Java集合(2)一 ArrayList 与 LinkList
目录
Java集合(1)一 集合框架
Java集合(2)一 ArrayList 与 LinkList
Java集合(3)一 红黑树、TreeMap与TreeSet(上)
Java集合(4)一 红黑树、TreeMap与TreeSet(下)
Java集合(5)一 HashMap与HashSet
引言
ArrayList<E>和LinkList<E>在继承关系上都继承自List<E>接口,上篇文章我们分析了List<E>接口的特点:有序,可以重复,并且可以通过整数索引来访问。
他们在自身特点上有很多相似之处,在具体实现上ArrayList<E>和LinkList<E>又有很大不同,ArrayList<E>通过数组实现,LinkList<E>则使用了双向链表。将他们放到一起学习可以更清楚的理解他们的区别。
框架结构

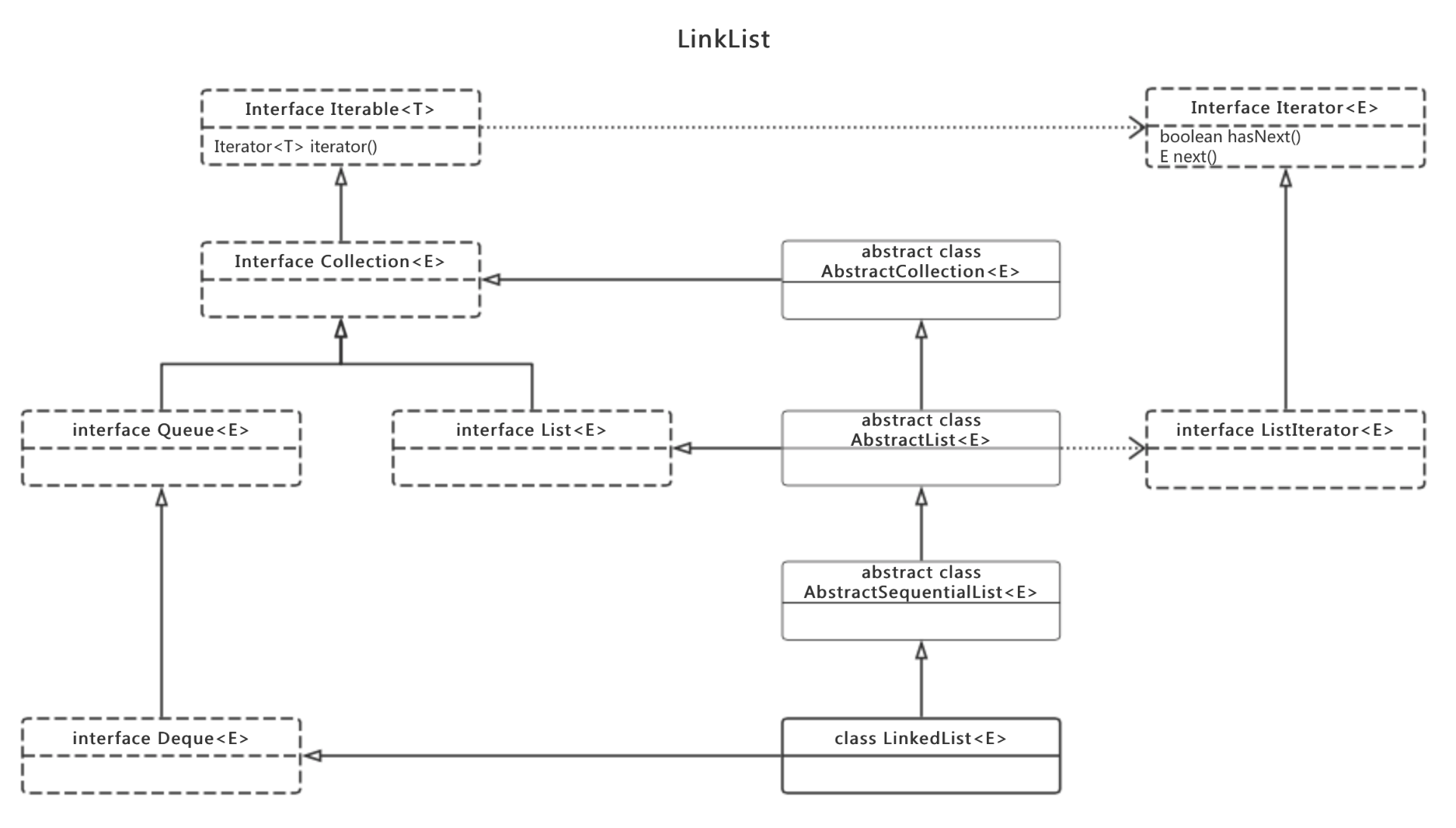
从上面的结构图可以看出ArrayList<E>和LinkList<E>在继承结构上基本相同,值得注意的是LinkList<E>在继承了List<E>接口的同时还继承了Deque<E>接口。
Deque<E>是一个双端队列的接口,LinkList<E>由于在实现上采用了双向链表,所以可以很自然的实现双端队列头尾进出的特点。
数据结构
上一篇文章中我们说过,为什么一个Collection<E>接口会衍生出这么多实现类,其中最大的原因就是每一种实现在数据结构上都有差别,而不同的数据结构又导致了每种集合在使用场景上又各有不同。
ArrayList<E>和LinkList<E>的根本区别就在数据结构上,只有了解了他们各自的数据结构,才能更加深入的明白他们各自的使用场景。
在ArrayList<E>的源代码中有一个elementData变量,这个变量就代表了ArrayList<E>所使用的数据结构:数组。
//The array buffer into which the elements of the ArrayList are stored.
transient Object[] elementData;
elementData变量是ArrayList<E>操作的基础,他所有的操作都是基于elementData这个Object类型的数组来实现的。
数组有以下几个特点:
- 数组大小一旦初始化之后,长度固定。
- 数组中元素之间的内存地址是连续的。
- 只能存储一种类数据类型的元素。

在这里面有个transient关键字值得注意,他的作用是标志当前对象不需要序列化。
