奔跑在Docker上的Spark
目录
- 为什么要在Docker上搭建Spark集群
- 网络拓扑
- Docker安装及配置
- ssh安装及配置
- 基础环境安装
- Zookeeper安装及配置
- Hadoop安装及配置
- Spark安装及配置
- 集群部署
- 总结
- 参考资料
1 为什么要在Docker上搭建Spark集群
他:为什么要在Docker上搭建Spark集群啊?
我:因为……我行啊!
MR和Spark都提供了local模式,即在单机上模拟多计算节点来执行任务。但是,像我这等手贱的新手,怎么会满足于“模拟”?很容易想到在单机上运行多个虚拟机作为计算节点,可是考虑到PC的资源有限,即使能将集群运行起来,再做其他的工作已经是超负荷了。Docker是一种相比虚拟机更加轻量级的虚拟化解决方案,所以在Docker上搭建Spark集群具有可行性。
2 网络拓扑
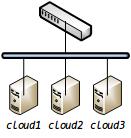
搭建一个有意义的小规模集群,我选择了3台服务器作为Spark计算节点(Worker)。集群中光有计算节点还不够,这3台服务器同时也作为分布式文件系统(HDFS)的数据节点(DataNode)。指定了哪些服务器用来计算,哪些用来存储之后,我们还需要指定来管理计算和存储的主节点。一个简单方案:我们可以让cloud1作为管理计算节点的主节点(Master),同时它也作为管理数据节点的主节点(NameNode)。
很容易看到简单方案不够完美:首先,要是cloud1作为NameNode宕机,整个分布式文件系统则无法工作。此时,我们应当采用基于HA的HDFS方案:由多个NameNode共同管理DataNode,但是只有一个NameNode处于活动(Active)状态,当活动的NameNode无法工作时,则需要其他NameNode候补。这里至少涉及2个关键技术:
- 如何共享NameNode的信息(EditLog)?NameNode存储的信息包括但不限于:数据在各DataNode上如何存储,哪些DataNode是可用的。所以,当活动的NameNode无法工作时,应当将这些信息传递给下一个被选中的NameNode。与其传递,不如所有的NameNode共享这些信息。这些信息将被分布式地存储在JournalNode上。在本集群中,我们使用所有3台服务器都作为JournalNode。cloud1和cloud2作为NameNode。
- 如何确保只有一个NameNode是活动的?当活动的NameNode无法工作时,如何确定下一个活动的Namenode?Zookeeper可以解决这两个问题,在本集群中,3台服务器都作为Zkserver节点。
再者,选用cloud1作为Master来管理计算(standalone)的方式对资源的利用率不比Yarn方式。所以,在本集群中选用cloud1做为ResourceManager,3台服务器都作为NodeManager)。
改进后的集群描述如下:
| 节点 | Zkserver | NameNode | JournalNode | ResourceManager | NodeManager |
Master |
Worker |
| cloud1 | √ | √ | √ | √ | √ | √ | √ |
| cloud2 | √ | √ | √ | × | √ | × | √ |
| cloud3 | √ | × | √ | × | √ | × | √ |
3 Docker安装及配置
Docker有Windows/Mac/Linux版本。起初我处于对Docker的误解选择了Windows版本,Docker的核心程序必须运行在Linux上,故Windows版本的Docker实际上是利用VirtualBox运行着一个精简的Linux,然后在此Linux上运行Docker,最后在Docker上运行安装好应用的镜像。好家伙,盗梦空间!最终,我选择在CentOS上安装Linux版本的Docker。关于Docker,我们需要理解一个重要的概念:容器(Container)。容器是镜像运行的场所,可以在多个容器中运行同一个镜像。
Docker安装好之后,我们启动Docker服务:
1 systemctl start docker.service
我们可以拉一个Ubuntu镜像,基于该镜像我们搭建Spark集群:
1 docker pull ubuntu
下载好镜像到本地后,我们可以查看镜像:
1 docker images
使用run命令,创建一个容器来运行镜像:
1 docker run -it ubuntu
使用ps命令查看容器:
1 docker ps -a
使用commit命令来将容器提交为一个镜像:
1 docker commit <container id|name>
使用tag命令来为一个镜像打标签:
1 docker tag <mirror id> <tag>
使用start命令来启动一个容器:
1 docker start -a <container id|name>
在掌握了以上操作后,在Docker上搭建Spark集群的技术路线如下:

4 ssh安装及配置
试想一下如何启动集群?手动去每个节点启动相应的服务?这显然是不合理的。HDFS,Yarn,Spark都支持单命令启动全部节点。在某个节点上执行的命令是如何发送至其他节点的呢?ssh服务帮助实现这一功能。关于ssh我们需要知道其分为服务端和客户端,服务端默认监听22号端口,客户端可与服务端建立连接,从而实现命令的传输。
docker服务启动后,可以看到宿主机上多了一块虚拟网卡(docker0),在我的机器中为172.17.0.1。启动容器后,容器的IP从172.17.0.2开始分配。我们不妨为集群分配IP地址如下:
