0.01)#——————4——————
def forward(self,inputs): #——————5——————
x = self.layer1(inputs)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
def get_loss(self,true_labels,predicts):
loss = -true_labels * torch.log(predicts) #——————6——————
loss = torch.mean(loss)
return loss
def train(self,imgs,labels):
predicts = model(imgs)
loss = self.get_loss(labels,predicts)
self.opt.zero_grad()#——————7——————
loss.backward()#——————8——————
self.opt.step()#——————9——————
model = ModelTest(device)
summary(model,(1,28,28),3,device='cuda') #——————10——————
#1:获取设备,以方便后面的模型与变量进行内存迁移,设备名只有两种:'cuda'和'cpu'。通常是在你有GPU的情况下需要这样显式进行设备的设置,从而在需要时,你可以将变量从主存迁移到显存中。如果没有GPU,不获取也没事,pytorch会默认将参数都保存在主存中。
#2:模型中层的定义,可以使用Sequential将想要统一管理的层集中表示为一层。
#3:在初始化中将模型参数迁移到GPU显存中,加速运算,当然你也可以在需要时在外部执行model.to(device)进行迁移。
#4:定义模型的优化器,和TF不同,pytorch需要在定义时就将需要梯度下降的参数传入,也就是其中的self.parameters(),表示当前模型的所有参数。实际上你不用担心定义优化器和模型参数的顺序问题,因为self.parameters()的输出并不是模型参数的实例,而是整个模型参数对象的指针,所以即使你在定义优化器之后又定义了一个层,它依然能优化到。当然优化器你也可以在外部定义,传入model.parameters()即可。这里定义了一个随机梯度下降。
#5:模型的前向传播,和TF的call()类似,定义好model()所执行的就是这个函数。
#6:我将获取loss的函数集成在了模型中,这里计算的是真实标签和预测标签之间的交叉熵。
#7/8/9:在TF中,参数梯度是保存在梯度带中的,而在pytorch中,参数梯度是各自集成在对应的参数中的,可以使用tensor.grad来查看。每次对loss执行backward(),pytorch都会将参与loss计算的所有可训练参数关于loss的梯度叠加进去(直接相加)。所以如果我们没有叠加梯度的意愿的话,那就要在backward()之前先把之前的梯度删除。又因为我们前面已经把待训练的参数都传入了优化器,所以,对优化器使用zero_grad(),就能把所有待训练参数中已存在的梯度都清零。那么梯度叠加什么时候用到呢?比如批量梯度下降,当内存不够直接计算整个批量的梯度时,我们只能将批量分成一部分一部分来计算,每算一个部分得到loss就backward()一次,从而得到整个批量的梯度。梯度计算好后,再执行优化器的step(),优化器根据可训练参数的梯度对其执行一步优化。
#10:使用torchsummary函数显示模型结构。奇怪为什么不把这个继承在torch里面,要重新安装一个torchsummary库。
训练及可视化
接下来使用模型进行训练,因为pytorch自带的MNIST数据集并不好用,所以我使用的是Keras自带的,定义了一个获取数据的生成器。下面是完整的训练及绘图代码(50次迭代记录一次准确率):
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn,optim
from torchsummary import summary
from keras.datasets import mnist
from keras.utils import to_categorical
device = torch.device('cuda') #——————1—————— class ModelTest(nn.Module):
def __init__(self,device):
super().__init__()
self.layer1 = nn.Sequential(nn.Flatten(),nn.Linear(28*28,512),nn.ReLU())#——————2——————
self.layer2 = nn.Sequential(nn.Linear(512,512),nn.ReLU())
self.layer3 = nn.Sequential(nn.Linear(512,512),nn.ReLU())
self.layer4 = nn.Sequential(nn.Linear(512,10),nn.Softmax()) self.to(device) #——————3——————
self.opt = optim.SGD(self.parameters(),lr=0.01)#——————4——————
def forward(self,inputs): #——————5——————
x = self.layer1(inputs)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x
def get_loss(self,true_labels,predicts):
loss = -true_labels * torch.log(predicts) #——————6——————
loss = torch.mean(loss)
return loss
def train(self,imgs,labels):
predicts = model(imgs)
loss = self.get_loss(labels,predicts)
self.opt.zero_grad()#——————7——————
loss.backward()#——————8——————
self.opt.step()#——————9——————
def get_data(device,is_train = True, batch = 1024, num = 10000):
train_data,test_data = mnist.load_data()
if is_train:
imgs,labels = train_data
else:
imgs,labels = test_data
imgs = (imgs/255*2-1)[:,np.newaxis,...]
