大数据之虚拟机配置和环境准备及hadoop集群搭建
一、VMnet1和VMnet8路由器
VMware-workstation软件选择默认安装时,会自动创建VMnet1和VMnet8路由器设备。(安装失败使用CCleaner清理vm软件)
VMnet1对应仅主机模式。如果在网络适配器-网络连接里面选择仅主机模式,那么Linux的虚拟网卡就会接入VMnet1路由设备,应该使用VMnet1设备子网IP段,一般情况下使用DHCP获取的IP地址就在子网IP段范围。
VMnet8对应NAT模式。如果在网络适配器-网络连接里面选择NAT模式,那么Linux的虚拟网卡就会接入VMnet8路由设备,应该使用VMnet8设备子网IP段,一般情况下使用DHCP获取的IP地址就在子网IP段范围。
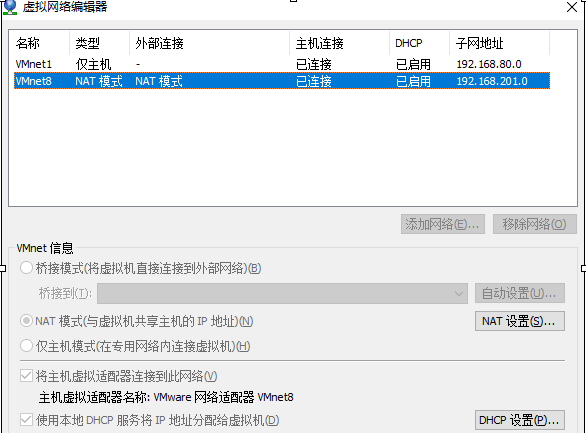
比如网络适配器-网络连接里面选择NAT模式,那么自动获取的IP地址范围就在192.168.201.128~254,如下:

二、各种模式网络配置详解
(1)桥接模式
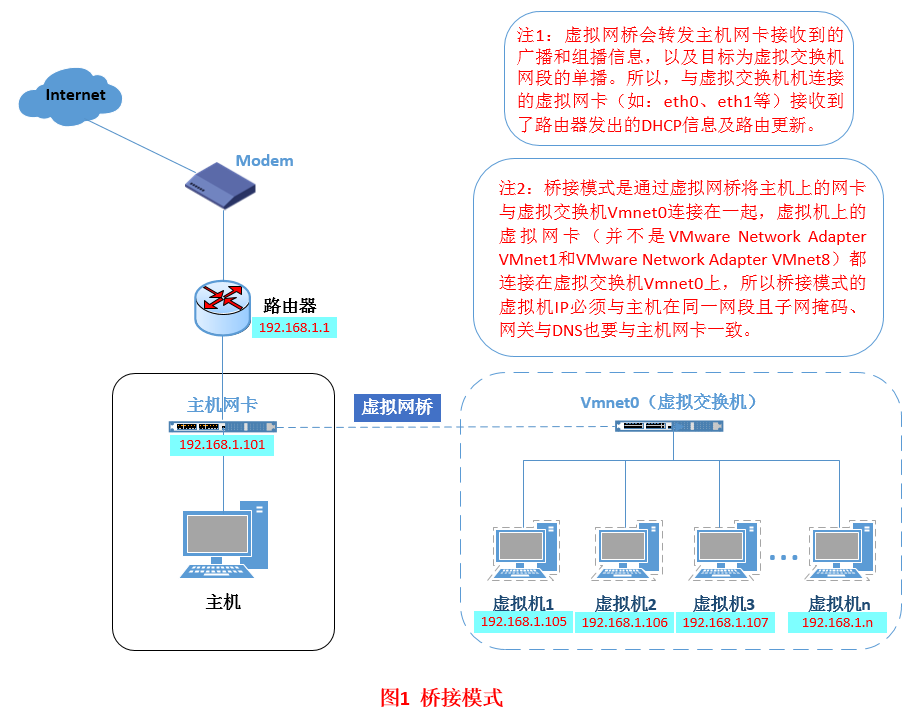
桥接模式就是将主机网卡与虚拟机虚拟的网卡利用虚拟网桥进行通信。在桥接的作用下,类似于把物理主机虚拟为一个交换机,所有桥接设置的虚拟机连接到这个交换机的一个接口上,物理主机也同样插在这个交换机当中,所以所有桥接下的网卡与网卡都是交换模式的,相互可以访问而不干扰。在桥接模式下,vm中的虚拟机与主机是一样的,都连在了和主机一样的路由中(相当于多台主机连接了同一个路由器上);其网络结构如图:
配置方法:
1、查找主机ip信息
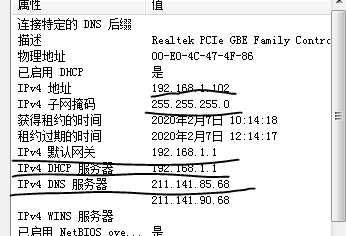
2、进入虚拟系统编辑网卡配置文件,命令为vi /etc/sysconfig/network-scripts/ifcfg-eth0
IPADDR=192.168.1.103 (设置虚拟机ip和主机在同一网段)
NETMASK=255.255.255.0 (设置子网掩码)
GATEWAY=192.168.1.1 (设置和主机相同的虚拟网关)
DNS1=211.141.85.68 (设置和主机相同的虚拟DNS)
3、保存重启,测试网络
(2)NET模式
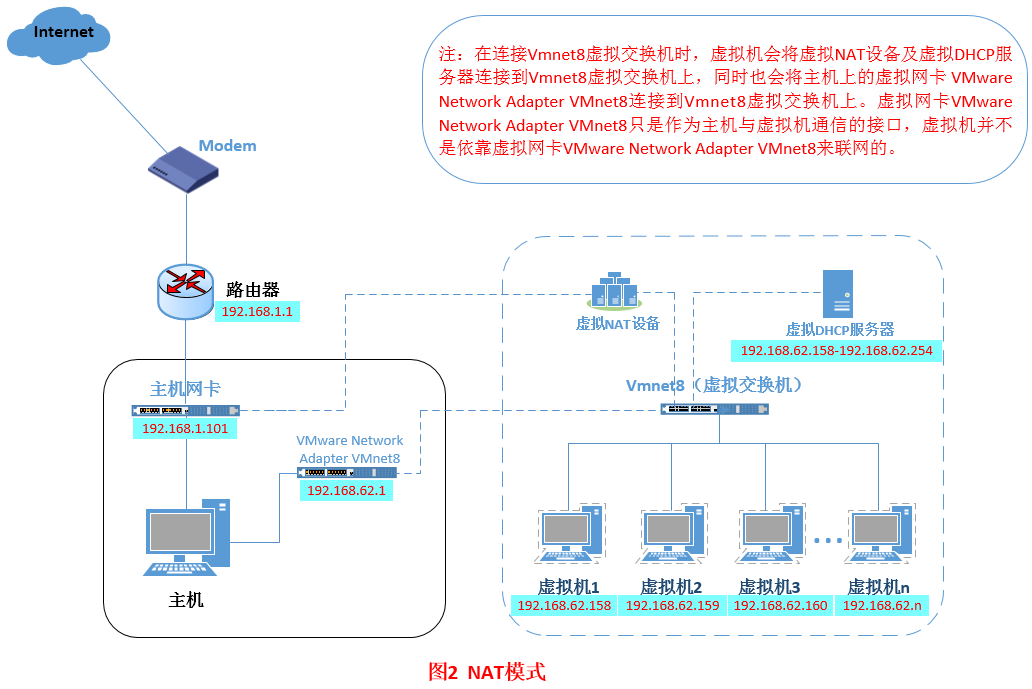
NAT模式借助虚拟NAT设备和虚拟DHCP服务器,使得虚拟机可以联网。在NAT模式中,主机网卡直接与虚拟NAT设备相连,然后虚拟NAT设备与虚拟DHCP服务器一起连接在虚拟交换机VMnet8上(vmnet8就相当于路由器),这样就实现了虚拟机联网。其网络结构如下:
配置方法:
1、设置虚拟机中的net模式,进入“虚拟网络编辑器”,
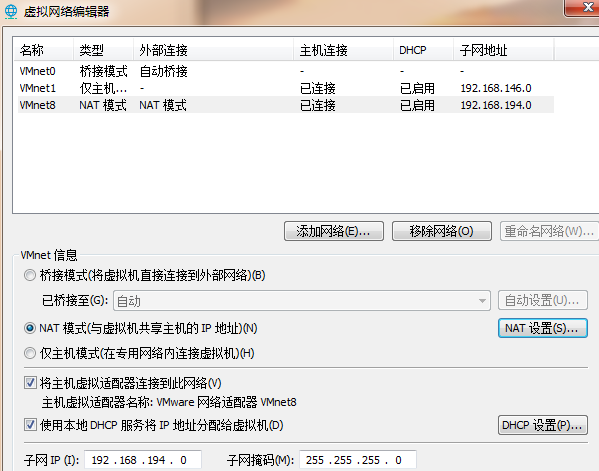
