Python: Pandas的DataFrame如何按指定list排序
本文首发于微信公众号“Python数据之道”(ID:PyDataRoad)
前言
写这篇文章的起由是有一天微信上一位朋友问到一个问题,问题大体意思概述如下:
现在有一个pandas的Series和一个python的list,想让Series按指定的list进行排序,如何实现?
这个问题的需求用流程图描述如下:
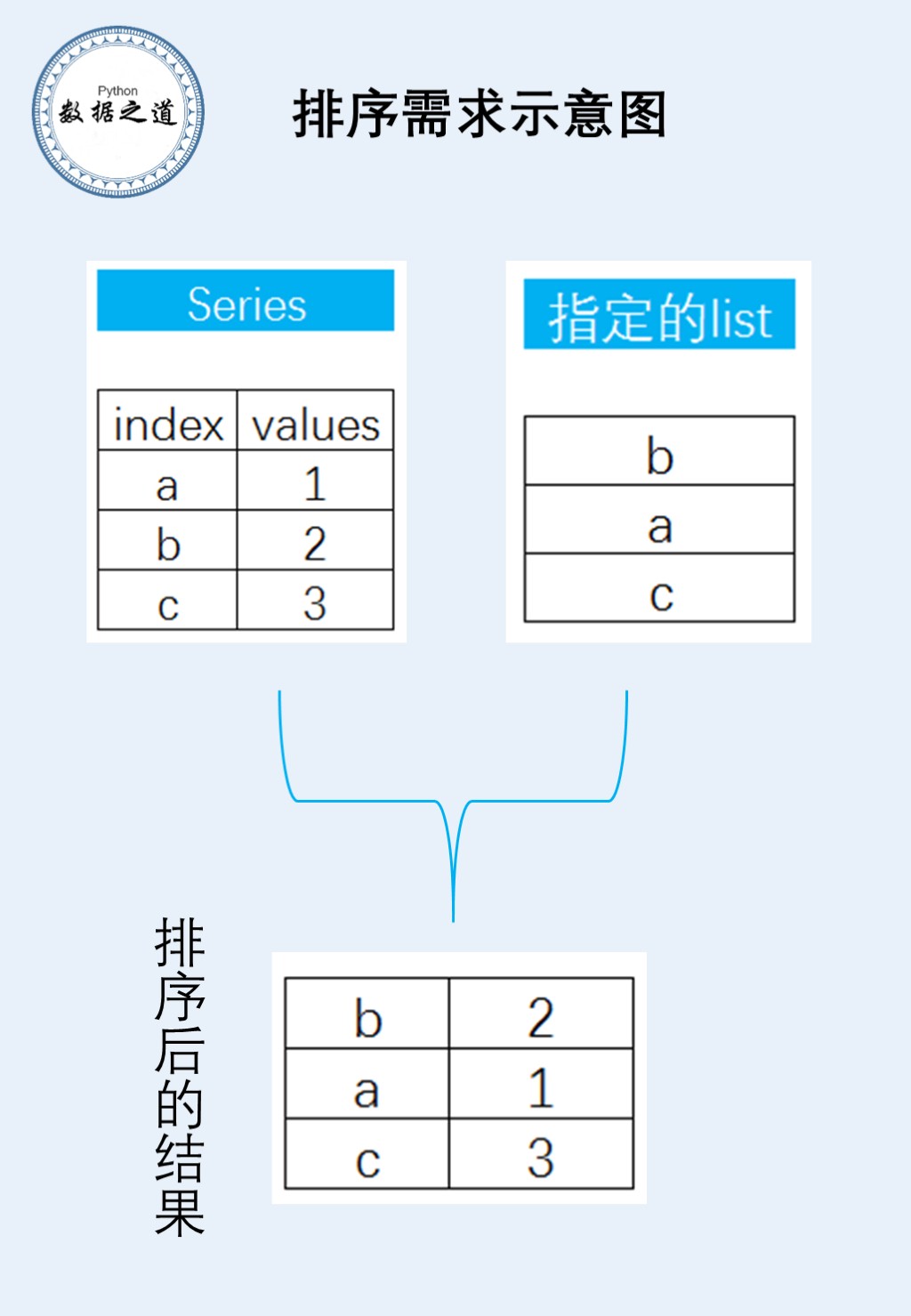
我思考了一下,这个问题解决的核心是引入pandas的数据类型“category”,从而进行排序。
在具体的分析过程中,先将pandas的Series转换成为DataFrame,然后设置数据类型,再进行排序。思路用流程图表示如下:
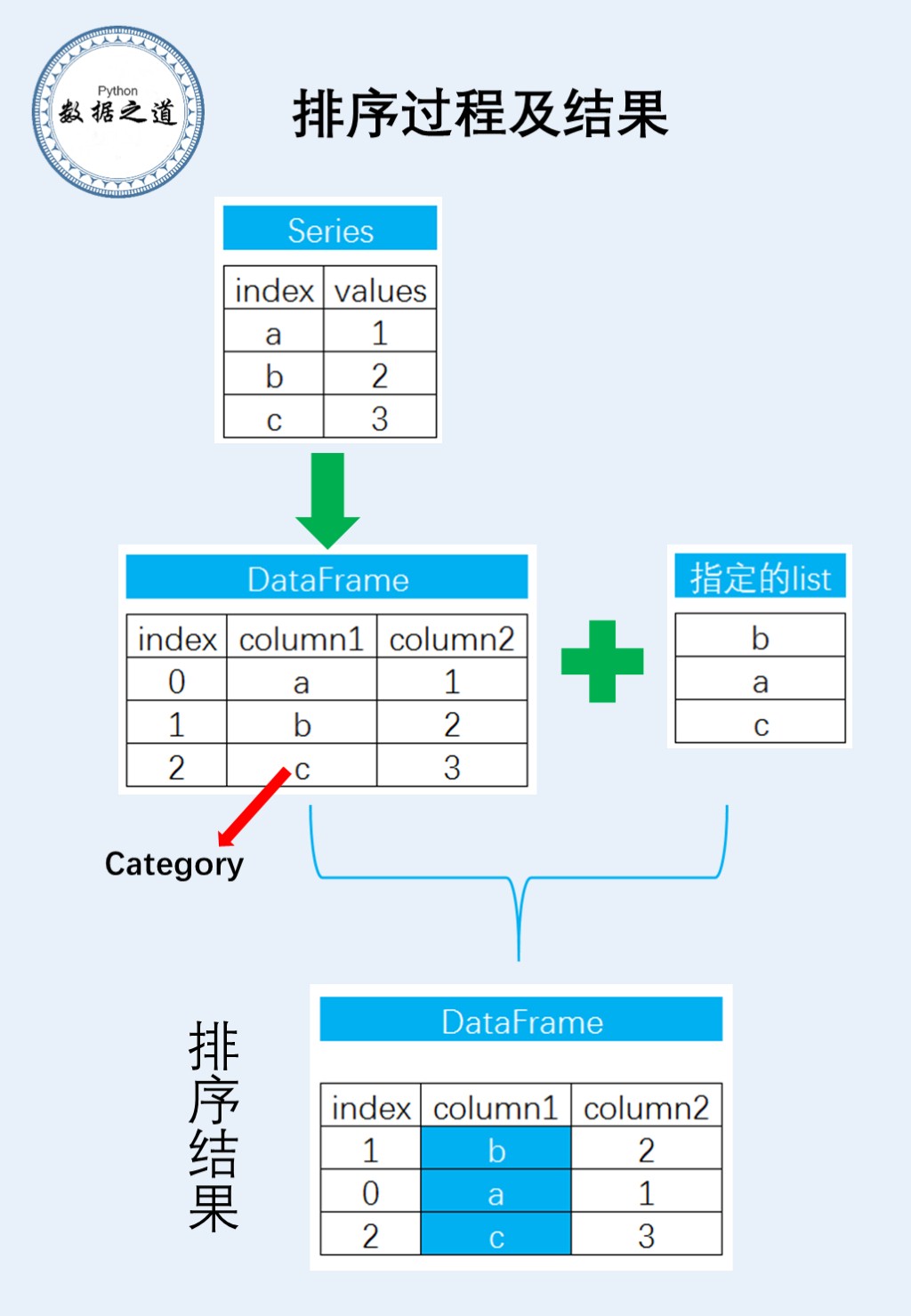
分析过程
- 引入pandas库
import pandas as pd
- 构造Series数据
s = pd.Series({'a':1,'b':2,'c':3})
s
a 1
b 2
c 3
dtype: int64
s.index
Index(['a', 'b', 'c'], dtype='object')
- 指定的list,后续按指定list的元素顺序进行排序
list_custom = ['b', 'a', 'c']
list_custom
['b', 'a', 'c']
- 将Series转换成DataFrame
df = pd.DataFrame(s)
df = df.reset_index()
df.columns = ['words', 'number']
df
| words | number | |
|---|---|---|
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
设置成“category”数据类型
# 设置成“category”数据类型
df['words'] = df['words'].astype('category')
# inplace = True,使 recorder_categories生效
df['words'].cat.reorder_categories(list_custom, inplace=True)
# inplace = True,使 df生效
df.sort_values('words', inplace=True)
df
