hadoop单机环境搭建
[在此处输入文章标题]
Hadoop单机搭建
1、 工具准备
1) Hadoop Linux安装包
2) VMware虚拟机
3) Java Linux安装包
4) Window 电脑一台
2、 开始配置
1) 启动Linux虚拟机,这里使用的是CentOS 6.7版本

2) 首先配置虚拟机网络环境
Ø 配置Windows网络环境
1、 打开VMware,编辑—虚拟网络编辑器
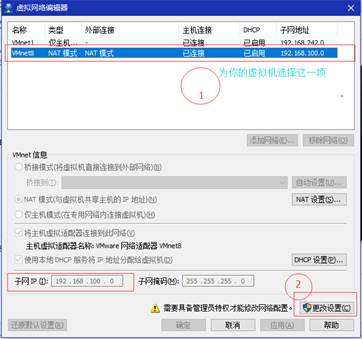
2、 修改子网IP为192.168.100.0
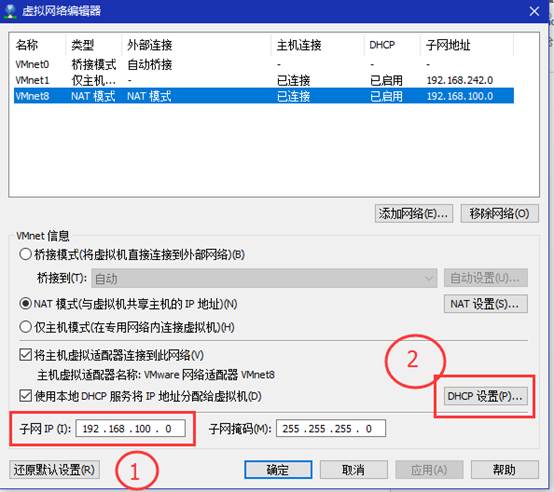
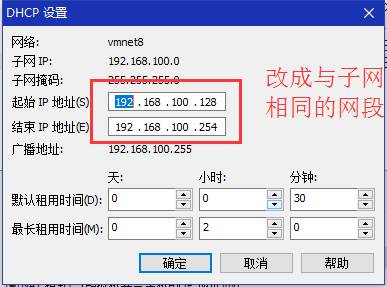
3、 继续修改子网详细配置
4、Windows网络环境配置完成
Ø 配置Linux网络环境
1、 配置Linux网络环境,这里使用CentOS6.7桌面,右键网络连接,编辑网络
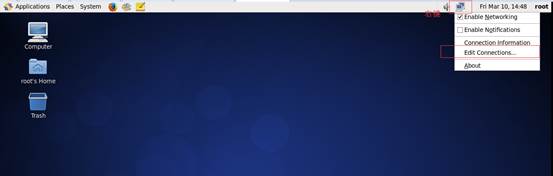
2、 编辑网络
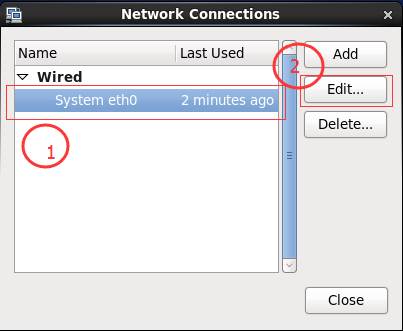
3、 edit,设置网卡
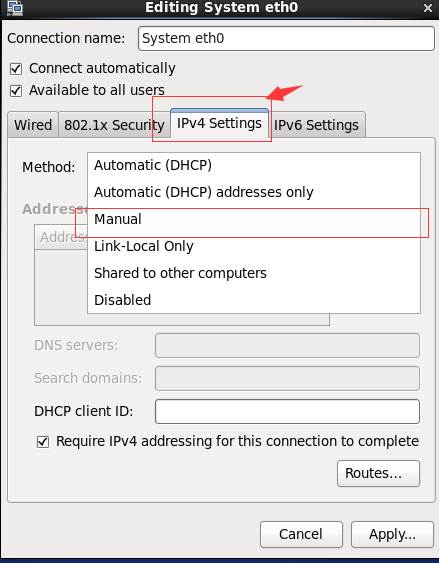
4、 Ipv4 Setting,Method选择Manual