点开“NET设置”和“DHCP设置”

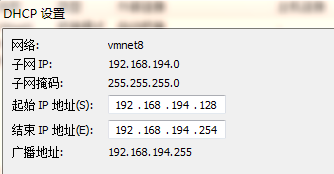
2、进入虚拟系统编辑网卡配置文件,命令为vi /etc/sysconfig/network-scripts/ifcfg-eth0
IPADDR=192.168.194.129 (设置虚拟机ip,要在DHCP规范的范围内)
NETMASK=255.255.255.0 (设置子网掩码)
GATEWAY=192.168.194.2 (设置虚拟网关)
DNS1=192.168.194.2 (设置虚拟DNS)
若是不清楚ip,网关和DNS如何设置,可以先使用动态获取,之后再在系统中查看,然后根据动态的配置设置静态配置
3、保存重启,测试网络
注意:
在net模式中,虚拟机之所以能够联网是因为NET设备和DHCP服务器的作用,和vmnet8无关,vmnet8的作用是主机与虚拟机之间的通信,如果禁用了vmnet8虚拟网卡,虚拟机还是能够连接外网,而使用xshell远程工具连接不上虚拟机;
(3)host-only(仅主机模式)模式
Host-Only模式其实就是NAT模式去除了虚拟NAT设备,然后使用VMware Network Adapter VMnet1虚拟网卡连接VMnet1虚拟交换机来与虚拟机通信的,Host-Only模式将虚拟机与外网隔开,使得虚拟机成为一个独立的系统,只与主机相互通讯。如果要使得虚拟机能联网,我们可以将主机网卡共享给VMware Network Adapter VMnet1网卡,从而达到虚拟机联网的目的。其网络结构如下:
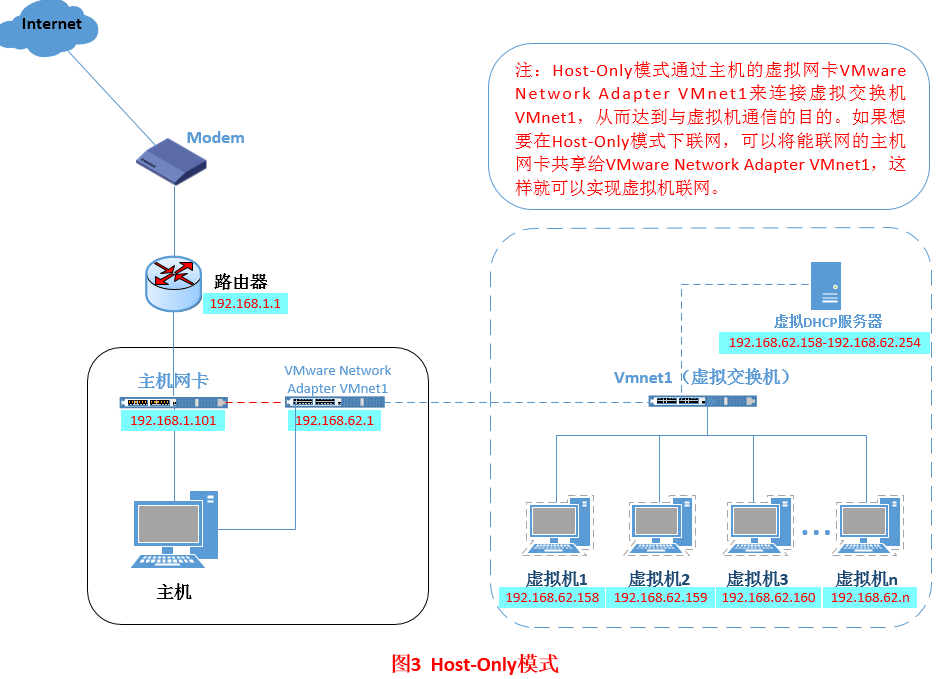
配置方法:
1、先采用net模式的配置方法
2、打开本地网络连接设备,设置网络共享(虚拟网卡共享主机网络)
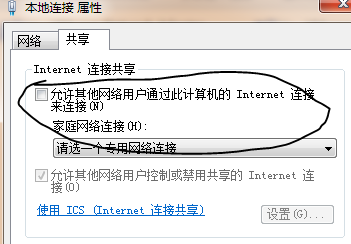
3、重新配置网卡,将vmnet1网卡作为虚拟机的路由(即:网关和DNS设置为vmnet1的ip)
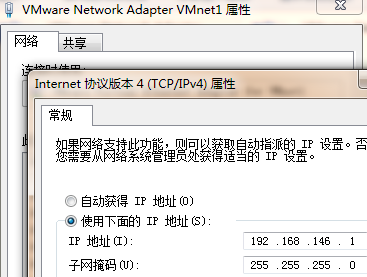
GATEWAY=192.168.146.1 (设置虚拟网关)
DNS1=192.168.146.1 (设置虚拟DNS)
4、保存重启,测试网络
三、网络配置
要搭建三个系统:master、slave1、slave2,先搭建master然后直接复制;
安装centos8系统(采用server安装方案,minimal安装方案也可,只是缺少一些东西),安装时要为硬盘设置50g的空间;
系统环境要做的工作:设置主机名、ip地址设为静态、主机名(localhost)和ip的映射,关闭防火墙(设置开机禁止启动);
1、ip地址设为静态--->>
进入虚拟系统master:
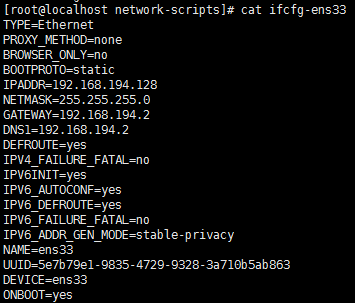