| 域名 | IP |
| cloud1 | 172.17.0.2 |
| cloud2 | 172.17.0.3 |
| cloud3 | 172.17.0.4 |
关闭所有容器后,新建一个容器,命名为cloud1:
1 #新建容器时需要指定这个容器的域名以及hosts文件
2 #参数:
3 #name:容器名称
4 #h:域名
5 #add-host:/etc/hosts文件中的域名与IP的映射
6 docker --name cloud1 -h cloud1 --add-host cloud1:172.17.0.2 --add-host cloud2:172.17.0.3 --add-host cloud3:172.17.0.4 -it ubuntu
在容器cloud1中通过apt工具来安装ssh:
1 apt-get install ssh
往~/.bashrc中加入ssh服务启动命令:
1 /usr/sbin/sshd
客户端不能任意地与服务端建立连接,或通过密码,或通过密钥认证。在这里我们使用密钥认证,生成客户端的私钥和公钥:

1 #私钥(~/.ssh/id_rsa)由客户端持有
2 #公钥(~/.ssh/id_rsa.pub)交给服务端
3 #已认证的公钥(~/.ssh/authorized_keys)由服务端持有,只有已认证公钥的客户端才能连接至服务端
4 #参数:
5 #t:加密方式
6 #P:密码
7 ssh-keygen -t rsa -P ""
根据技术路线,由cloud1容器提交的镜像将生成cloud2容器和cloud3容器。要实现cloud1对cloud2和cloud3的ssh密钥认证连接,其实只要实现cloud1对本身的连接就可以了:
1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试是否能连接成功:
1 ssh root@cloud1
5 基础环境安装
Java与Scala版本需要与其他软件的版本相匹配:
| 软件 | 版本 |
| Java | 1.8.0_77 |
| Scala | 2.10.6 |
| Zookeeper | 3.4.8 |
| Hadoop | 2.6.4 |
| Spark | 1.6.1 |
Java与Scala安装包下载后,均解压在/usr目录下。在~/.bashrc中添加环境变量:
1 export JAVA_HOME=/usr/jdk1.8.0_77
2 export PATH=$PATH:$JAVA_HOME/bin
3 export SCALA_HOME=/usr/scala-2.10.6
4 export PATH=$PATH:$SCALA_HOME/bin
6 Zookeeper安装及配置
Zookeeper安装包下载后,解压在/usr目录下。在~/.bashrc中添加环境变量:
1 export ZOOKEEPER_HOME=/usr/zookeeper-3.4.8
2 export PATH=$PATH:$ZOOKEEPER_HOME/bin
生成Zookeeper配置文件:
1 cp /usr/zookeeper-3.4.8/conf/zoo_sample.cfg /usr/zookeeper-3.4.8/conf/zoo.cfg
修改Zookeeper配置文件:
1 #数据存储目录修改为:
2 dataDir=/root/zookeeper/tmp
3 #在最后添加Zkserver配置信息:
4 server.1=cloud1:2888:3888
5 server.2=cloud2:2888:3888
6 server.3=cloud3:2888:
设置当前Zkserver信息:
1 #~/zookeeper/tmp/myid文件中保存的数字代表本机的Zkserver编号
2 #在此设置cloud1为编号为1的Zkserver,之后生成cloud2和cloud3之后还需要分别修改此文件
3 echo 1 > ~/zookeeper/tmp/myid
7 Hadoop安装及配置
Hadoop安装包下载后,解压在/usr目录下。在~/.bashrc中添加环境变量:
1 export HADOOP_HOME=/usr/hadoop-2.6.4
2 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
修改Hadoop启动配置文件(/usr/hadoop-2.6.4/etc/hadoop/hadoop-env.sh):
1 #修改JAVA_HOME
2 export JAVA_HOME=/usr/jdk1.8.0_77
修改核心配置文件(/usr/hadoop-2.6.4/etc/hadoop/core-site.xml):
| 参数 | 说明 |
| fs.defaultFS | 默认的文件系统 |
| hadoop.tmp.dir | 临时文件目录 |
| ha.zookeeper.quorum | Zkserver信息 |
1 <property>
2 <name>fs.defaultFS</name>
3 <value>hdfs://ns1</value>
4 </property>
5 <property>
6 <name>hadoop.tmp.dir</name>
7 <value>/root/hadoop/tmp</value>
8 </property>
9 <property>
10 <name>ha.zookeeper.quorum</name>
11 <value>cloud1:2181,cloud2:2181,cloud3:2181</value>
12 </property>