如果大家了解序列化,请跳过下面的介绍:
序列化是什么?
序列化简单说就是将一个对象持久化的过程。将对象转换成字节流的过程就叫序列化,一个对象要在网络中传播就必须被转换成字节流。对应的,一个对象从字节流转换成对象的过程就叫反序列化。
在Java中,标志一个对象可以被序列化只需要继承Serializable接口即可,Serializable接口是一个空接口。
明白了什么是序列化的概念,再来看transient关键字,java中规定被声明为transient的关键在被序列化的时候会被忽略,可是为什么要忽略这个对象呢?如果被忽略了那反序列化的时候这个对象怎样恢复呢?
我们先来想想什么样的对象在序列化时需要被忽略?序列化是一个耗时也耗费空间的过程,一般在一个对象中除了必须持久化的变量,还会存在很多中间变量或临时变量,声明这些变量的作用是方便我们操作这个类,举个例子:
import java.io.IOException;
import java.io.ObjectInputStream;
public class SerializableDateTime implements java.io.Serializable {
private static final long serialVersionUID = -8291235042612920489L;
private String date = "2011-11-11";
private String time = "11:11";
//不需要序列化的对象
private transient String dateTime;
public void initDateTime() {
dateTime = date + time;
}
//反序列化的时候调用,给dateTime赋值
private void readObject(ObjectInputStream inputStream) throws IOException, ClassNotFoundException {
inputStream.defaultReadObject();
initDateTime();
}
}
SerializableDateTime对象中的dateTime对象如果在外界调用的时候会赋值,但是这个对象并不是基础数据,不需要序列化,在反序列化的时候可以通过调用initDateTime返回获取他的值,所以只需要序列化date和time对象即可。将dateTime对象标记为transient,则可以达到按需序列化的目的。
那在ArrayList<E>中为什么要忽略elementData这个对象呢?
