Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路
首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号信息和被关注信息的关注列表,爬取这些用户的信息,通过这种递归的方式从而爬取整个知乎的所有的账户信息。整个过程通过下面两个图表示:

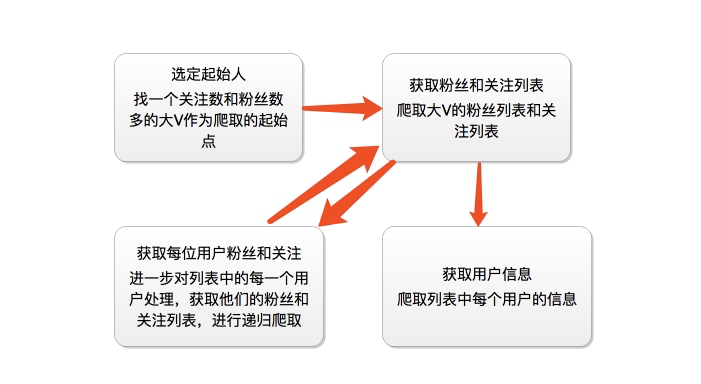
爬虫分析过程
这里我们找的账号地址是:https://www.zhihu.com/people/excited-vczh/answers
我们抓取的大V账号的主要信息是:

其次我们要获取这个账号的关注列表和被关注列表
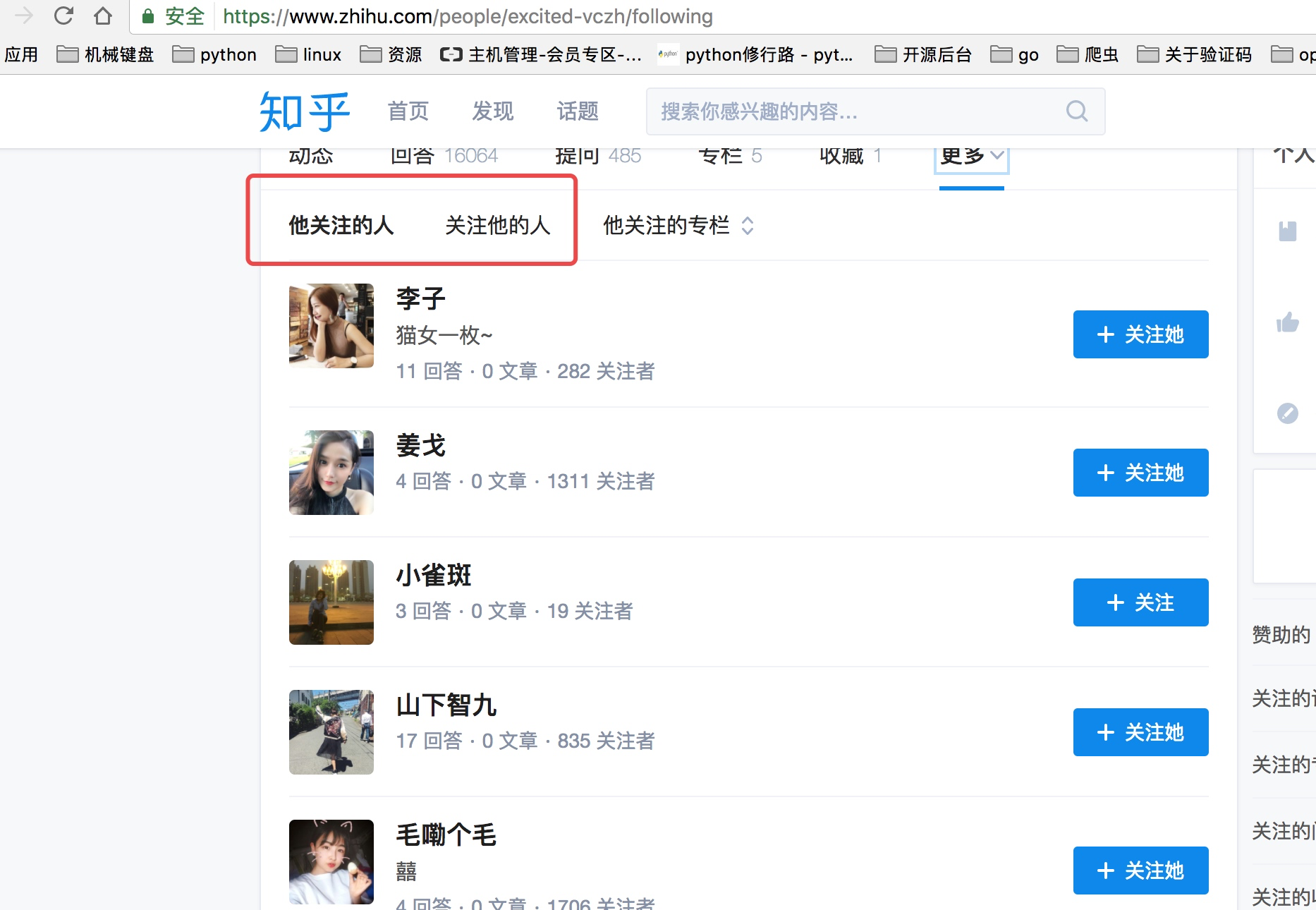
这里我们需要通过抓包分析如果获取这些列表的信息以及用户的个人信息内容
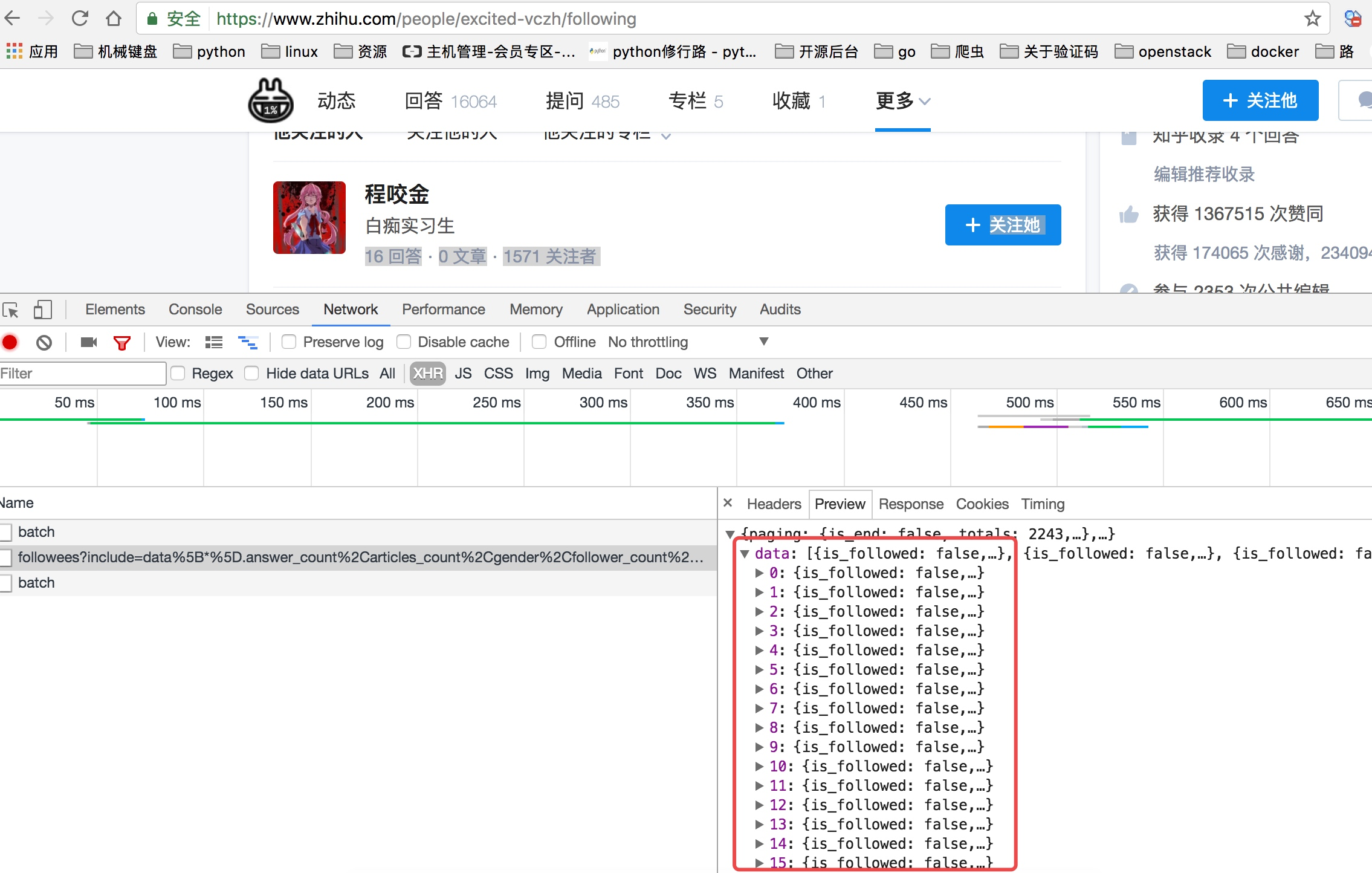
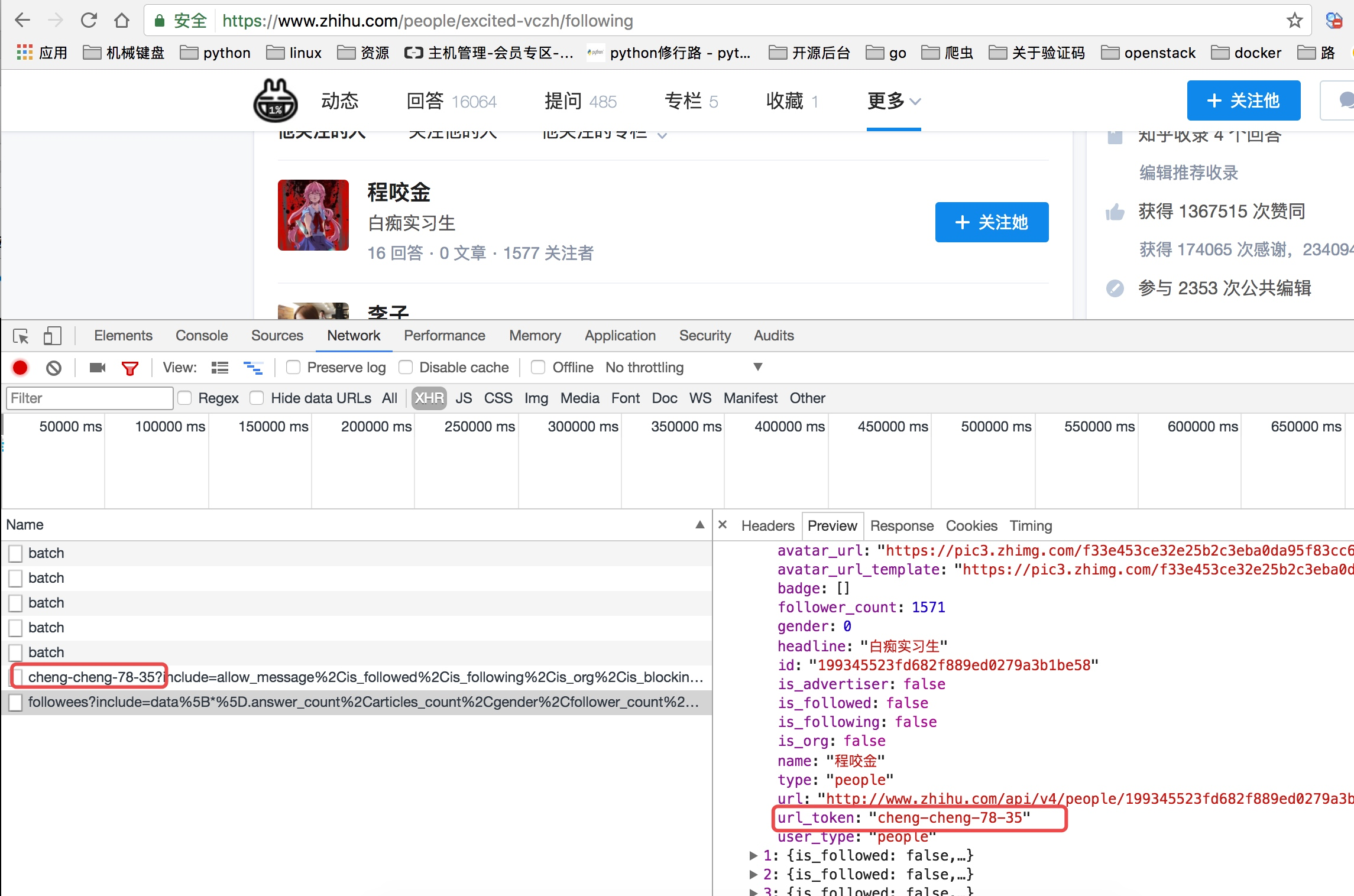
当我们查看他关注人的列表的时候我们可以看到他请求了如下图中的地址,并且我们可以看到返回去的结果是一个json数据,而这里就存着一页关乎的用户信息。


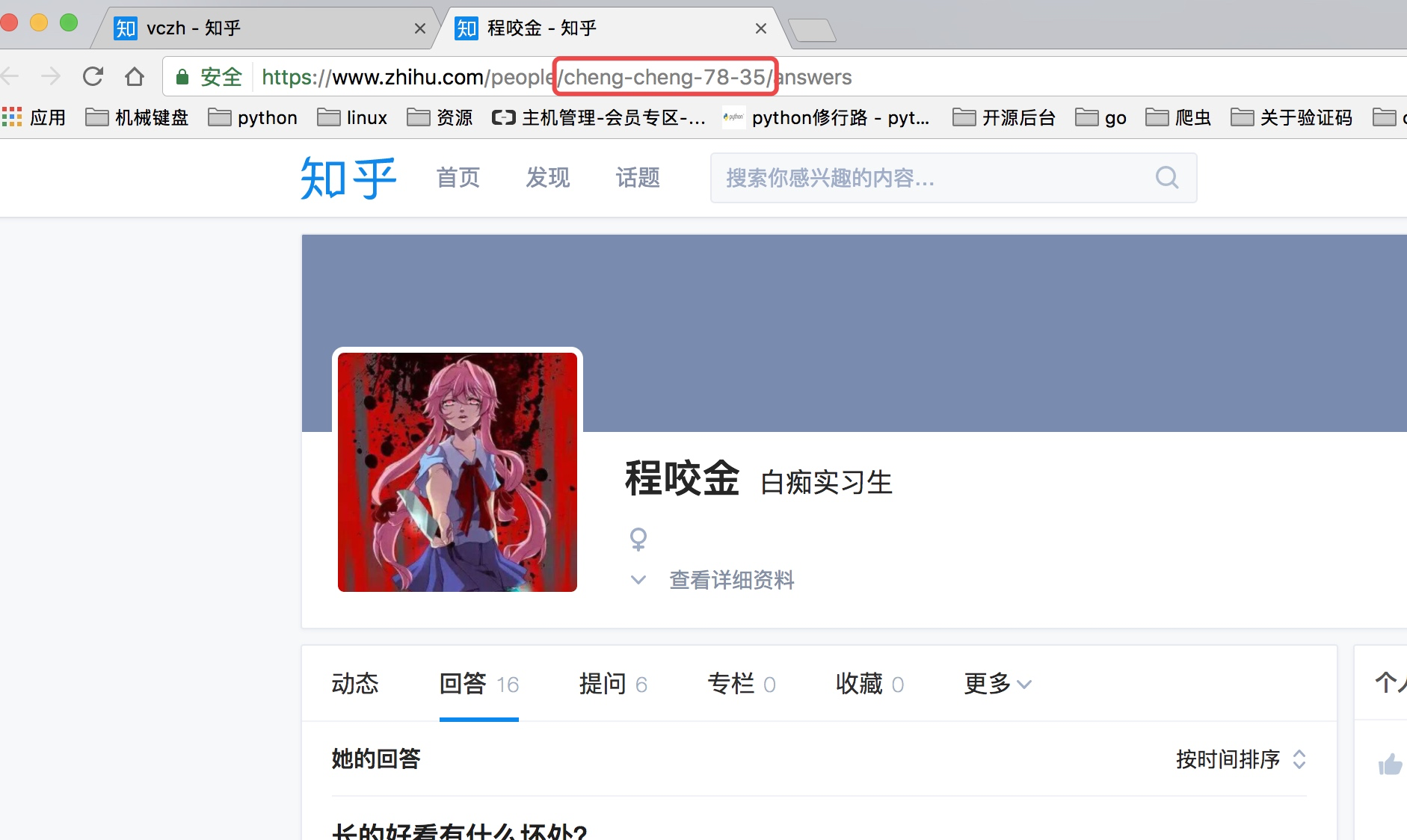
