[Bayesian] “我是bayesian我怕谁”系列 - Continuous Latent Variables
打开prml and mlapp发现这部分目录编排有点小不同,但神奇的是章节序号竟然都为“十二”。
prml:pca --> ppca --> fa
mlapp:fa --> pca --> ppca
这背后又有怎样的隐情?不可告人的秘密又会隐藏多久?
基于先来后到原则,走prml路线。
首先,这部分内容,尤其是pca,都是老掉牙且稳定的技术,既然是统计机器学习,这次的目的就是借概率图来缕一遍思路,以及模型间的内在联系。
我们要建立的是一套完整的知识体系,而非“拿来一用,用完就扔”的态度。
有菜鸡问了,为何你总是强调“体系”?
因为我是马刺队球迷。

首先,我希望大家重视prml的第12章开章这段话:
"本章中,我们⾸先介绍标准的、⾮概率的PCA⽅法,然后我们会说明,当求解线性⾼斯潜在变量模型的⼀种特别形式的最⼤似然解时, PCA如何⾃然地产⽣。这种概率形式的表⽰⽅法会带来很多好处,例如在参数估计时可以使⽤EM算法,对混合PCA模型的推广以及主成分的数量可以从数据中⾃动确定的贝叶斯公式。最后,我们简短地讨论潜在变量概念的几个推广,使得潜在变量的概念不局限于线性⾼斯假设。这种推广包括⾮⾼斯潜在变量,它引出了独⽴成分分析( independent conponent analysis)的框架。这种推广还包括潜在变量与观测变量的关系是⾮线性关系的模型。"
因为大部分人都只关心以下这张图,也就是通过“映射”的角度来理解PCA。
然后,因为理解不全面,或者暂且只关心pca,对后面的部分就出现了理解断层。因为体系,波波维奇劝你要“站得高,看得远”。

PCA:
有关pca的内容,网络资源有太多,以下个人链接能增加一点感性认识和相关内容;至于理性认识,除了动手亲自推倒公式,哪怕是抄一遍,也是极好的。
- [Scikit-learn] 4.4 Dimensionality reduction - PCA
- [Scikit-learn] 1.2 Dimensionality reduction - Linear and Quadratic Discriminant Analysis
因为pca+gmm常常是一个组合,先降维,去掉可能useless的信息,再进行gmm聚类。如此,至少能节省后期聚类时的计算资源。
其他没什么想说的,这个组合实践时确实效果蛮好,PCA也算是重要的预处理工具,数据预处理的地位你懂得,特征工程之百试不爽。
PPCA:
冒出一个“屁+PCA”,恩,本来就挺好用,还要加个“P”? —— 初次见面的初次感受。
PCA也可以被视为概率潜在变量模型的最⼤似然解。如何理解?
From: http://www.miketipping.com/papers/met-mppca.pdf【链接中x是隐变量】
第一步:
先验:

似然:【原理见证明1,t = Wx+mu】

后验:
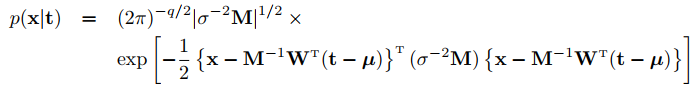
最后,期望就是最优解。贝叶斯三部曲,没啥可说的,但这里有个M,如果假设σ2 = 0, 再带入结果,这不就是PCA麽。

第二步:
解的形式有了,但解中的变量是多少,比如W应该是多少呢?
通过mle获取,也就是获得W的估值。
(1)
联合分布,再积分掉x得t的边缘分布:
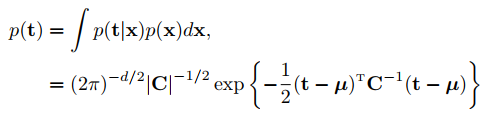
(2)
然后便获取了"t的似然"形式,如下:
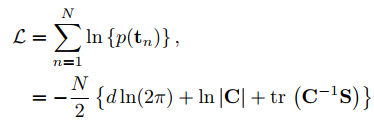
求导解似然方程就不再赘述here,过程详见链接。
答案中就包含了W的估值。读后感就是:一切皆是套路。
证明1
假设z是标准高斯,那么线性组合的每个x也是高斯。
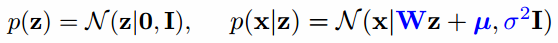