主要是因为elementData对象不仅包含了所有有用的元素,还存在许多没有未使用的空间,而这些空间是不需要全部序列化的,为了节约空间,所以只序列化了elementData中存有对象的那一部分,在反序列化的时候又恢复elementData对象的空间,这样可以达到节约序列化空间和时间的目的。
//序列化时调用
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException{
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioural compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
//序列化size大小的元素,size的大小是实际存储元素的大小,不是elementData元素的大小
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
//反序列化时调用
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// be like clone(), allocate array based upon size not capacity
//恢复elementData对象的空间
ensureCapacityInternal(size);
Object[] a = elementData;
// Read in all elements in the proper order.
for (int i=0; i<size; i++) {
//填充elementData元素的内容
a[i] = s.readObject();
}
}
}
这种序列化和反序列化的方法非常巧妙,在我们编程的过程中也可以借鉴这种办法来节约序列化和反序列化的空间和时间。
LinkedList<E>在底层实现上采用了链表这种数据结构,而且是双向链表,即每个元素都包含他的上一个和下一个元素的引用:
//链表的第一个元素
transient Node<E> first;
//链表的最后一个元素
transient Node<E> last;
//链表的内部类表示
private static class Node<E> {
//当前元素
E item;
//下一个元素
Node<E> next;
//上一个元素
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
链表的特点:
- 长度不固定,可以随时增加和减少
- 链表中的元素在内存地址上可以是连续的,也可以是不连续的,大部分情况下都是不连续的。

构造函数
ArrayList<E>提供了3种构造方式,默认的构造函数会初始化一个空的数组,在之后添加元素的过程中会对数组进行扩容,扩容操作在一定程度上会影响数组的性能。如果能提前预估最终的数组使用空间大小,可以通过ArrayList(int initialCapacity) 这种构造方式来初始化数组大小,这样会减少扩容造成的性能损失。
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//初始化数组大小
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
//初始化一个空的数组
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
LinkList<E>只提供了2种构造方式,默认的构造函数是一个空函数,因为链表这种数据结构在使用上不需要初始化空间,也不需要扩容,每次需要添加元素时直接追加就可以,在空间的最大化利用上链表比数组更加合理。这并不代表链表使用的空间小,相反,链表每个节点因为要存储下一个节点引用(双向链表会存储上下两个节点的引用),在相同元素空间使用上会比数组大的多。
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
添加元素
ArrayList<E>在添加元素的过程中,需要考虑数组空间是否足够,不够的情况下需要扩容。
//ArrayList<E>添加元素到末尾
public boolean add(E e) {
//检查数组容量,不够就扩容,扩容调用grow(int minCapacity) 方法