上面虽然可以获取单个用户的个人信息,但是不是特别完整,这个时候我们获取一个人的完整信息地址是当我们将鼠标放到用户名字上面的时候,可以看到发送了一个请求:
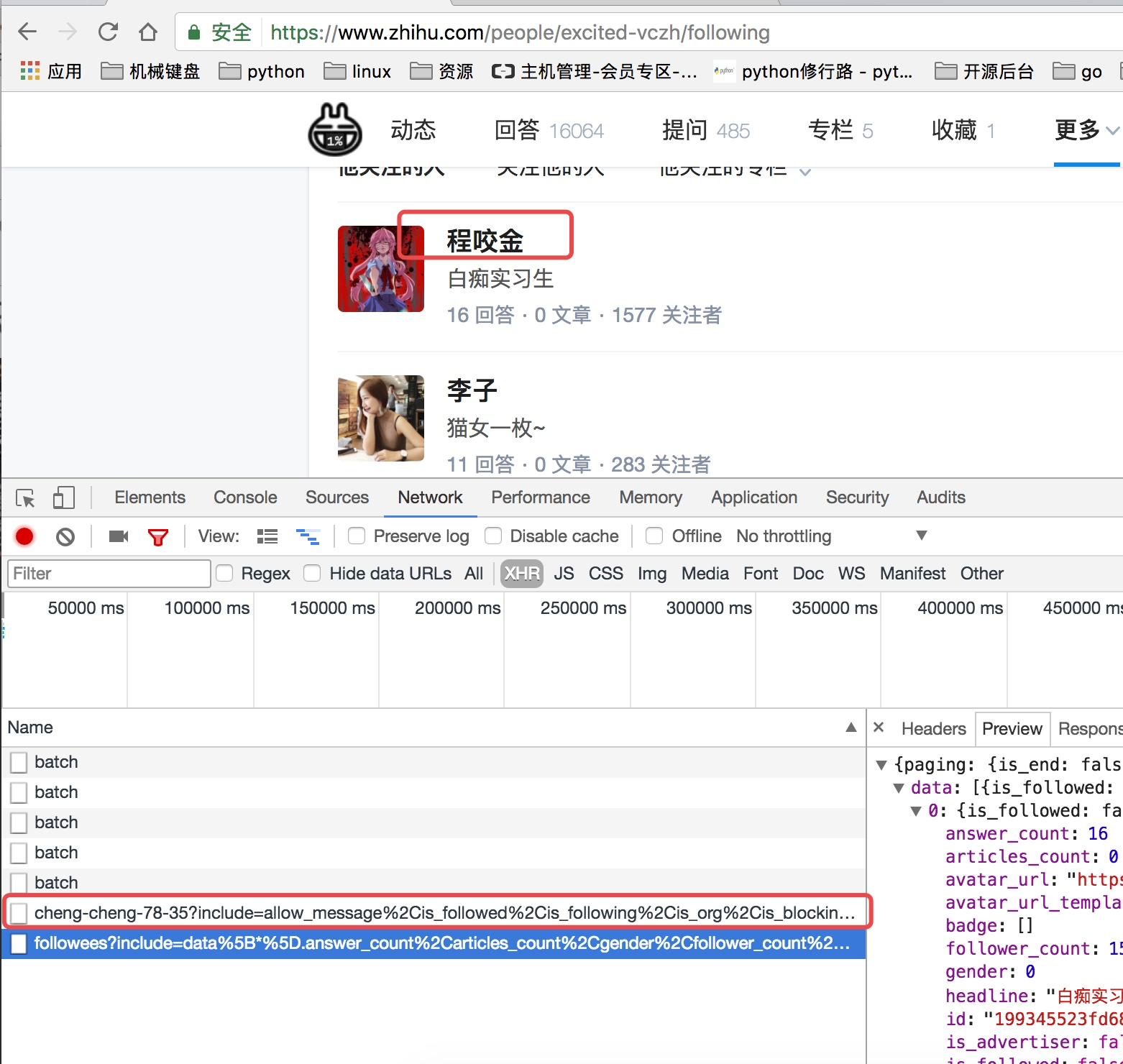
我们可以看这个地址的返回结果可以知道,这个地址请求获取的是用户的详细信息:

通过上面的分析我们知道了以下两个地址:
获取用户关注列表的地址:https://www.zhihu.com/api/v4/members/excited-vczh/followees?include=data%5B*%5D.answer_count%2Carticles_count%2Cgender%2Cfollower_count%2Cis