python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)
上一卷中介绍了安装过程,现在我们开始使用这个神奇的框架
跟很多博主一样我也先选择一个非常好爬取的网站作为最初案例,那么我先用屌丝必备网站http://www.shaimn.com/xinggan/作为这一卷的案例,不用想有图,有字
第一步:
创建爬虫文件:

现在切换到scrapy_test的根目录下:

我们现在创建了爬虫文件,这个网页正常情况下就可以直接抓取,不像糗事啊,天猫啊需要到SETTING里去设置对抗ROBOT cookie user-AGENT这样的反爬手段
现在开始创建代码

现在在终端切换到爬虫文件的目录中
执行命令:
scrapy crawl crawler1 --nolog
--nolog是为了隐藏日志文件时我添加的命令语句,因为这个网页过于简单,所以为了方便数据的展示,我加了这句语句,但是如果抓取复杂的网站时我建议添加,一旦出问题可以立马发现问题的所在:
现在看下结果:
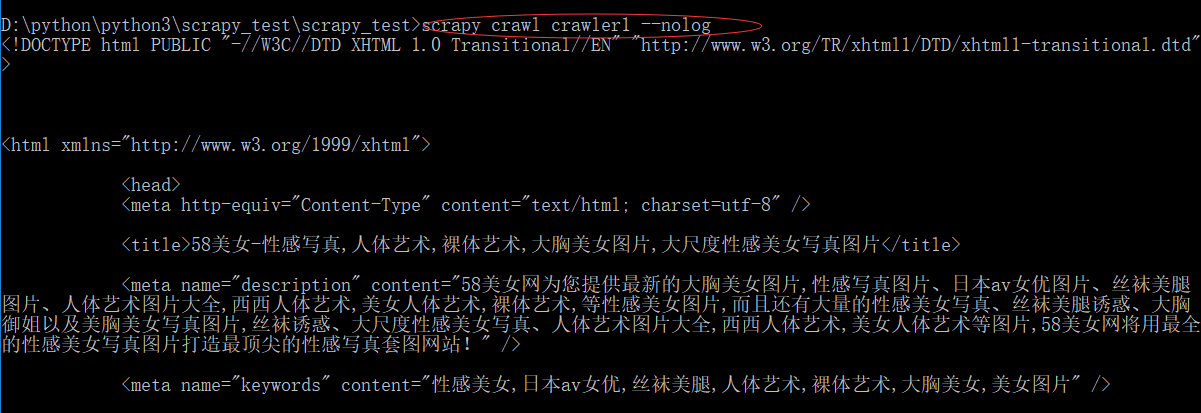
这样这个网页就爬了下来,但是数据内容不精准,我相信没有人会把别让人的所有网页代码拿来用,要用的是其中的数据,图片,视频,音频等内容
python3下scrapy爬虫(第二卷:初步抓取网页内容之直接抓取网页)的更多相关文章
- python3下scrapy爬虫(第四卷:初步抓取网页内容之抓取网页里的指定数据延展方法)
上卷中我运用创建HtmlXPathSelector 对象进行抓取数据: 现在咱们再试一下其他的方法,先试一下我得最爱XPATH 看下结果: 直接打印出结果了 我现在就正常拼下路径 只求打印结果: 现在 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- python3下scrapy爬虫(第九卷:scrapy数据存储进JSON文件)
将爬取数据存储在JSON文件里并不难,只需修改pipelines文件 直接看代码: 来看下结果: 中文字符恶心的很 之后我会在后卷中做出修改
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
之前我们做的数据爬取都是单页的现在我们来讲讲多页的 一般方式有两种目标URL循环抓取 另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源 话不多说全在代码里(因为刚才写 ...
- python3下scrapy爬虫(第一卷:安装问题)
一般爬虫都是用urllib包,requests包 配合正则.beautifulsoup等包混合使用,达到爬虫效果,不过有框架谁还用原生啊,现在我们来谈谈SCRAPY框架爬虫, 现在python3的兼容 ...
- Scrapy爬虫入门系列4抓取豆瓣Top250电影数据
豆瓣有些电影页面需要登录才能查看. 目录 [隐藏] 1 创建工程 2 定义Item 3 编写爬虫(Spider) 4 存储数据 5 配置文件 6 艺搜参考 创建工程 scrapy startproj ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
随机推荐
- LeetCode——787. K 站中转内最便宜的航班
有 n 个城市通过 m 个航班连接.每个航班都从城市 u 开始,以价格 w 抵达 v. 现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是找到从 src 到 dst 最多经过 ...
- 吴裕雄--天生自然 PHP开发学习:函数
<?php function writeName() { echo "Kai Jim Refsnes"; } echo "My name is "; wr ...
- Necklace HDU - 3874 (线段树/树状数组 + 离线处理)
Necklace HDU - 3874 Mery has a beautiful necklace. The necklace is made up of N magic balls. Each b ...
- #JS# 如何判断一个字符串是否为日期格式
var data = “2018-12-09”; //返回为false则是日期格式;isNaN(data)排除data为纯数字的情况(此处不考虑只有年份的日期,如‘2018’) if(isNaN(da ...
- 关于laravel的一些操作
1.创建控制器 eg: php artisan make:controller controllerName 如果是带命名空间需要创建控制器 则不需要加前面的 App/Http/Controlle ...
- SEO优化技巧
一.搜索引擎工作原理 当我们在输入框中输入关键词,点击搜索或查询时,然后得到结果.深究其背后的故事,搜索引擎做了很多事情. 在搜索引擎网站,比如百度,在其后台有一个非常庞大的数据库,里面存储了海量的关 ...
- 数字转中文大写=> 1234=> 一千二百三十四
# -*- coding: utf-8 -*- # 最大值:九兆九千九百九十九亿九千九百九十九万九千九百九十九 import re p = ['', '十', '百', '千', '万', '十', ...
- CkEditor - Custom CSS自定义样式
CkEditor是目前世界上最多人用的富文本编辑器.遇上客户提需求,要改一下编辑器的样式,那就是深入CkEditor的底层来修改源码. 修改完的样式是这样,黑边,蓝底,迷之美学.这就是男人自信的表现, ...
- iOS 直接使用16进制颜色
在做iOS开发时,一般我们会吸色,就是产品给的图我们一般会吸色,但是最近吸色时候,老大说有较大的颜色偏差,所以要求我们直接使用UI给出的额16进制颜色,你也可以搜索<RGB颜色值转换成十六进制颜 ...
- HDU重现赛之2019CCPC-江西省赛
本人蒟蒻,5个小时过了5道,看到好几个大佬AK,%%%%%%% http://acm.hdu.edu.cn/contests/contest_show.php?cid=868 先放大佬的题解(不是我写 ...