labels = to_categorical(labels,10)
imgs = torch.tensor(imgs,dtype=torch.float32).to(device)
labels = torch.tensor(labels,dtype=torch.float32).to(device)
i = 0
while(True):
i += batch
if i > num:
i = batch
yield imgs[i-batch:i],labels[i-batch:i]
train_dg = get_data(device, True,batch=4096,num=60000)
test_dg = get_data(device, False,batch=5000,num=10000) model = ModelTest(device)
summary(model,(1,28,28),11,device='cuda')
ACCs = []
import time
start = time.time()
for j in range(20000):
#训练
imgs,labels = next(train_dg)
model.train(imgs,labels) #验证
img,label = next(test_dg)
predicts = model(img)
acc = 1 - torch.count_nonzero(torch.argmax(predicts,axis=1) - torch.argmax(label,axis=1))/label.shape[0]
if j % 50 == 0:
t = time.time() - start
start = time.time()
ACCs.append(acc.cpu().numpy())
print(j,t,'ACC: ',acc)
#绘图
x = np.linspace(0,len(ACCs),len(ACCs))
plt.plot(x,ACCs)
准确率变化图如下:
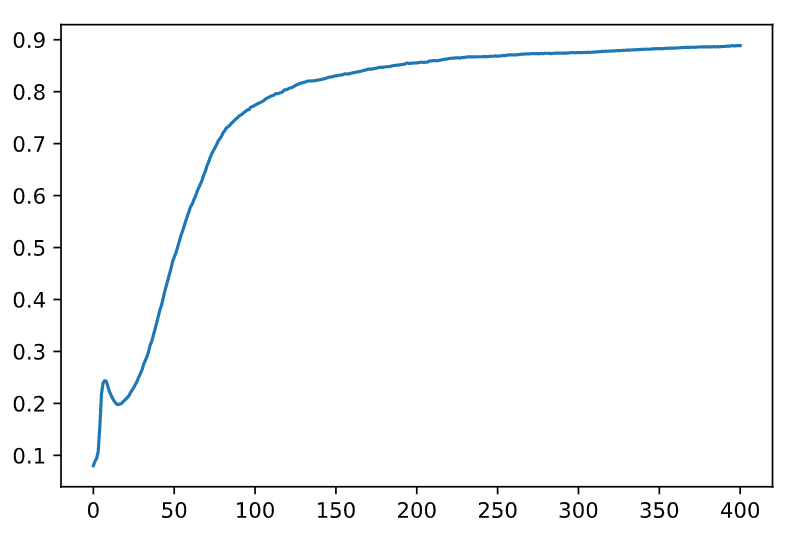
注意事项
需要注意的是,pytorch的tensor基于numpy的array,它们是共享内存的。也就是说,如果你把tensor直接插入一个列表,当你修改这个tensor时,列表中的这个tensor也会被修改;更容易被忽略的是,即使你用tensor.detach.numpy(),先将tensor转换为array类型,再插入列表,当你修改原本的tensor时,列表中的这个array也依然会被修改。所以如果我们只是想保存tensor的值而不是整个对象,就要使用np.array(tensor)将tensor的值复制出来。
使用Pytorch搭建模型的更多相关文章
- [炼丹术]使用Pytorch搭建模型的步骤及教程
使用Pytorch搭建模型的步骤及教程 我们知道,模型有一个特定的生命周期,了解这个为数据集建模和理解 PyTorch API 提供了指导方向.我们可以根据生命周期的每一个步骤进行设计和优化,同时更加 ...
- 目标检测-基于Pytorch实现Yolov3(1)- 搭建模型
原文地址:https://www.cnblogs.com/jacklu/p/9853599.html 本人前段时间在T厂做了目标检测的项目,对一些目标检测框架也有了一定理解.其中Yolov3速度非常快 ...
- 一文弄懂pytorch搭建网络流程+多分类评价指标
讲在前面,本来想通过一个简单的多层感知机实验一下不同的优化方法的,结果写着写着就先研究起评价指标来了,之前也写过一篇:https://www.cnblogs.com/xiximayou/p/13700 ...
