MapReduce工作原理流程简介

在MapReduce整个过程可以概括为以下过程:
输入 --> map --> shuffle --> reduce -->输出
输入文件会被切分成多个块,每一块都有一个map task
map阶段的输出结果会先写到内存缓冲区,然后由缓冲区写到磁盘上。默认的缓冲区大小是100M,溢出的百分比是0.8,也就是说当缓冲区中达到80M的时候就会往磁盘上写。如果map计算完成后的中间结果没有达到80M,最终也是要写到磁盘上的,因为它最终还是要形成文件。那么,在往磁盘上写的时候会进行分区和排序。一个map的输出可能有多个这个的文件,这些文件最终会合并成一个,这就是这个map的输出文件。
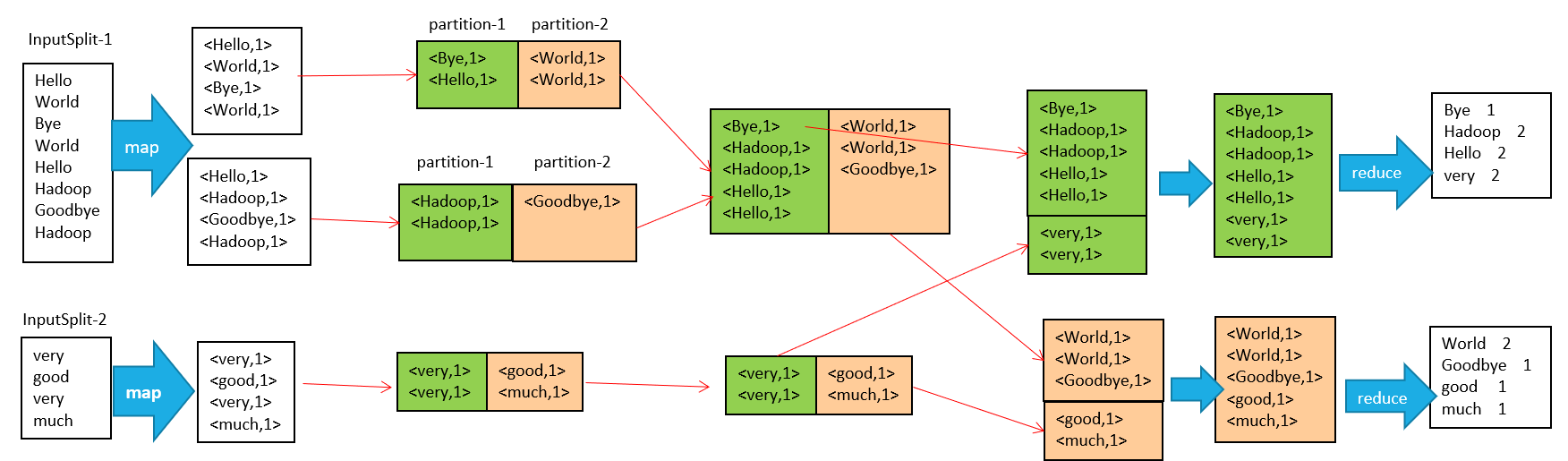
流程说明如下:
1、输入文件分片,每一片都由一个MapTask来处理
2、Map输出的中间结果会先放在内存缓冲区中,这个缓冲区的大小默认是100M,当缓冲区中的内容达到80%时(80M)会将缓冲区的内容写到磁盘上。也就是说,一个map会输出一个或者多个这样的文件,如果一个map输出的全部内容没有超过限制,那么最终也会发生这个写磁盘的操作,只不过是写几次的问题。
3、从缓冲区写到磁盘的时候,会进行分区并排序,分区指的是某个key应该进入到哪个分区,同一分区中的key会进行排序,如果定义了Combiner的话,也会进行combine操作
4、如果一个map产生的中间结果存放到多个文件,那么这些文件最终会合并成一个文件,这个合并过程不会改变分区数量,只会减少文件数量。例如,假设分了3个区,4个文件,那么最终会合并成1个文件,3个区
5、以上只是一个map的输出,接下来进入reduce阶段
6、每个reducer对应一个ReduceTask,在真正开始reduce之前,先要从分区中抓取数据
7、相同的分区的数据会进入同一个reduce。这一步中会从所有map输出中抓取某一分区的数据,在抓取的过程中伴随着排序、合并。
8、reduce输出
MapReduce工作原理流程简介的更多相关文章
- MapReduce工作原理详解
文章概览: 1.MapReduce简介 2.MapReduce有哪些角色?各自的作用是什么? 3.MapReduce程序执行流程 4.MapReduce工作原理 5.MapReduce中Shuffle ...