Figure, 证明1
这个证明看似很无聊,让我们思维大胆地扩展一下:
线性组合类似于没激活神经元的神经网络(NN);因为有了激活函数,nn才能解决非线性问题。
但这里对应的貌似不是激活函数,而是概率。概率能否达到非线性的效果?为什么?
与传统的PCA相⽐,会带来一个本人感兴趣的优势就是,可以利用em高效求解。
好比用几何和代数解决同一个问题:用em总比“求解特征向量特征值”要划算的多,而且结果等价。当然还有其他优势,例如处理missing data。
此时,两个问题可能在菜鸡小脑中回荡:
- 不要问我mle方法中怎么涉及到了特征值计算,自己写一下W的估值瞧瞧。
- 感觉似乎都搞完了啊,但怎么又涉及到了em?
读到这里,你如果有同样的疑惑,恭喜。好处便是,你不会感觉这系列文章的思维读来怪异,因为你我的脑回路可能是相通的。

因为mle在高维计算时没啥优势,所以考虑em。
这里看似是放弃了由mle得到的精确值,转而选择em带来的估计值,建议你想想,能提高内力心法。
因为FA就是ppca的方差扩展版本,所以,em的方法在fa中聊一次就好,节能。
FA:
cs229

既然是ppca的扩展,那么,咱就看看扩展ppca会发生什么?
首先,凭什么ppca的“先验”是标准高斯?改一改会如何?
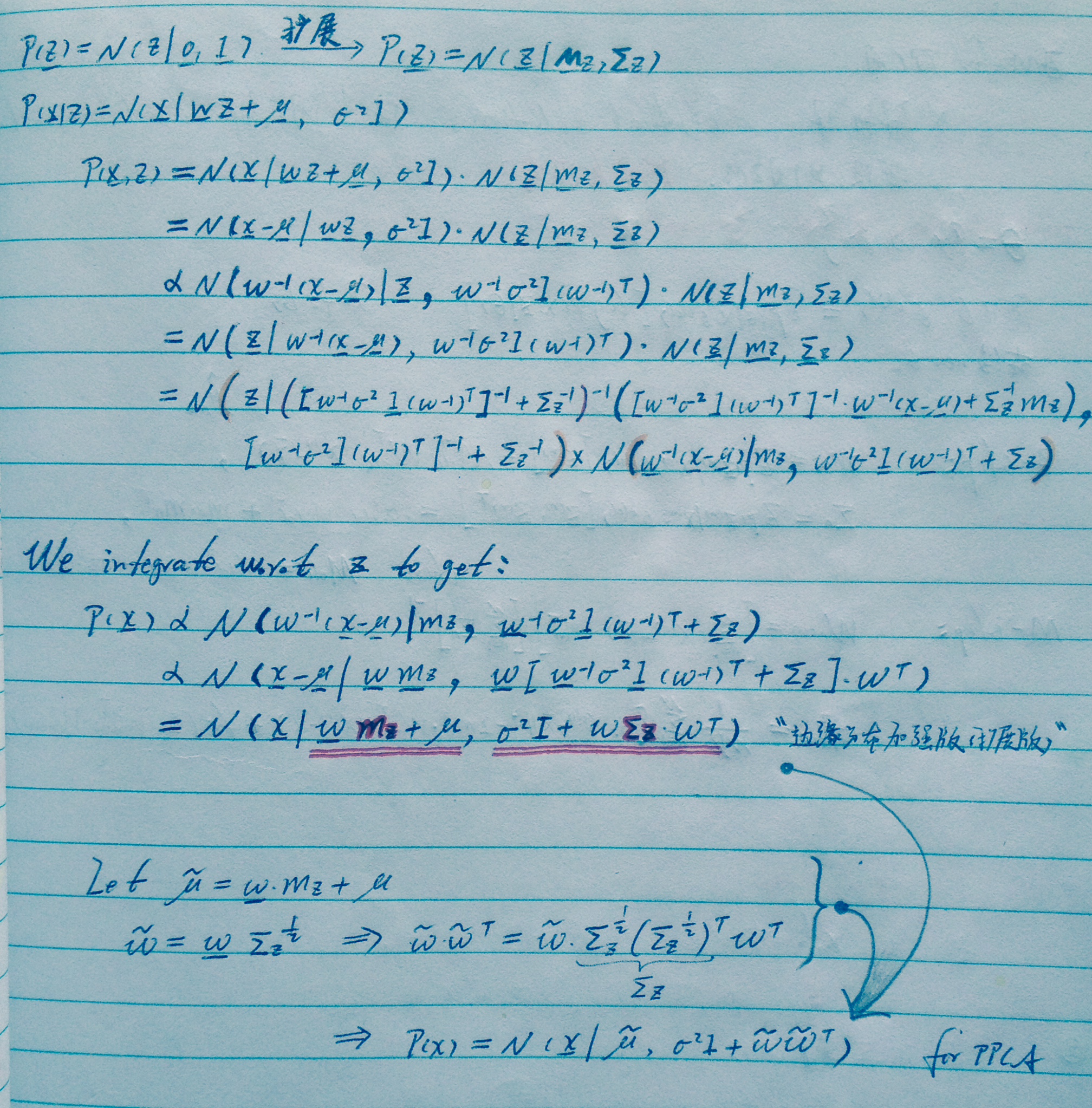
结论:x的边缘分布可以变为原来熟悉的样子。
按照fa的思路,凭什么x的边缘分布的方差是标准化的东东,改改会如何?