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//扩容
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//向右位移一位,相当于除以2,比除法运算要快,每次扩容在原容量的基础上增加一半,新的容量为原容量的1.5倍。
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
//拷贝所有数据元素到新的数组中,内部调用System.arraycopy来拷贝所有数组元素
elementData = Arrays.copyOf(elementData, newCapacity);
}
不扩容:

扩容:
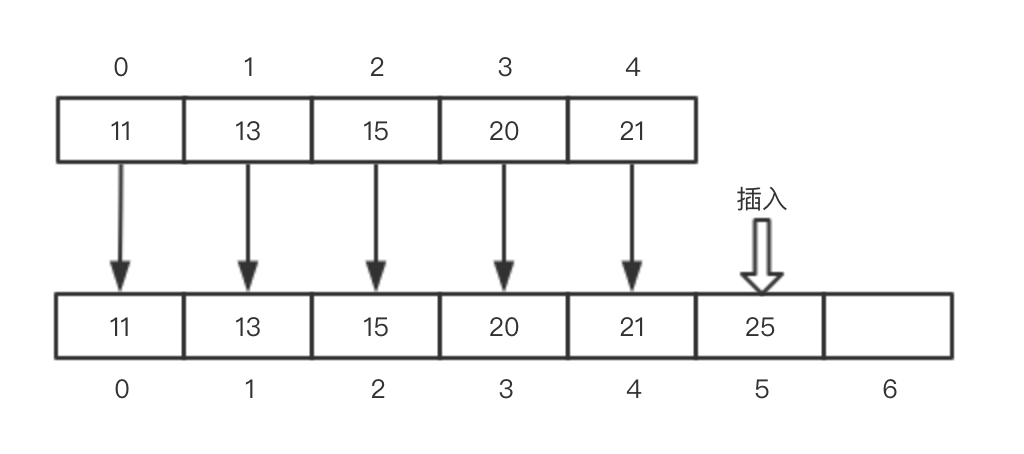
从中可以看出,不扩容的情况下添加元素到末尾非常方便,时间复杂度为O(1),扩容的情况下每次都需要拷贝所有元素到新数组,时间复杂度上为O(n),存在一定性能损耗。
LinkedList<E>在添加元素时由于链表的特性,不需要考虑扩容的问题,但LinkedList<E>每次都需要new一个Node来存储元素。
//LinkedList<E>添加元素到末尾
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
//new一个新的链表元素并链接到末尾
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}

ArrayList<E>在添加元素到指定索引位置的时候,除了检查容量之外,由于数组具有在空间连续存储的特性,还需要对插入元素之后的所有节点做一次位移。
```java
//ArrayList添加元素到指定索引位置
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,size - index);
elementData[index] = element;
size++;
}
<img src="http://images2017.cnblogs.com/blog/368583/201711/368583-20171130181801667-175597278.png" style="max-width: 770px">
LinkedList<E>添加到指定位置时首先需要先查找元素的位置,然后添加。
```java
//LinkedList<E>添加元素到指定索引位置
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
//直接添加元素到末尾
linkLast(element);
else
//添加到指定位置前先查找当前位置已经存在的元素
linkBefore(element, node(index));
}
//查找指定索引的元素
Node<E> node(int index) {
// assert isElementIndex(index);
//指定索引小于元素数量的一半时从first开始遍历,大于元素数量的一半时从last开始遍历
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
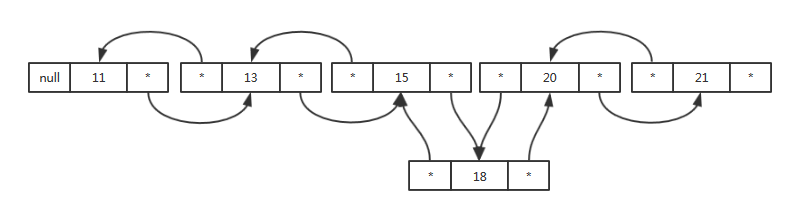
LinkedList<E>的这种查找对性能有影响吗?相比ArrayList<E>的扩容以及位移插入位后面所有的元素性能如何?我们来对插入到头部、尾部以及中间位置3种特殊情况做个简单测试。
插入到尾部:
private static void addTailElementArrayList(int count) {
long startTime = System.currentTimeMillis();
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < count; i++) {
list.add(i);
}
long endTime = System.currentTimeMillis();
System.out.println("addTailElementArrayList time: " + (endTime - startTime));
}