5、 Add添加一个
输入
Address:192.168.100.101
Network:255.255.255.0
Gateway:192.168.100.1
DNS:119.29.29.29,182.254.116.116

6、 点击 Apply... 接下来设置Linux hosts文件
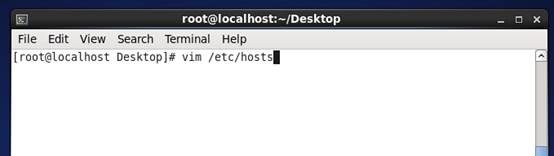
7、 右键Linux桌面,Open in Terminal

8、 Linux终端打开,输入 vim /etc/hosts
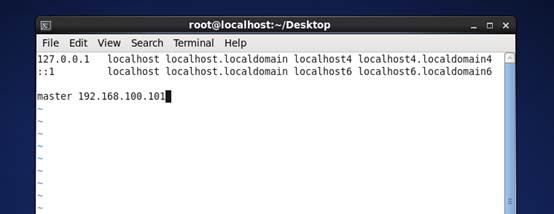
9、 打开hosts文件,添加记录 master 192.168.100.101
10、 保存退出,在终端输入 vim /etc/sysconfig/network
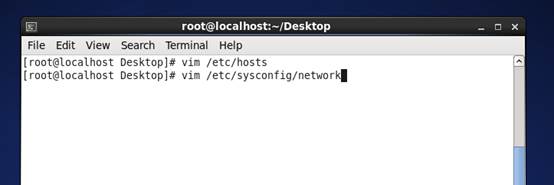
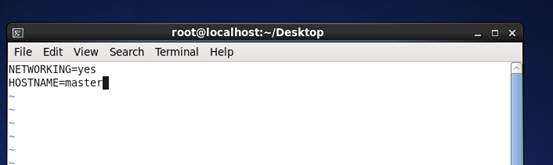
11、 修改network文件 HOSTNAME=master
12、 接下来,关闭Linux防火墙,并从自启项中取消启动
关闭防火墙命令:service iptables stop
取消自启/关闭自启:chkconfig iptables off
查看防火墙状态:service iptables status
查看防火墙的开机状态:chkconfig --list | grep iptables

13、 保存退出,Linux网络修改完成。输入 init 0 重启Linux
3) 接下来,安装jdk
a) 将jdk安装包拷贝到Linux /opt/soft 下(我这里用目录/opt/soft,可以选择其他任意目录)这里用的jdk为8u112版本
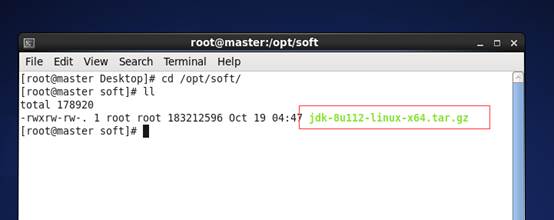
b) 输入命令 tar –zxvf jdk-8u112-linux-x64.tar.gz –C /opt/ 将jdk解压到opt目录下