修改配置文件:vi /etc/sysconfig/network-scripts/ifcfg-ens33
(1)将IP协议设置为静态的(动态获取地址,BOOTPROTO=dhcp ,静态地址,则BOOTPROTO=static);
(2)将它网卡设置为开机自启(将ONBOOT=no改为ONBOOT=yes);手动激活网卡命令:ifconfig eth0 up,eth0表示网卡,(systemctl restart NetworkManager 命令重启网络服务);
(3)设置ip等信息:
IPADDR=192.168.194.128 (设置虚拟机ip,要在DHCP规范的范围内,三台虚拟机ip不同,其他都相同)
NETMASK=255.255.255.0 (设置子网掩码)
GATEWAY=192.168.194.2 (设置虚拟网关,route -n 查看网关命令)
DNS1=192.168.194.2 (设置虚拟DNS)
2、主机名--->>
修改文件: /etc/hostname (永久生效)
localhost.localdomain 改为 master
查看主机名命令:hostnamectl status
3、主机名和ip之间的映射--->>
修改文件: /etc/hosts
在文件末尾添加:192.168.194.128 master
如果集群里面有多台机器,那么要将集群中所有的ip和机器名的映射都添加进去,如:192.168.194.129 slave1
4、关闭防火墙-->>
关闭防火墙命令:systemctl stop firewalld
禁止防火墙开机启动命令:systemctl disable firewalld
查看防火墙状态:systemctl status firewalld
开启防火墙:systemctl start firewalld
设置防火墙开机自启:systemctl enable firewalld
四、hadoop集群的搭建
准备安装包:jdk8,hadoop-3.1.2,zookeeper
使用root权限解压并安装在 /usr/local/apps/ 文件夹下 : tar -zxvf 安装包名 -C /usr/local/apps/
(1)java安装:
安装java后配置java环境(环境配置在 /etc/profile 文件中)://在末尾添加
export JAVA_HOME=/usr/local/apps/jdk1.8.0_241
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
保存退出后,使用source /etc/profile 重新编译文件;
(2)hadoop安装:
解压到 /usr/local/apps/ 文件夹中,hadoop解压后文件夹简介:

bin和sbin都是一些执行命令,bin中主要是操作命令,sbin中主要是系统服务管理命令;