private static void addTailElementLinkedList(int count) {
long startTime = System.currentTimeMillis();
List<Integer> list = new LinkedList<Integer>();
for (int i = 0; i < count; i++) {
list.add(i);
}
long endTime = System.currentTimeMillis();
System.out.println("addTailElementLinkedList time: " + (endTime - startTime));
}
| 100 | 1000 | 10000 | 100000 | |
|---|---|---|---|---|
| ArrayList | 0 | 0 | 1 | 160 |
| LinkList | 0 | 0 | 1 | 110 |
插入到头部:
private static void addHeadElementArrayList(int count) {
long startTime = System.currentTimeMillis();
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < count; i++) {
list.add(0, i);
}
long endTime = System.currentTimeMillis();
System.out.println("addHeadElementArrayList time: " + (endTime - startTime));
}
private static void addHeadElementLinkedList(int count) {
long startTime = System.currentTimeMillis();
List<Integer> list = new LinkedList<Integer>();
for (int i = 0; i < count; i++) {
list.add(0, i);
}
long endTime = System.currentTimeMillis();
System.out.println("addHeadElementLinkedList time: " + (endTime - startTime));
}
| 100 | 1000 | 10000 | 100000 | |
|---|---|---|---|---|
| ArrayList | 0 | 1 | 10 | 900 |
| LinkList | 0 | 1 | 1 | 6 |
插入到中间:
private static void addCenterIndexElementArrayList(int count) {
long startTime = System.currentTimeMillis();
List<Integer> list = new ArrayList<Integer>();
for (int i = 0; i < count; i++) {
list.add(list.size()>>1, i);
}
long endTime = System.currentTimeMillis();
System.out.println("addCenterIndexElementArrayList time: " + (endTime - startTime));
}
private static void addCenterIndexElementLinkedList(int count) {
long startTime = System.currentTimeMillis();
List<Integer> list = new LinkedList<Integer>();
for (int i = 0; i < count; i++) {
list.add(list.size()>>1, i);
}
long endTime = System.currentTimeMillis();
System.out.println("addCenterIndexElementLinkedList time: " + (endTime - startTime));