| words | number | |
|---|---|---|
| 1 | b | 2 |
| 0 | a | 1 |
| 2 | c | 3 |
指定list元素多的情况:
若指定的list所包含元素比Dataframe中需要排序的列的元素多,怎么办?
- reorder_catgories()方法不能继续使用,因为该方法使用时要求新的categories和dataframe中的categories的元素个数和内容必须一致,只是顺序不同。
- 这种情况下,可以使用 set_categories()方法来实现。新的list可以比dataframe中元素多。
list_custom_new = ['d', 'c', 'b','a','e']
dict_new = {'e':1, 'b':2, 'c':3}
df_new = pd.DataFrame(list(dict_new.items()), columns=['words', 'value'])
print(list_custom_new)
df_new.sort_values('words', inplace=True)
df_new
['d', 'c', 'b', 'a', 'e']
| words | value | |
|---|---|---|
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
df_new['words'] = df_new['words'].astype('category')
# inplace = True,使 set_categories生效
df_new['words'].cat.set_categories(list_custom_new, inplace=True)
df_new.sort_values('words', ascending=True)
| words | value | |
|---|---|---|
| 1 | c | 3 |
| 0 | b | 2 |
| 2 | e | 1 |
指定list元素少的情况:
若指定的list所包含元素比Dataframe中需要排序的列的元素少,怎么办?
- 这种情况下,set_categories()方法还是可以使用的,只是没有的元素会以NaN表示
注意下面的list中没有元素“b”
list_custom_new = ['d', 'c','a','e']
dict_new = {'e':1, 'b':2, 'c':3}