_followed%2Cis_following%2Cbadge%5B%3F(type%3Dbest_answerer)%5D.topics&offset=0&limit=20
这里我们可以从请求的这两个地址里发现一个问题,关于用户信息里的url_token其实就是获取单个用户详细信息的一个凭证也是请求的一个重要参数,并且当我们点开关注人的的链接时发现请求的地址的唯一标识也是这个url_token
创建项目进行再次分析
通过命令创建项目
scrapy startproject zhihu_user
cd zhihu_user
scrapy genspider zhihu www.zhihu.com
直接通过scrapy crawl zhihu启动爬虫会看到如下错误:

这个问题其实是爬取网站的时候经常碰到的问题,大家以后见多了就知道是怎么回事了,是请求头的问题,应该在请求头中加User-Agent,在settings配置文件中有关于请求头的配置默认是被注释的,我们可以打开,并且加上User-Agent,如下:
关于如何获取User-Agent,可以在抓包的请求头中看到也可以在谷歌浏览里输入:chrome://version/ 查看
这样我们就可以正常通过代码访问到知乎了
然后我们可以改写第一次的请求,这个我们前面的scrapy文章关于spiders的时候已经说过如何改写start_request,我们让第一次请求分别请求获取用户列表以及获取用户信息

这个时候我们再次启动爬虫

我们会看到是一个401错误,而解决的方法其实还是请求头的问题,从这里我们也可以看出请求头中包含的很多信息都会影响我们爬取这个网站的信息,所以当我们很多时候直接请求网站都无法访问的时候就可以去看看请求头,看看是不是请求头的哪些信息导致了请求的结果,而这里则是因为如下图所示的参数:
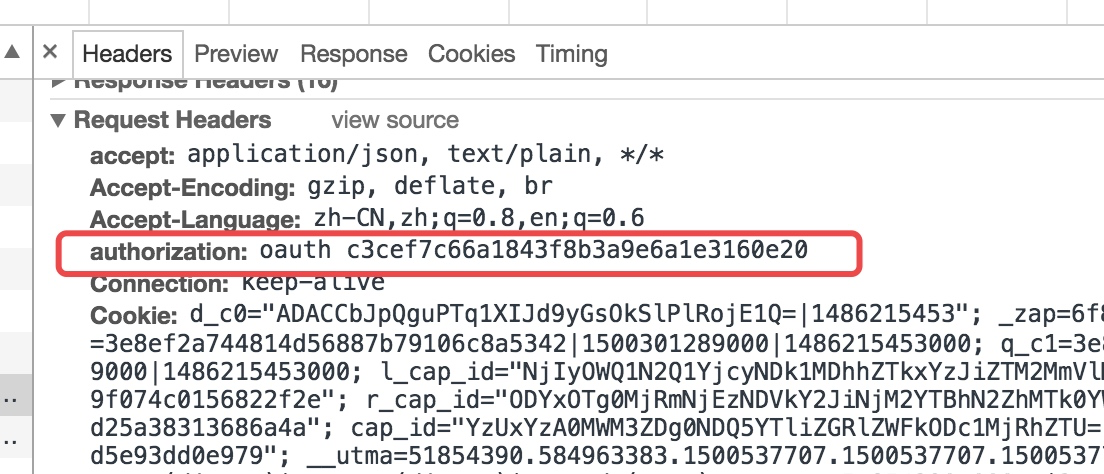
所以我们需要把这个参数同样添加到请求头中:

然后重新启动爬虫,这个时候我们已经可以获取到正常的内容
到此基本的分析可以说是都分析好了,剩下的就是具体代码的实现,在下一篇文张中写具体的实现代码内容!
Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)的更多相关文章
- Python之爬虫(二十) Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python之爬虫(二十一) Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- python爬虫从入门到放弃(八)之 Selenium库的使用
一.什么是Selenium selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- python爬虫从入门到放弃(三)之 Urllib库的基本使用
官方文档地址:https://docs.python.org/3/library/urllib.html 什么是Urllib Urllib是python内置的HTTP请求库包括以下模块urllib.r ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python之爬虫从入门到放弃(十三) Scrapy框架整体的了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
随机推荐
- python 集合相关操作
集合相关操作 集合是一个无序的,不重复的数据组合,它有着两个主要作用:去重以及关系测试. 去重指的是当把一个列表变成了集合,其中重复的内容就自动的被去掉了 关系测试指的是,测试两组数据之间的交集.差集 ...
- [OpenGL]配置GLFW
注:本文可转载,转载请著名出处:http://www.cnblogs.com/collectionne/p/6937644.html.本文还会修改,如果不在博客园(cnblogs)发现本文,建议访问上 ...
- 如何用Python做词云(收藏)
看过之后你有什么感觉?想不想自己做一张出来? 如果你的答案是肯定的,我们就不要拖延了,今天就来一步步从零开始做个词云分析图.当然,做为基础的词云图,肯定比不上刚才那两张信息图酷炫.不过不要紧,好的开始 ...
- 搭建arm交叉工具链
1.将arm-linux-gcc-4.4.3压缩包,拷到home/armtoolchain下,进行压缩. 2.压缩命令:tar -xzvf arm-linux-gcc-4.4.3.tgz,解压后得到了 ...
- 写个百万级别full-stack小型协程库——原理介绍
其实说什么百万千万级别都是虚的,下面给出实现原理和测试结果,原理很简单,我就不上图了: 原理:为了简单明了,只支持单线程,每个协程共享一个4K的空间(你可以用堆,用匿名内存映射或者直接开个数组也都是可 ...
- Python的核心数据结构
数据结构 例子 数字 1234,3.1415,3+4j 字符串 'spam'."grace's" 列表 [1,[2,'three'],4] 字典 {'food':'spam','t ...
- ActiveMQ 学习第二弹
经历了昨天的初识 ActiveMQ,正好今天下班有点事耽搁了还没法回家,那就再学习会 ActiveMQ 吧!现在官网的文档没啥好看的了,毕竟是入门学习,太深奥的东西也理解不了.然后看官网上有推荐书籍& ...
- [0] Visual studio 2010 快捷键大全
[窗口快捷键]Ctrl+W,W: 浏览器窗口 Ctrl+W,S: 解决方案管理器 Ctrl+W,C: 类视图 Ctrl+W,E: 错误列表 Ctrl+W,O: 输出视图 trl+W,P: 属性窗口 C ...
- Docker Daemon 参数最佳实践
1. Docker Daemon 配置参数 限制容器之间网络通信 在同一台主机上若不限制容器之间通信,容器之间就会暴露些隐私的信息,所以推荐关闭 docker daemon –icc=false 使用 ...
- PHPCMS v9点击量增加值加大的方法
PHPCMS v9点击量增加值加大的方法 在根目录/api 50行 $views = $r['views'] + 1; 修改数字1即可修改每次刷新页面点击量增加的数值.