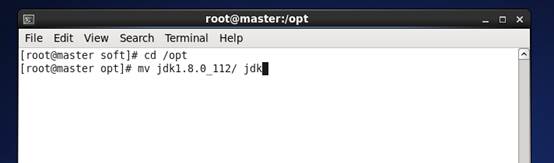
c) *修改jdk解压后的目录为jdk
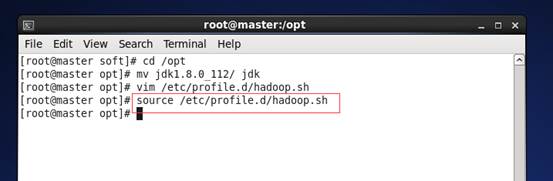
命令:cd /opt
mv jdk1.8.0_112/ jdk
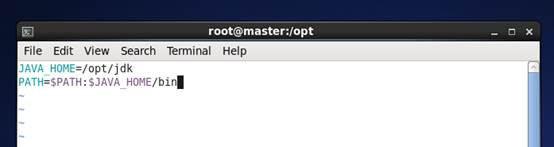
d) 添加jdk路径到path路径中
命令:
vim /etc/profile.d/hadoop.sh
添加
JAVA_HOME=/opt/jdk
PATH=$PATH:$JAVA_HOME/bin
e) 保存退出,输入命令 source /etc/profile.d/hadoop.sh,使配饰生效
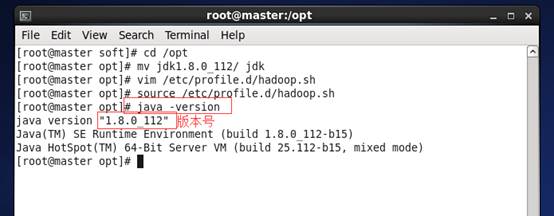
f) 输入 java –version 检验是否成功
4) 安装Hadoop
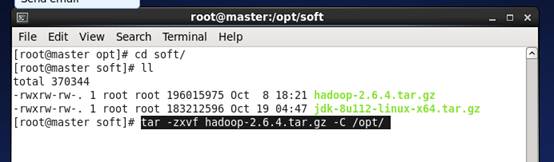
a) 将Hadoop安装包拷贝到 /opt/soft/ 下,我这里用的是2.6.4版本

b) 解压Hadoop安装包到/opt下, tar -zxvf hadoop-2.6.4.tar.gz -C /opt/

c) 修改解压后的目录名为hadoop

d) 添加Hadoop目录到path路径
命令:
vim /etc/profile.d/hadoop.sh
添加两行:
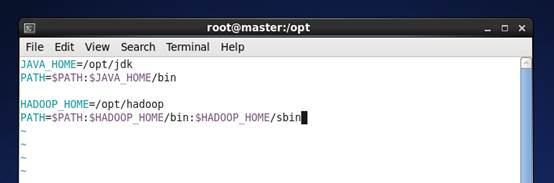
HADOOP_HOME=/opt/hadoop
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
e) 修改hadoop配置文件(配置文件目录 $HADOOP_HOME/etc/hadoop/)
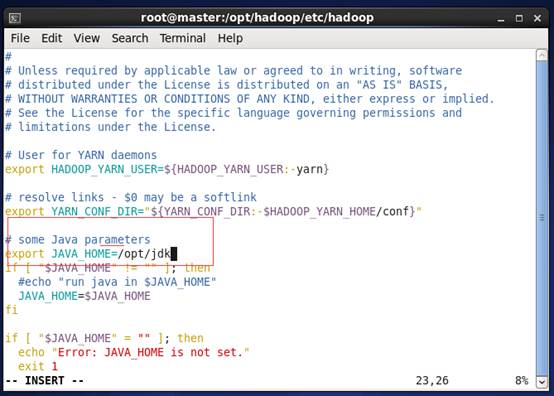
i. 修改hadoop-env.sh文件 export JAVA_HOME=/opt/jdk

