java‘小秘密’系列(三)---HashMap
java‘小秘密’系列(三)---HashMap
java基础系列
- java‘小秘密’系列(一)---String、StringBuffer、StringBuilder
- java‘小秘密’系列(二)---Integer
- java‘小秘密’系列(三)---HashMap
基本概念
- 节点:
Node<Key,Value>,存放key和value
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;V value;Node<K,V> next;}
- 键值对数组:
Node<K,V>[] table - 加载因子
- 容量 :Node数组的长度
- 大小:hashmap存放的Node的数目
- 阈值:容量*加载因子
工作原理
- 创建一个长度为2的次幂的node数组
- put的时候,计算key的hash值,将hash值与长度-1进行与运算
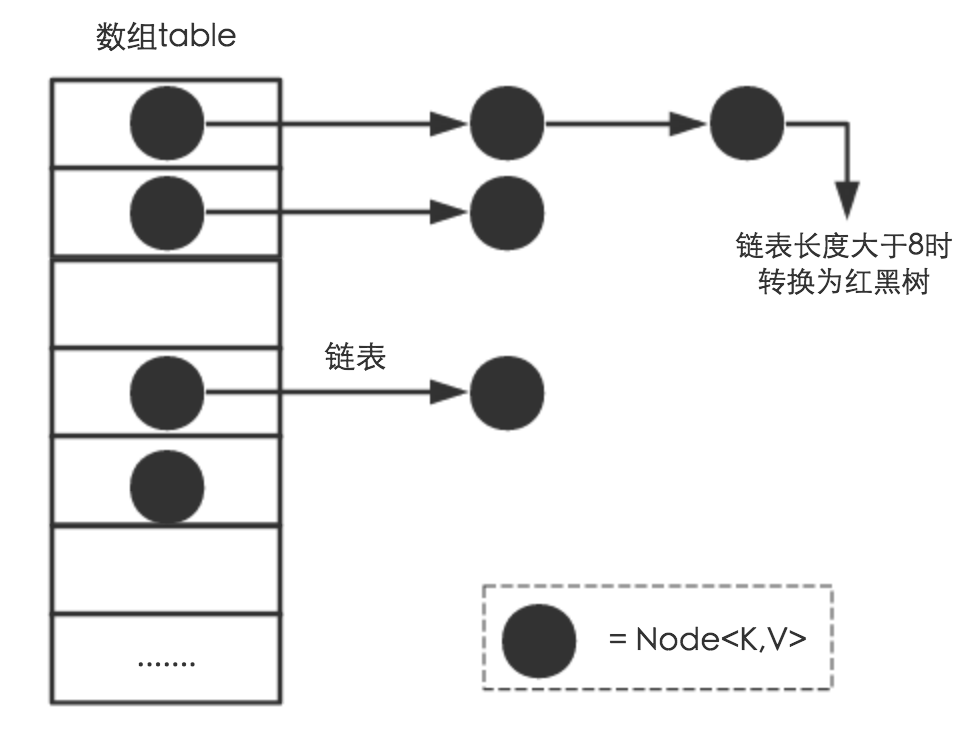
- 如果数组该下标的位置为空,直接存放,如果不为空,判断节点是否为树节点,如果是的话按红黑树的方式存入,否则按照链表的形式存入
- 当hashmap的节点数目大于阈值的时候,将会重新构造hashmap,而这种操作是费时的操作,所以建议初始化一个合适的容量
域
- 默认容量,2的四次方
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
- 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
- node 数组
transient Node<K,V>[] table;
- 键值对数目,不是table的长度
/*** The number of key-value mappings contained in this map.*/transient int size;
- 阈值
/*** The next size value at which to resize (capacity * load factor).** @serial*///阈值int threshold;
- 加载因子
/*** The load factor for the hash table.** @serial*///加载因子final float loadFactor;
构造方法
- 传入初始容量和加载因子
public HashMap(int initialCapacity, float loadFactor) {if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;this.threshold = tableSizeFor(initialCapacity);}
- 传入初始容量,使用默认的加载因子
public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}
- 无参数,默认容量和加载因子
/*** Constructs an empty <tt>HashMap</tt> with the default initial capacity* (16) and the default load factor (0.75).*/public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted}
)
- 容量必须是2的n次方,当你传入的参数不符合条件,会有方法找到一个大于这个参数的最小的2的n次方数(比如大于6的最小2的n次幂是8),
put方法
public V put(K key, V value) {return putVal(hash(key), key, value, false, true);}final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i;if ((tab = table) == null || (n = tab.length) == 0)n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);else {Node<K,V> e; K k;if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))e = p;else if (p instanceof TreeNode)e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else {for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) {p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1sttreeifyBin(tab, hash);break;}if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}if (e != null) { // existing mapping for keyV oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value;afterNodeAccess(e);return oldValue;}}++modCount;if (++size > threshold)resize();afterNodeInsertion(evict);return null;}