etc是hadoop配置文件所在的目录;
include、lib、libexec是与本地平台相关的库函数
share是hadoop主体功能区(含有jar包等),share中含有doc和hadoop两个文件夹

doc主要是网页版的hadoop手册,为了节约空间可以将其删除(rm -rf doc)

hadoop中主要是功能组件,每个组件中都含有jar包和与组件功能对应的网页
(2-1)hadoop伪分布式配置(单节点配置)
在启动hadoop之前,我们要配置hadoop环境,配置文件在hadoop安装目录的 etc/hadoop/ 文件夹中;
1、更改hadoop-env.sh文件,添加JAVA_HOME变量:

2、更改core-site.xml文件(hadoop运行时的公共配置):
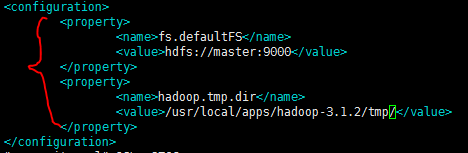
第一个参数(fs.defaultFS):表示hadoop默认使用的文件系统是哪一个;
第一个参数的值(hdfs://master:9000):默认使用hadoop自带的hdfs文件系统(hdfs://),hdfs是分布式的文件系统(系统中有主节点),之后指定主节点(master)和端口(9000)
第二个参数(hadoop.tmp.dir):表示hadoop服务进程使用的缓存目录(临时目录)
3、更改hdfs-site.xml文件:
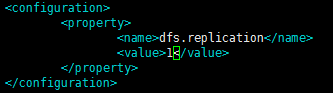
参数(dfs.replication):表示数据存储的副本数(数据容灾)
4、更改mapred-site.xml文件://hadoop2.x是mapred-site.xml.template,需要去除.template
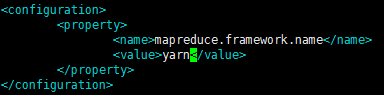
参数(mapreduce.framework.name):表示mapreduce是编程框架,但是并不能在hadoop里独立运行,它需要借助底层平台才能运行。
参数值(yarn):指定的mapreduce框架运行的平台
5、更改yarn-site.xml文件:
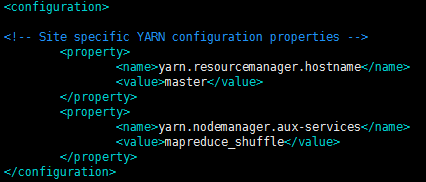
第一个参数(yarn.resourcemanager.hostname):表示yarn进程的主节点(resourcemanager)的主机名是什么; //上面的hdfs表示hdfs进程的主节点,它们并不冲突,它们可在同一机器中也可在不同机器中;
第二个参数(yarn.nodemanager.aux-services):表示NodeManager上运行的附属服务。需配置成mapreduce_shuffle(或mapreduce.shuffle),才可运行MapReduce程序;
