从一篇ICLR'2017被拒论文谈起:行走在GAN的Latent Space
同步自我的知乎专栏文章:https://zhuanlan.zhihu.com/p/32135185
import numpy
from matplotlib import pyplot def dist_o2l(p1, p2):
# distance from origin to the line defined by (p1, p2)
p12 = p2 - p1
u12 = p12 / numpy.linalg.norm(p12)
l_pp = numpy.dot(-p1, u12)
pp = l_pp*u12 + p1
return numpy.linalg.norm(pp) dim = 100
N = 100000 rvs = []
dists2l = []
for i in range(N):
u = numpy.random.randn(dim)
v = numpy.random.randn(dim)
rvs.extend([u, v])
dists2l.append(dist_o2l(u, v)) dists = [numpy.linalg.norm(x) for x in rvs] print('Distances to samples, mean: {}, std: {}'.format(numpy.mean(dists), numpy.std(dists)))
print('Distances to lines, mean: {}, std: {}'.format(numpy.mean(dists2l), numpy.std(dists2l))) fig, (ax0, ax1) = pyplot.subplots(ncols=2, figsize=(11, 5))
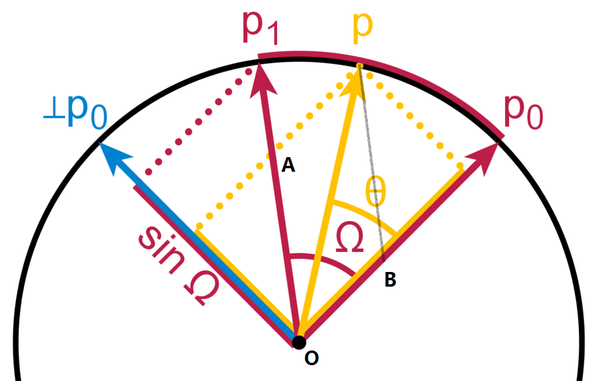
ax0.hist(dists, 100, normed=1, color='g')
ax1.hist(dists2l, 100, normed=1, color='b')
pyplot.show()
结果如下:













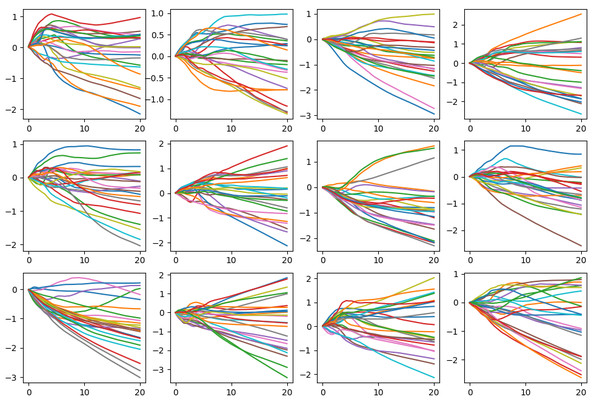



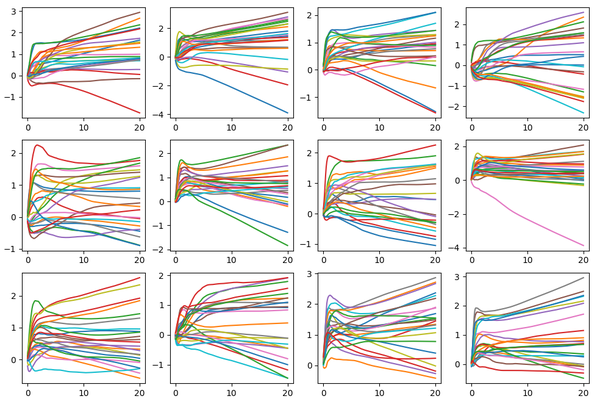
from __future__ import print_function
import argparse
import os
import numpy
from scipy.stats import chi
import torch.utils.data
from torch.autograd import Variable
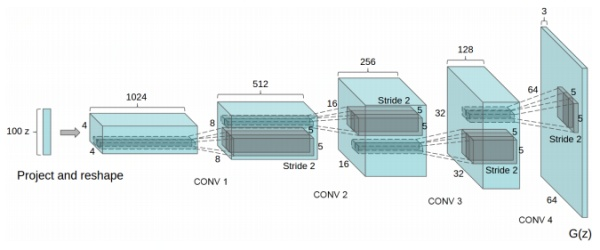
from networks import NetG
from PIL import Image parser = argparse.ArgumentParser()
parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
parser.add_argument('--niter', type=int, default=10, help='how many paths')
parser.add_argument('--n_steps', type=int, default=23, help='steps to walk')
parser.add_argument('--ngf', type=int, default=64)
parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
parser.add_argument('--netG', default='netG_epoch_49.pth', help="trained params for G") opt = parser.parse_args()