修改HDFS配置文件(/usr/hadoop-2.6.4/etc/hadoop/hdfs-site.xml):
| 参数 | 说明 |
| dfs.nameservices | 名称服务,在基于HA的HDFS中,用名称服务来表示当前活动的NameNode |
| dfs.ha.namenodes.<nameservie> | 配置名称服务下有哪些NameNode |
| dfs.namenode.rpc-address.<nameservice>.<namenode> | 配置NameNode远程调用地址 |
| dfs.namenode.http-address.<nameservice>.<namenode> | 配置NameNode浏览器访问地址 |
| dfs.namenode.shared.edits.dir | 配置名称服务对应的JournalNode |
| dfs.journalnode.edits.dir | JournalNode存储数据的路径 |
1 <property>
2 <name>dfs.nameservices</name>
3 <value>ns1</value>
4 </property>
5 <property>
6 <name>dfs.ha.namenodes.ns1</name>
7 <value>nn1,nn2</value>
8 </property>
9 <property>
10 <name>dfs.namenode.rpc-address.ns1.nn1</name>
11 <value>cloud1:9000</value>
12 </property>
13 <property>
14 <name>dfs.namenode.http-address.ns1.nn1</name>
15 <value>cloud1:50070</value>
16 </property>
17 <property>
18 <name>dfs.namenode.rpc-address.ns1.nn2</name>
19 <value>cloud2:9000</value>
20 </property>
21 <property>
22 <name>dfs.namenode.http-address.ns1.nn2</name>
23 <value>cloud2:50070</value>
24 </property>
25 <property>
26 <name>dfs.namenode.shared.edits.dir</name>
27 <value>qjournal://cloud1:8485;cloud2:8485;cloud3:8485/ns1</value>
28 </property>
29 <property>
30 <name>dfs.journalnode.edits.dir</name>
31 <value>/root/hadoop/journal</value>
32 </property>
33 <property>
34 <name>dfs.ha.automatic-failover.enabled</name>
35 <value>true</value>
36 </property>
37 <property>
38 <name>dfs.client.failover.proxy.provider.ns1</name>
39 <value>
40 org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
41 </value>
42 </property>
43 <property>
44 <name>dfs.ha.fencing.methods</name>
45 <value>
46 sshfence
47 shell(/bin/true)
48 </value>
49 </property>
50 <property>
51 <name>dfs.ha.fencing.ssh.private-key-files</name>
52 <value>/root/.ssh/id_rsa</value>
53 </property>
54 <property>
55 <name>dfs.ha.fencing.ssh.connect-timeout</name>
56 <value>30000</value>
57 </property>
修改Yarn的配置文件(/usr/hadoop-2.6.4/etc/hadoop/yarn-site.xml):
| 参数 | 说明 |
| yarn.resourcemanager.hostname | RescourceManager的地址,NodeManager的地址在slaves文件中定义 |
1 <property>
2 <name>yarn.resourcemanager.hostname</name>
3 <value>cloud1</value>
4 </property>
5 <property>
6 <name>yarn.nodemanager.aux-services</name>
7 <value>mapreduce_shuffle</value>
8 </property>
修改指定DataNode和NodeManager的配置文件(/usr/hadoop-2.6.4/etc/hadoop/slaves):
1 cloud1
2 cloud2
3 cloud3
8 Spark安装及配置
Spark安装包下载后,解压在/usr目录下。在~/.bashrc中添加环境变量:
1 export SPARK_HOME=/usr/spark-1.6.1-bin-hadoop2.6