- 直接用伪代码表示
put(){index=[hash(key)&(captity-1)]----下标的最大值为captity-1,进行与运算后最终的结果小于等于最大下标if(table[index])==null)直接添加nodeelse{if(p是treenode){直接将节点添加到红黑树}else{如果不是红黑树是链表if(p的键值==key)覆盖valueelse{遍历链表if(有对应的key){覆盖value}else{添加到链表if(链表长度>8){将链表转化为红黑树}}}}if(大小大于阈值){容量加倍,重新构造}}}
get方法
public V get(Object key) {Node<K,V> e;return (e = getNode(hash(key), key)) == null ? null : e.value;}final Node<K,V> getNode(int hash, Object key) {Node<K,V>[] tab; Node<K,V> first, e; int n; K k;if ((tab = table) != null && (n = tab.length) > 0 &&(first = tab[(n - 1) & hash]) != null) {//如果链表的第一个节点是的键和要查找的键相等,那么返回该nodeif (first.hash == hash && // always check first node((k = first.key) == key || (key != null && key.equals(k))))return first;//如果不是的,看该节点是不是树节点,是的话,用树的方法查找节点,如果不是的按链表的方式查找if ((e = first.next) != null) {if (first instanceof TreeNode)return ((TreeNode<K,V>)first).getTreeNode(hash, key);do {if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;} while ((e = e.next) != null);}}return null;}
为什么长度设置为2的n次方
if ((p = tab[i = (n - 1) & hash]) == null)tab[i] = newNode(hash, key, value, null);
- 存放node到table数组的时候,他的下标是通过(n-1)&hash计算出来的(数组长度-1 和 key的hash的值相与,最后结果小于等于长度-1),n为table的长度。
- 显然这种效果和hash%n-1的效果很类似,而实际上,当长度为2的n次幂的时候,(n-1)&hash的效果就是hash%n,而前者是位运算,速度会快很多
- 长度为2的n次幂的时候,n-1的二进制全是1,那么这样可以减少碰撞的机率,比如如果有一位是0,那么如果与的是1或者0,结果是一样的,那么这样就加大了碰撞的机率
负载因子
- 负载因子较大,说明阈值较大,也就意味着可能发生更多的冲突
- 负载因子较小,说明阈值较小,也就意味着可能会更少的冲突
- 发生冲突的时候,会降低hashmap的查找速度,所以当要求更少的内存的时候可以增加负载因子,当要求更高的查找速度的时候,可以减少负载因子。
- 默认的参数是平衡的选择,所以不建议修改
我觉得分享是一种精神,分享是我的乐趣所在,不是说我觉得我讲得一定是对的,我讲得可能很多是不对的,但是我希望我讲的东西是我人生的体验和思考,是给很多人反思,也许给你一秒钟、半秒钟,哪怕说一句话有点道理,引发自己内心的感触,这就是我最大的价值。(这是我喜欢的一句话,也是我写博客的初衷)
作者:jiajun 出处: http://www.cnblogs.com/-new/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。如果觉得还有帮助的话,可以点一下右下角的【推荐】,希望能够持续的为大家带来好的技术文章!想跟我一起进步么?那就【关注】我吧。
java‘小秘密’系列(三)---HashMap的更多相关文章
- java基础系列(三)---HashMap
java基础系列(三)---HashMap java基础系列 java基础系列(一)---String.StringBuffer.StringBuilder java基础系列(二)---Integer ...