output_dir = 'gcircle-walk'
os.system('mkdir -p {}'.format(output_dir))
print(opt) ngpu = int(opt.ngpu)
nz = int(opt.nz)
ngf = int(opt.ngf)
nc = 3 netG = NetG(ngf, nz, nc, ngpu)
netG.load_state_dict(torch.load(opt.netG, map_location=lambda storage, loc: storage))
netG.eval()
print(netG) for j in range(opt.niter):
# step 1
r = chi.rvs(df=100) # step 2
u = numpy.random.normal(0, 1, nz)
w = numpy.random.normal(0, 1, nz)
u /= numpy.linalg.norm(u)
w /= numpy.linalg.norm(w) v = w - numpy.dot(u, w) * u
v /= numpy.linalg.norm(v) ndimgs = []
for i in range(opt.n_steps):
t = float(i) / float(opt.n_steps)
# step 3
z = numpy.cos(t * 2 * numpy.pi) * u + numpy.sin(t * 2 * numpy.pi) * v
z *= r noise_t = z.reshape((1, nz, 1, 1))
noise_t = torch.FloatTensor(noise_t)
noisev = Variable(noise_t)
fake = netG(noisev)
timg = fake[0]
timg = timg.data timg.add_(1).div_(2)
ndimg = timg.mul(255).clamp(0, 255).byte().permute(1, 2, 0).numpy()
ndimgs.append(ndimg) print('exporting {} ...'.format(j))
ndimg = numpy.hstack(ndimgs) im = Image.fromarray(ndimg)
filename = os.sep.join([output_dir, 'gc-{:0>6d}.png'.format(j)])
im.save(filename)
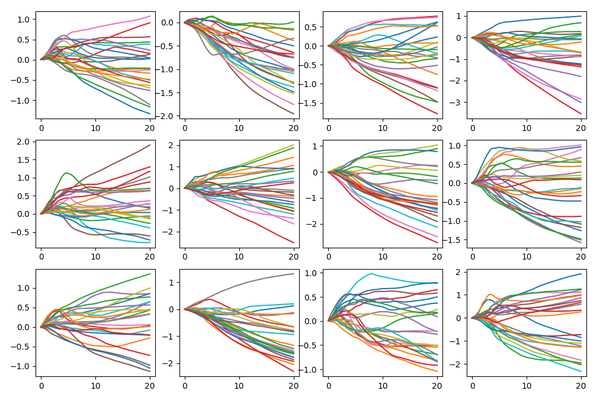
结果如下:








从一篇ICLR'2017被拒论文谈起:行走在GAN的Latent Space的更多相关文章
- (zhuan) 126 篇殿堂级深度学习论文分类整理 从入门到应用
126 篇殿堂级深度学习论文分类整理 从入门到应用 | 干货 雷锋网 作者: 三川 2017-03-02 18:40:00 查看源网址 阅读数:66 如果你有非常大的决心从事深度学习,又不想在这一行打 ...
- Steve Lin:如何撰写一篇优秀的SIGGRAPH论文
Lin:如何撰写一篇优秀的SIGGRAPH论文" title="Steve Lin:如何撰写一篇优秀的SIGGRAPH论文"> 英文原版 PPT下载:http:// ...
- 复现ICCV 2017经典论文—PyraNet
. 过去几年发表于各大 AI 顶会论文提出的 400 多种算法中,公开算法代码的仅占 6%,其中三分之一的论文作者分享了测试数据,约 54% 的分享包含“伪代码”.这是今年 AAAI 会议上一个严峻的 ...
- ACM TOMM 2017最佳论文:让AI接手繁杂专业的图文排版设计工作
编者按:你是否曾经为如何创作和编辑一篇图文并茂.排版精美的文章而烦恼?或是为缺乏艺术灵感和设计思路而痛苦?AI技术能否在艺术设计中帮助到我们?今天我们为大家介绍的这篇论文,“Automatic Gen ...