2 export PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH
Spark启动配置文件:
1 cp /usr/spark-1.6.1-bin-hadoop2.6/conf/spark-env.sh.template /usr/spark-1.6.1-bin-hadoop2.6/conf/spark-env.sh
修改Spark启动配置文件(/usr/spark-1.6.1-bin-hadoop2.6/conf/spark-env.sh):
| 参数 | 说明 |
| SPARK_MASTER_IP | Master的地址,Worker的地址在slaves文件中定义 |
1 export SPARK_MASTER_IP=cloud1
2 export SPARK_WORKER_MEMORY=128m
3 export JAVA_HOME=/usr/jdk1.8.0_77
4 export SCALA_HOME=/usr/scala-2.10.6
5 export SPARK_HOME=/usr/spark-1.6.1-hadoop2.6
6 export HADOOP_CONF_DIR=/usr/hadoop-2.6.4/etc/hadoop
7 export SPARK_LIBRARY_PATH=$$SPARK_HOME/lib
8 export SCALA_LIBRARY_PATH=$SPARK_LIBRARY_PATH
9 export SPARK_WORKER_CORES=1
10 export SPARK_WORKER_INSTANCES=1
11 export SPARK_MASTER_PORT=
修改指定Worker的配置文件(/usr/spark-1.6.1-bin-hadoop2.6/conf/slaves):
1 cloud1
2 cloud2
3 cloud3
9 集群部署
在宿主机上提交cloud1容器为新的镜像,并打其标签为Spark:
1 #提交cloud1容器,命令返回新镜像的编号
2 docker commit cloud1
3 #为新镜像打标签为Spark
4 docker tag <mirror id> Spark
基于Spark镜像创建cloud2和cloud3容器:
1 docker --name cloud2 -h cloud2 --add-host cloud1:172.17.0.2 --add-host cloud2:172.17.0.3 --add-host cloud3:172.17.0.4 -it Spark
2 docker --name cloud3 -h cloud3 --add-host cloud1:172.17.0.2 --add-host cloud2:172.17.0.3 --add-host cloud3:172.17.0.4 -it Spark
还记得之前提到的cloud2和cloud3的当前Zkserver还未配置吗?分别在cloud2和cloud3容器中修改Zookeeper配置:
1 #在cloud2执行
2 echo 2 > ~/zookeeper/tmp/myid
3 #在cloud3执行
4 echo 3 > ~/zookeeper/tmp/myid
在所有节点启动Zkserver(Zkserver并不是用ssh启动的,呵呵):
1 zkServer.sh start
在所有节点查看Zkserver运行状态:
1 #显示连接不到Zkserver的错误,可稍后查看
2 #Master表示主Zkserver,Follower表示从Zkserver
3 Zkserver.sh status
初始化其中一个NameNode,就选cloud1吧:
1 #格式化zkfc
2 hdfs zkfc -formatZK
3 #格式化NameNode
4 hdfs namenode -format
在cloud1启动HDFS,Yarn,Spark:
1 #启动NameNode,DataNode,zkfc,JournalNode
2 start-dfs.sh
3 #启动ResouceManager,NodeManager
4 start-yarn.sh
5 #启动Master,Worker
6 start-all.sh
使用jps命令查看各节点服务运行情况:
1 jps
还可以登录web管理台来查看运行状况:
| 服务 | 地址 |
| HDFS | cloud1:50070 |
| Yarn | cloud1:8088 |
| Spark | cloud1:8080 |
10 总结
- 环境搭建切不可知其然,但不知其所以然
- 明确自己的需求是什么,不可能一开始就弄懂所有配置项,掌握一个最小的知识集就好
11 参考资料
- 在Docker中从头部署自己的Spark集群
- Docker (软件)
- HDFS-HA的配置-----自动Failover
- Spark:Yarn-cluster和Yarn-client区别与联系
- Installation On CentOS
奔跑在Docker上的Spark的更多相关文章
- 马踏飞燕——奔跑在Docker上的Spark
目录 为什么要在Docker上搭建Spark集群 网络拓扑 Docker安装及配置 ssh安装及配置 基础环境安装 Zookeeper安装及配置 Hadoop安装及配置 Spark安装及配置 集群部署 ...
- 使用docker安装部署Spark集群来训练CNN(含Python实例)
使用docker安装部署Spark集群来训练CNN(含Python实例) http://blog.csdn.net/cyh_24/article/details/49683221 实验室有4台神服务器 ...