- Pytorch线性规划模型 学习笔记(一)
Pytorch线性规划模型 学习笔记(一) Pytorch视频学习资料参考:<PyTorch深度学习实践>完结合集 Pytorch搭建神经网络的四大部分 1. 准备数据 Prepare d ...
- pytorch搭建简单网络
pytorch搭建一个简单神经网络 import torch import torch.nn as nn # 定义数据 # x:输入数据 # y:标签 x = torch.Tensor([[0.2, ...
- PyTorch保存模型与加载模型+Finetune预训练模型使用
Pytorch 保存模型与加载模型 PyTorch之保存加载模型 参数初始化参 数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了da ...
- python日记:用pytorch搭建一个简单的神经网络
最近在学习pytorch框架,给大家分享一个最最最最基本的用pytorch搭建神经网络并且训练的方法.本人是第一次写这种分享文章,希望对初学pytorch的朋友有所帮助! 一.任务 首先说下我们要搭建 ...
- TensorFlow搭建模型方式总结
引言 TensorFlow提供了多种API,使得入门者和专家可以根据自己的需求选择不同的API搭建模型. 基于Keras Sequential API搭建模型 Sequential适用于线性堆叠的方式 ...
- 奉献pytorch 搭建 CNN 卷积神经网络训练图像识别的模型,配合numpy 和matplotlib 一起使用调用 cuda GPU进行加速训练
1.Torch构建简单的模型 # coding:utf-8 import torch class Net(torch.nn.Module): def __init__(self,img_rgb=3,i ...
随机推荐
- 一文读懂MySQL的索引结构及查询优化
回顾前文: 一文学会MySQL的explain工具 (同时再次强调,这几篇关于MySQL的探究都是基于5.7版本,相关总结与结论不一定适用于其他版本) MySQL官方文档中(https://dev.m ...
- Spring Cloud Alibaba生态探索:Dubbo、Nacos及Sentinel的完美结合
@ 目录 背景 一.项目框架 1.1 采用IDEA和Maven多模块进行项目搭建 1.2 模块管理及版本管理 二.微服务公共接口 2.1 定义一个公共接口Api 2.2 pom.xml 2.3 Goo ...
- Redis中的订阅模式
redis中的客户端可以订阅一个自定义的频道,接受来自该频道的消息 订阅 订阅指定频道-SUBSCRIBE SUBSCRIBE channel [channel2]... SUBSCRIBE 频道名 ...
- 如何使用 C# 中的 ValueTask
在 C# 中利用 ValueTask 避免从异步方法返回 Task 对象时分配 翻译自 Joydip Kanjilal 2020年7月6日 的文章 <How to use ValueTask i ...
- python类,魔术方法等学习&&部分ssti常见操作知识点复习加深
python类学习&&部分ssti常见操作知识点复习加深 在做ssti的模块注入的时候经常觉得自己python基础的薄弱,来学习一下,其实还是要多练习多背. 在python中所有类默认 ...
- React 服务端渲染方案完美的解决方案
最近在开发一个服务端渲染工具,通过一篇小文大致介绍下服务端渲染,和服务端渲染的方式方法.在此文后面有两中服务端渲染方式的构思,根据你对服务端渲染的利弊权衡,你会选择哪一种服务端渲染方式呢? 什么是服务 ...
- 秋天的第一份“干货” I Referer 防盗链,为什么少了个字母 R?
Referer 为什么叫 Referer?它代表什么意思?在诸多防盗链竞争中它有什么优势? 今天,在聊 Referer 防盗链之前,先来聊聊我们在现实生活中常常碰到的推荐人(Referrer)信息. ...
- Python_快速安装第三方库-pip
如何快速安装第三方库? 通过python 豆瓣园源https://pypi.douban.com/simple/进行安装,利用国内网速 如何安装? pip -i install https://pyp ...
- 交互式甘特图组件VARCHART XGantt 如何在活动中标注非工作间隔
甘特图从1998年的第一个商用版本开始就致力于计划编制和项目管理方面控件的研究和开发,经过20多年的积累和沉淀,目前可为软件开发商和最终用户提供最顶级的计划编制和项目管理的控件产品,帮助用户快速的整合 ...
- 实验一 C运行环境与最简单的程序设计
实验一: #include<stdio.h> int main() { int a1,a2; int sum; a1 =123; a2 = 456; sum = a1+ ...