结论:还是这个熟悉的形式。
可见,“龙生龙,凤生凤,老鼠的儿子会打洞”,高斯的衍生还是那么“高斯”。
但问题是:边缘分布有点复杂,所以用em。

链接中用的Λ表示W,其他符号一致。
E step:
既然是em,E步骤计算:p(z(i) | x(i) ; µ, Λ, Ψ)
这里技巧在于,z和x都是高斯,一并构成了一个联合变量p(z, x),这个东西通过p(z) * p(x|z)就可以求得。
那么P(z|x)就可以通过以下公式直接求得:

调整一下思维:
p(z), p(x|z), p(x)都有,本可以通过贝叶斯公式计算,但几个这么复杂的高斯除来除去,是个什么鬼?感觉也不好计算。
所以,先人给出了以上公式,通过联合概率就直接写出结果了。
注意,联合概率是个高维高斯,且有两部分,一部分也可能包含多个维度。
M step:
思路就是通过log{P(x)}对各个参数求导。具体步骤,详见cs229链接,有超详细步骤,不再赘述。

先写到这里,本文只记录学习思路,帮助你建立知识体系,不会也不可能取代任何教材。
这一领域的东西,要充分领会,只能亲自动手算上一算。有时,你可能卡在一处无法进一步理解,该文可能会起到一点点“雪中送炭”的作用,这就足够了。
最后,再看:
prml:pca --> ppca --> fa
mlapp:fa --> pca --> ppca
如写小说,一个循序渐进,一个倒叙法。
[Bayesian] “我是bayesian我怕谁”系列 - Continuous Latent Variables的更多相关文章
- [Bayesian] “我是bayesian我怕谁”系列 - Gaussian Process
科班出身,贝叶斯护体,正本清源,故拿”九阳神功“自比,而非邪气十足的”九阴真经“: 现在看来,此前的八层功力都为这第九层作基础: 本系列第九篇,助/祝你早日hold住神功第九重,加入血统纯正的人工智能 ...
- [Bayesian] “我是bayesian我怕谁”系列 - Variational Autoencoders
本是neural network的内容,但偏偏有个variational打头,那就聊聊.涉及的内容可能比较杂,但终归会 end with VAE. 各个概念的详细解释请点击推荐的链接,本文只是重在理清 ...
- [Bayesian] “我是bayesian我怕谁”系列 - Variational Inference
涉及的领域可能有些生僻,骗不了大家点赞.但毕竟是人工智能的主流技术,在园子却成了非主流. 不可否认的是:乃值钱的技术,提高身价的技术,改变世界观的技术. 关于变分,通常的课本思路是: GMM --&g ...
- [Bayesian] “我是bayesian我怕谁”系列 - Boltzmann Distribution
使用Boltzmann distribution还是Gibbs distribution作为题目纠结了一阵子,选择前者可能只是因为听起来“高大上”一些.本章将会聊一些关于信息.能量这方面的东西,体会“ ...
- [Bayesian] “我是bayesian我怕谁”系列 - Exact Inferences
要整理这部分内容,一开始我是拒绝的.欣赏贝叶斯的人本就不多,这部分过后恐怕就要成为“从入门到放弃”系列. 但,这部分是基础,不管是Professor Daphne Koller,还是统计学习经典,都有 ...
- [Bayesian] “我是bayesian我怕谁”系列 - Exact Inference
要整理这部分内容,一开始我是拒绝的.欣赏贝叶斯的人本就不多,这部分过后恐怕就要成为“从入门到放弃”系列. 但,这部分是基础,不管是Professor Daphne Koller,还是统计学习经典,都有 ...
- [Bayesian] “我是bayesian我怕谁”系列 - Naive Bayes+prior