- java基础解析系列(三)---HashMap
java基础解析系列(三)---HashMap java基础解析系列 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)-- ...
- java‘小秘密’系列(二)---Integer
java'小秘密'系列(二)---Integer 前言:本系列的主题是平时容易疏忽的知识点,只有基础扎实,在编码的时候才能更注重规范和性能,在出现bug的时候,才能处理更加从容. 目录 java'小秘 ...
- Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- Java 集合系列 11 hashmap 和 hashtable 的区别
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- java集合系列之HashMap源码
java集合系列之HashMap源码 HashMap的源码可真不好消化!!! 首先简单介绍一下HashMap集合的特点.HashMap存放键值对,键值对封装在Node(代码如下,比较简单,不再介绍)节 ...
- java多线程系列(三)---等待通知机制
等待通知机制 前言:本系列将从零开始讲解java多线程相关的技术,内容参考于<java多线程核心技术>与<java并发编程实战>等相关资料,希望站在巨人的肩膀上,再通过我的理解 ...
- Java爬虫系列三:使用Jsoup解析HTML
在上一篇随笔<Java爬虫系列二:使用HttpClient抓取页面HTML>中介绍了怎么使用HttpClient进行爬虫的第一步--抓取页面html,今天接着来看下爬虫的第二步--解析抓取 ...
- Java集合系列之HashMap
概要 第1部分 HashMap介绍 HashMap简介 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射.HashMap 继承于AbstractMap,实现了Map.Clo ...
随机推荐
- Hibernate一对多实例
本文向大家介绍Hibernate实例一对多的情况,可能好多人还不了解Hibernate实例一对多,没有关系,下面通过一个实例来帮助您理解Hibernate实例一对多,希望本文能教会你更多东西. 先看由 ...
- (转)Java中equals和==的区别
java中的数据类型,可分为两类: 1.基本数据类型,也称原始数据类型.byte,short,char,int,long,float,double,boolean 他们之间的比较,应用双等号( ...
- JavaScript系统学习小结——Object类型、Array类型
今天学习JavaSript中引用变量中的Object类型和Array类型: 1. Js中大多数引用类型值都是Object类型的实例,Object类型在应用程序中存储和传输数据时,是非常理想的选择: 创 ...
- 【CSS】div父容器根据子容器大小自适应
Div即父容器不根据内容自动调节高度,我们看下面的代码: <div id="main"> <div id="content"></ ...
- Node.js 入门:Express + Mongoose 基础使用
前言 Express 是基于 Node.js 平台的 web 应用开发框架,在学习了 Node.js 的基础知识后,可以使用 Express 框架来搭建一个 web 应用,实现对数据库的增删查改. 数 ...
- 41. leetcode 53. Maximum Subarray
53. Maximum Subarray Find the contiguous subarray within an array (containing at least one number) w ...
- Linux系统C语言socket tcp套接字编程
1.套接字的地址结构: typedef uint32_t in_addr_t; //32位无符号整数,用于表示网络地址 struct in_addr{ in_addr_t s_addr; //32位 ...
- Base:一种 Acid 的替代方案
原文链接: BASE: An Acid Alternative 数据库 ACID,都不陌生:原子性.一致性.隔离性和持久性,这在单台服务器就能搞定的时代,很容易实现,但是到了现在,面对如此庞大的访问量 ...
- 微信小程序开发之微信支付
微信支付是小程序开发中很重要的一个环节,下面会结合实战进行分析总结 环境准备 https服务器 微信小程序只支持https请求,因此需要配置https的单向认证服务(请参考 另一篇文章https受信证 ...
- 关于Wifi室内定位应用中的一些问题:
公司目前在办公室内布设了一套室内定位的实验环境,用的是华为路由器,采用的算法是基于信号强度的RSSI算法.公司目前希望能使用这套设备得到无线网络覆盖范围下的所有移动设备(对应每个人)的MAC地址,同时 ...