- 在阿里云上搭建 Spark 实验平台
在阿里云上搭建 Spark 实验平台 Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程 [传统文化热爱者] 阿里云服务器搭建spark特别坑的地方 阿里云实现Hadoop+Sp ...
- Apache PredictionIO在Docker上的搭建及使用
1.Apache PredictionIO介绍 Apache PredictionIO 是一个孵化中的机器学习服务器,它可以为为开发人员和数据科学家创建任何机器学习任务的预测引擎.官方原文: Apac ...
- 《Spark 官方文档》在Mesos上运行Spark
本文转自:http://ifeve.com/spark-mesos-spark/ 在Mesos上运行Spark Spark可以在由Apache Mesos 管理的硬件集群中运行. 在Mesos集群中使 ...
- 在OSX和Windows版本Docker上运行GUI程序
看到很多人在Docker问题区讨论:如何在OS X和Windows的Docker上运行GUI程序, 随手记录几个参考资料: https://github.com/docker/docker/issue ...
- 使用VS把ASP.NET 5的应用发布到Linux的Docker上
(此文章同时发表在本人微信公众号"dotNET每日精华文章",欢迎右边二维码来关注.) 题记:我相信未来应用程序的部署模式首选一定会是Docker,所以.NET社区的朋友也不应该忽 ...
- cdh 上安装spark on yarn
在cdh 上安装spark on yarn 还是比较简单的,不需要独立安装什么模块或者组件. 安装服务 选择on yarn 模式:上面 Spark 在spark 服务中添加 在yarn 服务中添加 g ...
- Spark学习之在集群上运行Spark
一.简介 Spark 的一大好处就是可以通过增加机器数量并使用集群模式运行,来扩展程序的计算能力.好在编写用于在集群上并行执行的 Spark 应用所使用的 API 跟本地单机模式下的完全一样.也就是说 ...
随机推荐
- Java IO流--练习
1)将若干个Student对象,若干个Teacher对象,写出到d:/0404/a.txt中 2)将该文件中所有Student对象反序列化回来装入List, 所有的Teacher对象反序列化回来转入另 ...
- 从RGB色转为灰度色算法
一.基础 对于彩色转灰度,有一个很著名的心理学公式: Gray = R*0.299 + G*0.587 + B*0.114 二.整数算法 而实际应用时,希望避免低速的浮点运算,所以需要整数算法. 注 ...
- WireShark网络分析就这么简单 读后感
京东618活动,满200减100,果断入手了这本经典的 WireShark教程
- windows7 64bit下mvn命令后提示‘cmd’不是内部或外部命令,也不是可执行程序或批处理文件
首先,开命令提示符,输入如下命令试试echo %M2_HOME% 回车如果显示的路径和安装路径一致说明配置没问题; 那么出现这个问题的原因可能就是路径问题,可能是你安装了某个软件更改了系统映射路径导致 ...
- lvs之 lvs原理架构介绍
一. 概念 lvs的术语: Router:GWIP vs:virtual server,director rs:real server CIP:client IP VIP:virtual server ...
- JAVAEE——spring01:介绍、搭建、概念、配置详解、属性注入和应用到项目
一.spring介绍 1.三层架构中spring位置 2.spring一站式框架 正是因为spring框架性质是属于容器性质的. 容器中装什么对象就有什么功能.所以可以一站式. 不仅不排斥其他框架,还 ...
- VMware-VCSA-6.5安装过程
1.新建虚拟机 2.选择从OVF或OVA文件导入 3.给虚拟机命名,并选择OVF文件. 4.选择虚拟机的存储位置.这里没有配置共享存储宿,这里选择的宿主机的存储. 5.许可协议同意就OK了. 6.部署 ...
- MySQL left join操作中 on与where放置条件的区别
优先级 两者放置相同条件,之所以可能会导致结果集不同,就是因为优先级.on的优先级是高于where的. 1 1 首先明确两个概念: LEFT JOIN 关键字会从左表 (table_name1) 那里 ...
- 【Netty】TCP粘包和拆包
一.前言 前面已经基本上讲解完了Netty的主要内容,现在来学习Netty中的一些可能存在的问题,如TCP粘包和拆包. 二.粘包和拆包 对于TCP协议而言,当底层发送消息和接受消息时,都需要考虑TCP ...
- linux下vim 查找命令
在命令模式下输入/word 这个是查找文件中“word”这个单词,是从文件上面到下面查找?word 这个是查找文件中“word”这个单词,是从文件下上面到面查找