ii. 修改yarn-env.sh 文件 export JAVA_HOME=/opt/jdk
iii. 修改hdfs-site.xml文件
1. <configuration>
2. <property>
3. <name>dfs.namenode.name.dir</name>
4. <value>file:///opt/hadoop-repo/name</value>
5. </property>
6. <property>
7. <name>dfs.datanode.data.dir</name>
8. <value>file:///opt/hadoop-repo/data</value>
9. </property>
10. <property>
11. <name>dfs.namenode.checkpoint.dir</name>
12. <value>file:///opt/hadoop-repo/secondary</value>
13. </property>
14. <!-- secondaryName http地址 -->
15. <property>
16. <name>dfs.namenode.secondary.http-address</name>
17. <value>master:9001</value>
18. </property>
19. <!-- 数据备份数量-->
20. <property>
21. <name>dfs.replication</name>
22. <value>1</value>
23. </property>
24. <!-- 运行通过web访问hdfs-->
25. <property>
26. <name>dfs.webhdfs.enabled</name>
27. <value>true</value>
28. </property>
29. <!-- 剔除权限控制-->
30. <property>
31. <name>dfs.permissions</name>
32. <value>false</value>
33. </property>
34. </configuration>
iv. 修改core-site.xml文件
1. <configuration>
2. <property>
3. <name>fs.defaultFS</name>
4. <value>hdfs://master:9000</value>
5. </property>
6. <property>
7. <name>hadoop.tmp.dir</name>
8. <value>file:///opt/hadoop-repo/tmp</value>
9. </property>
10. </configuration>
v. 复制一份mapred-site.xml.template 文件并修改为mapred-site.xml,修改其内容
1. <configuration>
2. <property>
3. <name>mapreduce.framework.name</name>
4. <value>yarn</value>
5. </property>
6. <!-- 历史job的访问地址-->
7. <property>
8. <name>mapreduce.jobhistory.address</name>
9. <value>master:10020</value>
10. </property>
11. <!-- 历史job的访问web地址-->
12. <property>
13. <name>mapreduce.jobhistory.webapp.address</name>
14. <value>master:19888</value>
15. </property>
16. <property>
17. <name>mapreduce.map.log.level</name>
18. <value>INFO</value>
19. </property>
20. <property>
21. <name>mapreduce.reduce.log.level</name>
22. <value>INFO</value>
23. </property>
24. </configuration>
vi. 修改yarn-site.xml文件
1. <configuration>
2. <property>
3. <name>yarn.nodemanager.aux-services</name>
4. <value>mapreduce_shuffle</value>
5. </property>
6. <property>
7. <name>yarn.resourcemanager.hostname</name>
8. <value>master</value>
9. </property>
10. <property>
11. <name>yarn.resourcemanager.address</name>
12. <value>master:8032</value>
13. </property>
14. <property>
15. <name>yarn.resourcemanager.scheduler.address</name>
16. <value>master:8030</value>
17. </property>
18. <property>
19. <name>yarn.resourcemanager.resource-tracker.address</name>
20. <value>master:8031</value>
21. </property>
22. <property>
23. <name>yarn.resourcemanager.admin.address</name>
24. <value>master:8033</value>
25. </property>
26. <property>
27. <name>yarn.resourcemanager.webapp.address</name>
28. <value>master:8088</value>
29. </property>
30. <property>
31. <name>yarn.log-aggregation-enable</name>
32. <value>true</value>
33. </property>