- 微软的一篇ctr预估的论文:Web-Scale Bayesian Click-Through Rate Prediction for Sponsored Search Advertising in Microsoft’s Bing Search Engine。
周末看了一下这篇论文,觉得挺难的,后来想想是ICML的论文,也就明白为什么了. 先简单记录下来,以后会继续添加内容. 主要参考了论文Web-Scale Bayesian Click-Through R ...
- Steve Lin:如何撰写一篇优秀的SIGGRAPH论文
英文原版 PPT下载:http://vdisk.weibo.com/s/z7VKRh2i3R4YO 一篇优秀的论文应该是这样的 广大的研究同仁介绍了这篇论文所包含的重要想法和所获得的结果 在论文中描 ...
- 国内首篇云厂商 Serverless 论文入选全球顶会:突发流量下,如何加速容器启动?
作者 | 王骜 来源 | Serverless 公众号 导读 USENIX ATC (USENIX Annual Technical Conference) 学术会议是计算机系统领域的顶级会议,入 ...
- 【深度学习 论文篇 01-1 】AlexNet论文翻译
前言:本文是我对照原论文逐字逐句翻译而来,英文水平有限,不影响阅读即可.翻译论文的确能很大程度加深我们对文章的理解,但太过耗时,不建议采用.我翻译的另一个目的就是想重拾英文,所以就硬着头皮啃了.本文只 ...
- MetaQNN : 与Google同场竞技,MIT提出基于Q-Learning的神经网络搜索 | ICLR 2017
论文提出MetaQNN,基于Q-Learning的神经网络架构搜索,将优化视觉缩小到单层上,相对于Google Brain的NAS方法着眼与整个网络进行优化,虽然准确率差了2-3%,但搜索过程要简单地 ...
随机推荐
- 一:MySQL数据库的性能的影响分析及其优化
MySQL数据库的性能的影响分析及其优化 MySQL数据库的性能的影响 一. 服务器的硬件的限制 二. 服务器所使用的操作系统 三. 服务器的所配置的参数设置不同 四. 数据库存储引擎的选择 五. 数 ...
- [转载] Quartz作业调度框架
转载自http://yangpanwww.iteye.com/blog/797563 Quartz 是一个开源的作业调度框架,它完全由 Java 写成,并设计用于 J2SE 和 J2EE 应用中.它提 ...
- [转]结合HierarchyViewer和APK文件反编译获得APP元素id值
背景: 最近在使用Robotium进行Android自动化测试.遇到了一个问题:我需要获得一个View的id(int型数值).此前我在http://maider.blog.sohu.com/25544 ...
- P1879 [USACO06NOV]玉米田Corn Fields
题目描述 Farmer John has purchased a lush new rectangular pasture composed of M by N (1 ≤ M ≤ 12; 1 ≤ N ...
- Unity3D高性能战争迷雾实现
效果图 先上效果图吧,这是为了吸引到你们的ヽ(。◕‿◕。)ノ゚ 战争迷雾效果演示图 战争调试界面演示图 由于是gif录制,为了压缩图片,帧率有点低,实际运行时,参数调整好是不会像这样一卡一顿的. 战争 ...
- 关于SQLServer数据库中字段值为NULL,取出来该字段放在DataTable中,判断datatable中该字段值是否为NULL的三种方法
1. DataTable dt; //假设字段为name, dt已经保存了数据dt.rows[0]["name"] == ...
- SQL Server 的常见约束
1.主键约束------我是最常见的哦(PRIMARY KEY) 限制:不能为空,数据唯一,一个表中只有一个 方法: 建表时直接在列类型后面添加 如: CREATE TABLE stuDB ( S ...
- 如何管理Session(防止恶意共享账号)——理论篇
目录 知识要求 背景 技术原理 如何管理Session remember me的问题 附录 知识要求 有一定的WEB后端开发基础,熟悉Session的用法,以及与Redis.Database的配合 本 ...
- 登山(Climb)
题目: Rocky山脉有n个山峰,一字排开,从西向东依次编号为1, 2, 3, --, n.每个山峰的高度都是不一样的.编号为i的山峰高度为hi. 小修从西往东登山.每到一座山峰,她就回头观望自己走 ...
- 使用Angular Router导航基础
名称 简介 Routes 路由配置,保存着那个URL对应着哪个组件,以及在哪个RouterOulet中展示组件. RouterOutlet 在HTML中标记路由内容呈现位置的占位符指令. Router ...