}
| 100 | 1000 | 10000 | 100000 | |
|---|---|---|---|---|
| ArrayList | 0 | 1 | 6 | 400 |
| LinkList | 0 | 3 | 80 | 10000 |
从中可以得处几个简单结论:
- 在添加到末尾时,ArrayList<E>和LinkedList<E>在性能上差距不明显,尽管ArrayList<E>需要扩容,但LinkedList<E>也需要new一个Node对象。
- 在插入到头部时,LinkedList<E>性能明显好于ArrayList<E>,因为ArrayList<E>每次都需要将所有元素向后移动一个位置,而LinkedList<E>由于是双向链表每次只需要改变first元素就可以了。
- 在插入到中间位置的时候,ArrayList<E>性能优明显好于LinkedList<E>,这是因为ArrayList<E>此时只需要移动一半的元素,而LinkedList<E>因为其双向链表查找元素的特殊性,只能从头或者尾部开始遍历,每次都需要遍历一半的元素,这个操作耗费了大量时间,而ArrayList<E>在扩容以及移动元素上的性能消耗比想象的要小。
我们在ArrayList<E>和LinkedList<E>的选择上,需要充分考虑使用时的场景,LinkedList<E>在插入数据上并不是一定比ArrayList<E>性能好,相反的在很多情况下ArrayList<E>性能反而要好的多。不能因为插入操作多,就一定选用LinkedList<E>,还需要考虑插入元素的位置等其他因素来最终决定。
删除元素
ArrayList<E>删除元素通过遍历元素查找到相等的元素然后使用索引删除,删除之后还要将被删除元素后的元素前移。
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
//查找到equals的元素的索引然后删除
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
//所有删除元素后的元素前移
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
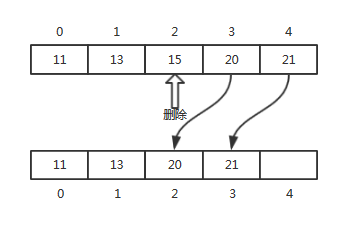
LinkedList<E>通过向后遍历链表的方式查找到equals的元素直接删除即可。
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
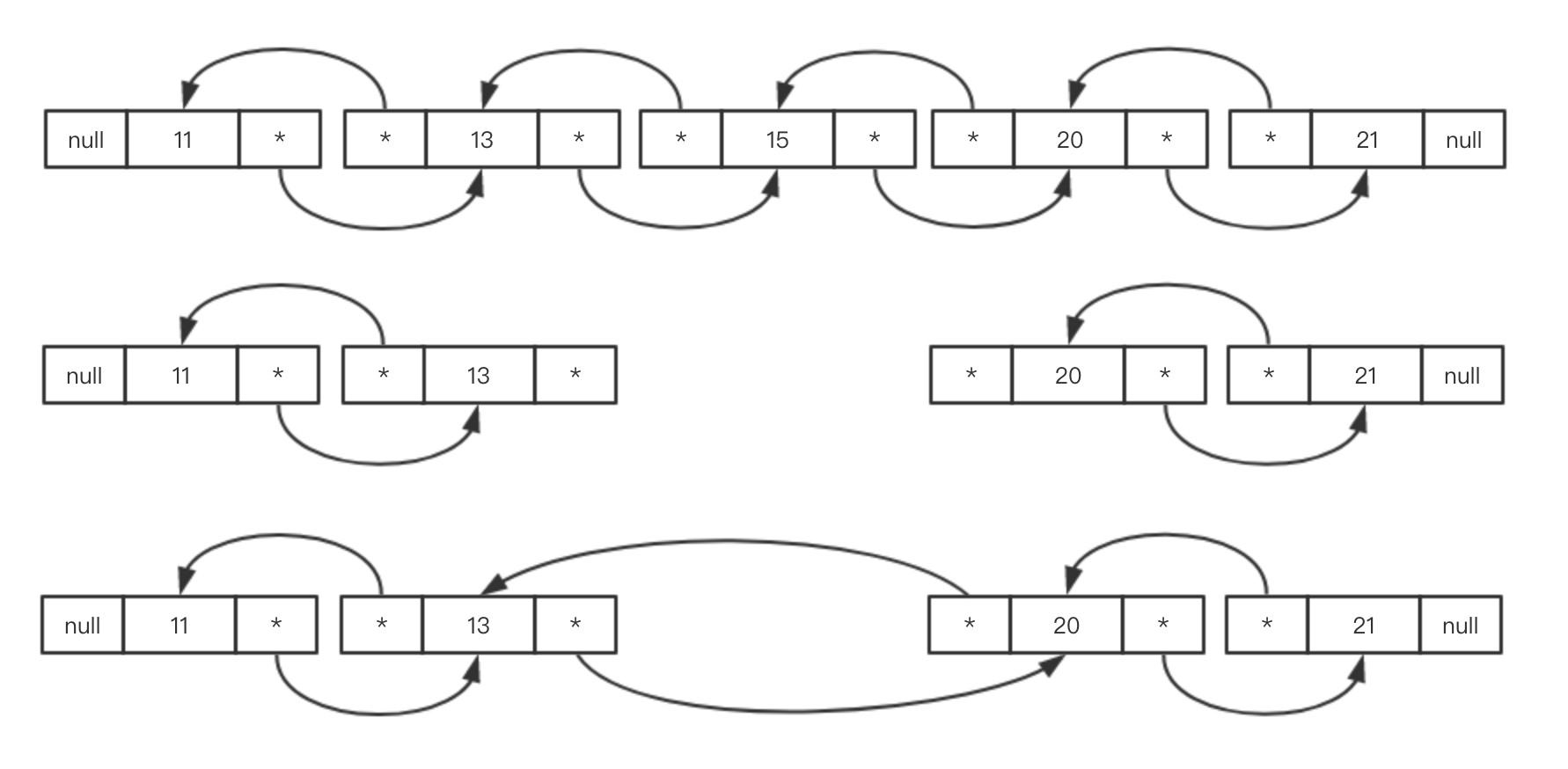
遍历元素
在遍历元素上ArrayList<E>存在更有效的方式,他实现了RandomAccess接口,代表ArrayList<E>支持快速访问。
RandomAccess本身是一个空接口,这种接口一般用来代表一类特征,RandomAccess代表实现类具有快速访问的特征。ArrayList<E>实现快速访问的方式是通过索引。这代表ArrayList<E>在遍历时通过for循环方式要比通过Iterator或ListIterator迭代器方式要快。LinkedList<E>没有实现这个借口,所以一般还是通过Iterator迭代器来访问。
Java集合(2)一 ArrayList 与 LinkList的更多相关文章
- Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
- java集合系列之ArrayList源码分析
java集合系列之ArrayList源码分析(基于jdk1.8) ArrayList简介 ArrayList时List接口的一个非常重要的实现子类,它的底层是通过动态数组实现的,因此它具备查询速度快, ...
- Java集合框架之ArrayList浅析
Java集合框架之ArrayList浅析 一.ArrayList综述: 位于java.util包下的ArrayList是java集合框架的重要成员,它就是传说中的动态数组,用MSDN中的说法,就是Ar ...
- 【Java集合系列】---ArrayList
开篇前言--ArrayList中的基本方法 前面的博文中,小编主要简单介绍java集合的总体架构,在接下来的博文中,小编将详细介绍里面的各个类,通过demo.对比,来对java集合类进行更加深入的理解 ...