34. </configuration>
f) 创建hadoop数据储存目录
i. NameNode 数据存放目录: /opt/hadoop-repo/name
ii. SecondaryNameNode 数据存放目录: /opt/hadoop-repo/secondary
iii. DataNode 数据存放目录: /opt/hadoop-repo/data
iv. 临时数据存放目录: /opt/hadoop-repo/tmp
5) 至此单机版hadoop配置完成
6) 单机版hadoop的测试
a) 格式化hadoop文件系统
hdfs namenode -format
b) 启动hadoop
start-all.sh
////
启动成功之后,通过java命令jps(java process status)会出现5个进程:
NameNode
SecondaryNameNode
DataNode
ResourceManager
NodeManager
c) 验证
在浏览器中输入http://master:50070
欢迎来访 http://zy107.cn
hadoop单机环境搭建的更多相关文章
- Hadoop —— 单机环境搭建
一.前置条件 Hadoop的运行依赖JDK,需要预先安装,安装步骤见: Linux下JDK的安装 二.配置免密登录 Hadoop组件之间需要基于SSH进行通讯. 2.1 配置映射 配置ip地址和主机名 ...
- 攻城狮在路上(陆)-- hadoop单机环境搭建(一)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86 ...
- Hadoop单机环境搭建整体流程
1. Ubuntu环境安装和基本配置 本例程中在MAC上安装使用的虚拟机Ubuntu系统(64位,desktop): 基本配置 考虑到以后涉及到hadoop的应用便于权限的管理,特别地创建一个ha ...
- [转载] Hadoop和Hive单机环境搭建
转载自http://blog.csdn.net/yfkiss/article/details/7715476和http://blog.csdn.net/yfkiss/article/details/7 ...
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- Hadoop单机Hadoop测试环境搭建
Hadoop单机Hadoop测试环境搭建: 1. 安装jdk,并配置环境变量,配置ssh免密码登录 2. 下载安装包hadoop-2.7.3.tar.gz 3. 配置/etc/hosts 127.0. ...
- Hadoop之环境搭建
初学Hadoop之环境搭建 阅读目录 1.安装CentOS7 2.安装JDK1.7.0 3.安装Hadoop2.6.0 4.SSH无密码登陆 本文仅作为学习笔记,供大家初学Hadoop时学习参考. ...
- Hadoop生产环境搭建(含HA、Federation)
Hadoop生产环境搭建 1. 将安装包hadoop-2.x.x.tar.gz存放到某一目录下,并解压. 2. 修改解压后的目录中的文件夹etc/hadoop下的配置文件(若文件不存在,自己创建.) ...
- Hadoop 系列(四)—— Hadoop 开发环境搭建
一.前置条件 Hadoop 的运行依赖 JDK,需要预先安装,安装步骤见: Linux 下 JDK 的安装 二.配置免密登录 Hadoop 组件之间需要基于 SSH 进行通讯. 2.1 配置映射 配置 ...
随机推荐
- [原创]HBase学习笔记(1)-安装和部署
HBase安装和部署 使用的HBase版本是1.2.4 1.安装步骤(默认hdfs已安装好) # 下载并解压安装包 cd tools/ tar -zxf hbase-1.2.4-bin.tar.gz ...
- 二、Fragment+RadioButton实现底部导航栏
在App中经常看到这样的tab底部导航栏 那么这种效果是如何实现,实现的方式有很多种,最常见的就是使用Fragment+RadioButton去实现.下面我们来写一个例子 首先我们先在activi ...
- 初步认识Thymeleaf:简单表达式和标签。(一)
本文只适用于不会Java对HTML语言有基础的程序员们,是浏览了各大博客后收集整理,重新编辑的一篇文章,希望能对大家有所帮助. 对于Thymeleaf,网上特别官方的解释无非就是:网站或者独立应用程序 ...
- Struts(五)之OGNL、contextMap
一.OGNL 1.1.定义 OGNL是Object-Graph Navigation Language的缩写,它是一个单独的开源项目. Struts2框架使用OGNL作为默认的表达式语言.它是一种功能 ...
- React文档翻译系列(二)Hello World
这是React文档翻译系列的第二篇,前一篇介绍了如何安装react,本篇主要介绍react的知识体系,掌握了基本的知识体系,才能更好的学习React. Hello World 开始React最简单的方 ...
- Oracle常见错误集锦
1.ORA-12560:TNS:协议适配器错误 OracleService<SID>服务没有启动 2. ORA-12541:TNS:无监听程序 Oracle<ORACLE_HOME& ...
- 嵌入javascript脚本的位置
JavaScript脚本可以放在HTML文档任何需要的位置.一般来说,可以在<head>与</head>.<body>与</body>标记对之间按需要放 ...
- donet体系结构
一.C#与.NET的关系 1.粗略地説,.net是一种在Windows平台上的编程架构----一种API.2.C#编译器专门用于.net,这表示用C#编写的所有代码总是使用.NET Framework ...
- 课堂博客-----TreeView+++++XML形成博客
什么是XML? 解析:XML:Extensible Markup Language(可扩展标记语言) HTML:HyperLink Text Markup Language(超文本标记语言) xml ...
- DataReader和DataSet区别
可以使用DataReader类的对象或DataSet类的对象从数据库读取数据,但它们是有区别的,归纳起来大致有以下几条: 1. DataReader是数据管理提供者类,而DataSet是一 ...