df_new = pd.DataFrame(list(dict_new.items()), columns=['words', 'value'])
print(list_custom_new)
df_new.sort_values('words', inplace=True)
df_new
['d', 'c', 'a', 'e']
| words | value | |
|---|---|---|
| 0 | b | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
df_new['words'] = df_new['words'].astype('category')
# inplace = True,使 set_categories生效
df_new['words'].cat.set_categories(list_custom_new, inplace=True)
df_new.sort_values('words', ascending=True)
| words | value | |
|---|---|---|
| 0 | NaN | 2 |
| 1 | c | 3 |
| 2 | e | 1 |
总结
根据指定的list所包含元素比Dataframe中需要排序的列的元素的多或少,可以分为三种情况:
- 相等的情况下,可以使用 reorder_categories和 set_categories方法;
- list的元素比较多的情况下, 可以使用set_categories方法;
- list的元素比较少的情况下, 也可以使用set_categories方法,但list中没有的元素会在DataFrame中以NaN表示。
源代码
需要的童鞋可在微信公众号“Python数据之道”(ID:PyDataRoad)后台回复关键字获取视频,关键字如下:
“2017-025”(不含引号)
Python: Pandas的DataFrame如何按指定list排序的更多相关文章
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
- python pandas.Series&&DataFrame&& set_index&reset_index
参考CookBook :http://pandas.pydata.org/pandas-docs/stable/cookbook.html Pandas set_index&reset_ind ...