- java集合系列之三(ArrayList)
上一章,我们学习了Collection的架构.这一章开始,我们对Collection的具体实现类进行讲解:首先,讲解List,而List中ArrayList又最为常用.因此,本章我们讲解ArrayLi ...
- java集合框架03——ArrayList和源码分析
最近忙着替公司招人好久没写了,荒废了不好意思. 上一章学习了Collection的架构,并阅读了部分源码,这一章开始,我们将对Collection的具体实现进行详细学习.首先学习List.而Array ...
- java集合之深入分析ArrayList
ArrayList特点: ArrayList方法实现: 扩容方法的实现: 源码: private void ensureCapacityInternal(int minCapacity) { //如果 ...
- Java——集合框架之ArrayList,LinkedList,迭代器Iterator
概述--集合框架 Java语言的设计者对常用的数据结构和算法做了一些规范(接口)和实现(具体实现接口的类).所有抽象出来的数据结构和操作(算法)统称为Java集合框架(Java Collection ...
- Java集合框架(一)-ArrayList
大佬理解->Java集合之ArrayList 1.ArrayList的特点 存放的元素有序 元素不唯一(可以重复) 随机访问快 插入删除元素慢 非线程安全 2.底层实现 底层初始化,使用一个Ob ...
- java集合 collection-list-ArrayList 去除ArrayList集合中的重复元素。
import java.util.*; /* 去除ArrayList集合中的重复元素. */ class ArrayListTest { public static void sop(Object o ...
随机推荐
- [Bayesian] “我是bayesian我怕谁”系列 - Naive Bayes+prior
先明确一些潜规则: 机器学习是个collection or set of models,一切实践性强的模型都会被归纳到这个领域,没有严格的定义,’有用‘可能就是唯一的共性. 机器学习大概分为三个领域: ...
- SQL查询一个表里面某个字段值相同的数据记录
好长时间没有用SQL了...还停留在学生时代的水平... 转: 昨天遇到个面试题:查询一个表里面某个字段值相同的数据记录,好久没有写过这种,还真的花了点时间才写出来.如表g_carddetail,有 ...
- [Scikit-learn] 2.1 Clustering - Variational Bayesian Gaussian Mixture
最重要的一点是:Bayesian GMM为什么拟合的更好? PRML 这段文字做了解释: Ref: http://freemind.pluskid.org/machine-learning/decid ...
- [Bayesian] “我是bayesian我怕谁”系列 - Continuous Latent Variables
打开prml and mlapp发现这部分目录编排有点小不同,但神奇的是章节序号竟然都为“十二”. prml:pca --> ppca --> fa mlapp:fa --> pca ...
- Linux学习(十四)磁盘格式化、磁盘挂载、手动增加swap空间
一.磁盘格式化 分好去的磁盘需要格式化之后才可以使用.磁盘分区一般用mke2fs命令或者mkfs.filesystemtype.这个filesystemtype分为ext4,ext3,xfs等等.xf ...
- SignalR实现消息推送,包括私聊、群聊、在线所有人接收消息(源码)
一.关于SignalR 1.简介:Signal 是微软支持的一个运行在 Dot NET 平台上的 html websocket 框架.它出现的主要目的是实现服务器主动推送(Push)消息到客户端页面, ...
- Cisco VPN Client Win10无法使用的解决办法
http://files.cnblogs.com/files/Flyear/VPN_Win10_ByDuke.zip 1. 关闭系统所有窗口,控制面板一定要关闭. 2. 运行winfix.exe, 按 ...
- 修改oracle服务器端字符集
----设置字符集步聚------- conn /as sysdba; shutdown immediate; startup mount; alter system enable restricte ...
- 2017阿里云双11-云服务器ECS优惠活动最强解读和购买指南
本站之前介绍了<爆款云服务器,限时2折起>,这其实是阿里云双11之前的预热活动:四款低配的机型,二折给用户(每个用户限购一台),非常的实惠,有很多阅读了本站文章的用户都一次性购买了三年的. ...
- 如何实现border-width:0.5px;
工作中遇到了一个产品需求,要求把列表分割线改成0.5px,直接写成border:0.5px solid #cccccc;是不符合规范的写法,会存在Android和IOS手机上的兼容问题,故,我们可以利 ...