- MapReduce工作原理图文详解 (炼数成金)
MapReduce工作原理图文详解 1.Map-Reduce 工作机制剖析图: 1.首先,第一步,我们先编写好我们的map-reduce程序,然后在一个client 节点里面进行提交.(一般来说可以在 ...
- <转>MapReduce工作原理图文详解
转自 http://weixiaolu.iteye.com/blog/1474172前言: 前段时间我们云计算团队一起学习了hadoop相关的知识,大家都积极地做了.学了很多东西,收获颇丰.可是开学 ...
- MapReduce工作原理讲解
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•TaskT ...
- MapReduce工作原理
第一部分:MapReduce工作原理 MapReduce 角色•Client :作业提交发起者.•JobTracker: 初始化作业,分配作业,与TaskTracker通信,协调整个作业.•Tas ...
- [转载] MapReduce工作原理讲解
转载自http://www.aboutyun.com/thread-6723-1-1.html 有时候我们在用,但是却不知道为什么.就像苹果砸到我们头上,这或许已经是很自然的事情了,但是牛顿却发现了地 ...
- Hadoop MapReduce工作原理
在学习Hadoop,慢慢的从使用到原理,逐层的深入吧 第一部分:MapReduce工作原理 MapReduce 角色 •Client :作业提交发起者. •JobTracker: 初始化作业,分配 ...
- django+uWSGI+nginx的工作原理流程与部署过程
django+uWSGI+nginx的工作原理流程与部署过程 一.前言 知识的分享,不应该只是展示出来,还应该解释这样做是为什么... 献给和我一样懵懂中不断汲取知识,进步的人们. 授人与鱼,不如授人 ...
- MapReduce工作原理图文详解
目录:1.MapReduce作业运行流程2.Map.Reduce任务中Shuffle和排序的过程 1.MapReduce作业运行流程 流程示意图: 流程分析: 1.在客户端启动一个作业. 2.向Job ...
随机推荐
- Java进阶(七)正确理解Thread Local的原理与适用场景
原创文章,始自发作者个人博客,转载请务必将下面这段话置于文章开头处(保留超链接). 本文转发自技术世界,原文链接 http://www.jasongj.com/java/threadlocal/ Th ...
- 导入mysql数据的时候提示Field * doesn't have a default value解决方法
项目使用django+mysql 在linux中使用的是mysql5.7,导入数据提示:Field * doesn't have a default value 想要解决问题就需要知道在mysql5. ...
- RecyclerView高速通用适配Adapter
RecyclerView Adapter 为RecyclerView提供更简单的适配器实现方式,不断更新完好中. Demo视频演示 GitHub地址 博客 使用 BaseViewHolder 的使用 ...
- Delphi语言怎样对自己定义类进行持久化保存及恢复 (性能远比json/xml高)
Delphi的RTL自身就带有一套非常好的资源持久化保存(IDE设计窗口时,保存为DFM格式及编译到EXE里面的资源文件)及恢复机制(EXE启动时对窗口资源的载入),那么应不是必需再额外用xml/js ...
- 六、Spring Boot Controller使用
在Controller中使用 @RestController 注解,该注解是spring 4.0引入的.查看源码可知其包含了 @Controller 和 @ResponseBody 注解.我们可以理解 ...
- 多线程day01
多线程作为Java中很重要的一个知识点,在此还是有必要总结一下的. 一.线程的生命周期及五种基本状态 关于Java中线程的生命周期,首先看一下下面这张较为经典的图: 上图中基本上囊括了Java中多线程 ...
- git忽略文件
.gitignore文件配置 ###################### # Project Specific ###################### /src/main/webapp/dis ...
- Python 项目实践二(生成数据)第一篇
上面那个小游戏教程写不下去了,以后再写吧,今天学点新东西,了解的越多,发现python越强大啊! 数据可视化指的是通过可视化表示来探索数据,它与数据挖掘紧密相关,而数据挖掘指的是使用代码来探索数据集的 ...
- selenium python自动化简明演示
1.selenium安装: pip install -U selenium参考:https://pypi.python.org/pypi/selenium#downloads2.下载firefox驱动 ...
- NFV、DPDK以及部分用户态协议研究
本文为作者原创,转载请注明出处(http://www.cnblogs.com/mar-q/)by 负赑屃 对我而言,这是一个新的领域,很有意思. 一.解释名词: NFV(Network Functio ...