- python pandas ---Series,DataFrame 创建方法,操作运算操作(赋值,sort,get,del,pop,insert,+,-,*,/)
pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包 pandas 也是围绕着 Series 和 DataFrame 两个核心数据结构展开的, 导入如下: from panda ...
- 吴裕雄--天生自然python学习笔记:pandas模块DataFrame 数据的修改及排序
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]] ...
- python基础:如何使用python pandas将DataFrame转换为dict
之前在知乎上看到有网友提问,如何将DataFrame转换为dict,专门研究了一下,pandas在0.21.0版本中是提供了这个方法的.下面一起学习一下,通过调用help方法,该方法只需传入一个参数, ...
- python学习笔记—DataFrame和Series的排序
更多大数据分析.建模等内容请关注公众号<bigdatamodeling> ################################### 排序 ################## ...
- python 数据处理学习pandas之DataFrame
请原谅没有一次写完,本文是自己学习过程中的记录,完善pandas的学习知识,对于现有网上资料的缺少和利用python进行数据分析这本书部分知识的过时,只好以记录的形势来写这篇文章.最如果后续工作定下来 ...
- oracle数据据 Python+Pandas 获取Oracle数据库并加入DataFrame
import pandas as pd import sys import imp imp.reload(sys) from sqlalchemy import create_engine impor ...
- 【跟着stackoverflow学Pandas】 - Adding new column to existing DataFrame in Python pandas - Pandas 添加列
最近做一个系列博客,跟着stackoverflow学Pandas. 以 pandas作为关键词,在stackoverflow中进行搜索,随后安照 votes 数目进行排序: https://stack ...
随机推荐
- 1.6 OWIN集成
OWIN集成 安装 使用 如果在应用程序里既使用ASP.NET MVC也使用ASP.NET Web API,需要在工程里安装Abp.Owin包. 安装 添加Abp.Owin包到主工程里(一般是web工 ...
- Google Earth影像数据破解之旅
"Zed, you are so excellent." 为什么要写这句英文?容我卖个关子稍后再解释. 相信大多数人都体验过Google Earth(简称GE),我对GE最初的印象 ...
- Asp.NET MVC 之心跳/长连接
0x01 在线用户类,我的用户唯一性由ID和类型识别(因为在不同的表里) public class UserIdentity : IEqualityComparer<UserIdentity&g ...
- split()方法
split()方法用于把一个字符串分隔成字符串数组. 它有两个参数: separator:从参数指定的地方分隔字符串,必需: howmany:该参数可指定返回的数组的最大长度.如果设置了该参数,返回的 ...
- Java基础语法(一)<注释,关键字,常量,变量,数据类型,标识符,数据类型转换>
从今天开始,记录学习Java的过程.要学习Java首先得有环境,至于环境的安装我就不说了,百度有很多教程,比如:http://jingyan.baidu.com/article/20095761904 ...
- 搭建本地git仓库
使用工具:git|码云 步骤: 注册码云账号,创建项目名称等. 本地git配置 本地文件目录:git init(初始化创建分支master) 基础配置:git config --global user ...
- 接上一篇中记录Echarts进度环使用【不同状态不同进度环颜色及圈内文字】--采用单实例业务进行说明
接上一篇中记录Echarts进度环使用 此处处理不同状态下不同进度环颜色及圈内文字等的相关处理,采用实际案例源码说明 -----------------偶是华丽丽分割线---------------- ...
- Java 7之基础 - 强引用、弱引用、软引用、虚引用
1.强引用(StrongReference) 强引用是使用最普遍的引用.如果一个对象具有强引用,那垃圾回收器绝不会回收它.如下: Object o=new Object(); // 强引用 当内 ...
- declare 命令
declare命令用于声明和显示shell变量. declare为shell指令,命令与 typeset一样,可同时指定多个属性.若不加上任何参数,则会显示全部的shell变量与函数(与执行set指令 ...
- 用react系列技术栈实现的demo整合系统
引子 学生时代为了掌握某个知识点会不断地做习题,做总结,步入岗位之后何尝不是一样呢?做业务就如同做习题,如果‘课后’适当地进行总结,必然更快地提升自己的水平. 由于公司采用的react+node的技术 ...