先明确一些潜规则: 机器学习是个collection or set of models,一切实践性强的模型都会被归纳到这个领域,没有严格的定义,’有用‘可能就是唯一的共性. 机器学习大概分为三个领域: ...
- [Bayesian] “我是bayesian我怕谁”系列 - Naive Bayes with Prior
先明确一些潜规则: 机器学习是个collection or set of models,一切实践性强的模型都会被归纳到这个领域,没有严格的定义,’有用‘可能就是唯一的共性. 机器学习大概分为三个领域: ...
- [Bayesian] “我是bayesian我怕谁”系列 - Markov and Hidden Markov Models
循序渐进的学习步骤是: Markov Chain --> Hidden Markov Chain --> Kalman Filter --> Particle Filter Mark ...
随机推荐
- Azure ARM (17) 基于角色的访问控制 (Role Based Access Control, RBAC) - 自定义Role
<Windows Azure Platform 系列文章目录> 在上面一篇博客中,笔者介绍了如何在RBAC里面,设置默认的Role. 这里笔者将介绍如何使用自定的Role. 主要内容有: ...
- cocos2dx 中触摸事件分发一些解读
触摸事件分发中几个代码解读: 怎么说呢,感觉cocos2dx中的消息分发机制,相对于android中触摸事件分发机制要简单的多.因为android中要做区域判断,过滤器,以及父子组件分发给谁等等的逻辑 ...
- HDU2688-Rotate
Recently yifenfei face such a problem that give you millions of positive integers,tell how many pair ...
- [AHOI2004]奇怪的字符串
[AHOI2004]奇怪的字符串 题目描述 输入输出格式 输入格式: 输入文件中包含两个字符串X和Y.当中两字符串非0即1.序列长度均小于9999. 输出格式: X和Y的最长公共子序列长度. 输入输出 ...
- 什么是PWM信号
PWM信号脉宽调制PWM是开关型稳压电源中的术语.这是按稳压的控制方式分类的,除了PWM型,还有PFM型和PWM.PFM混合型.脉宽宽度调制式(PWM)开关型稳压电路是在控制电路输出频率不变的情况下, ...
- 机器学习 数据挖掘 推荐系统机器学习-Random Forest算法简介
Random Forest是加州大学伯克利分校的Breiman Leo和Adele Cutler于2001年发表的论文中提到的新的机器学习算法,可以用来做分类,聚类,回归,和生存分析,这里只简单介绍该 ...
- Asp.net MVC4高级编程学习笔记-视图学习第三课Razor页面布局20171010
Razor页面布局 1) 在布局模板页中使用@RenderBody标记来渲染主要内容.比如很多web页面说头部和尾部相同,中间内容部分使用@RenderBody来显示不同的页面内容. 2) 在布局 ...
- 【JAVA零基础入门系列】Day8 Java的控制流程
什么是控制流程?简单来说就是控制程序运行逻辑的,因为程序一般而言不会直接一步运行到底,而是需要加上一些判断,一些循环等等.举个栗子,就好比你准备出门买个苹果,把这个过程当成程序的话,可能需要先判断一下 ...
- c# 接口实用
学习接口,还是记下来吧,不然以后忘记,这个东西也不是常用. interface Interface1 { } 接口中不能有字段, 只能声明方法.
- ActiveMQ——activemq的详细说明,queue、topic的区别(精选)
JMS中定义了两种消息模型:点对点(point to point, queue)和发布/订阅(publish/subscribe,topic).主要区别就是是否能重复消费. 点对点:Queue,不可重 ...