6、更改workers文件://hadoop2为slaves,hadoop3是workers
此文件内容默认为 "localhost" ,表示默认从属节点为本机,如果更改了主机名(master),需要设定更改后的主机名,此处即将本机作为主节点又将本机作为从节点;
7、启动hadoop,测试是否搭建成功
格式化hdfs文件系统,进入hadoop安装目录下的bin目录( /hadoop-3.1.2/bin/ ),执行格式化命令 ./hdfs namenode -format ;(hadoop2.x使用的格式化命令: ./hadoop namenode -format)
手动启动hadoop中hdfs的namenode服务:进入hadoop安装目录下的bin目录( /hadoop-3.1.2/bin/ ),执行命令 ./hdfs --daemon start namenode (hadoop2.x 使用守护进程 hadoop-daemon.sh程序(/hadoop-3.1.2/sbin/):./hadoop-daemon.sh start namenode)
手动启动hadoop中hdfs的datanode服务:./hdfs --daemon start datanode (./hadoop-daemon.sh start datanode)
手动启动hadoop中hdfs的secondarynamenode服务:./hdfs --daemon start secondarynamenode (./hadoop-daemon.sh start resourcemanager)
手动启动hadoop中yarn的ResourceManager服务:./yarn --daemon start resourcemanager(./yarn-daemon.sh start resourcemanager)
手动启动hadoop中yarn的nodemanager服务:./yarn --daemon start nodemanager (./yarn-daemon.sh start nodemanager)
查看进程:netstat -nltp
使用自动化脚本启动hadoop:(sbin文件夹中)
执行命令启动hdfs的三个服务:./start-dfs.sh (采用了ssh协议,需要密码登录,建议采用免密登录方式)
执行命令启动yarn的两个服务:./start-yarn.sh(采用了ssh协议,需要密码登录,建议采用免密登录方式)
hadoop自动化脚本启动报错:
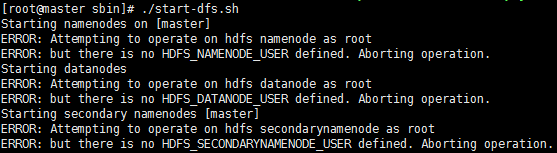
解决方法:
在start-dfs.sh和stop-dfs.sh中添加:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs #hadoop2.x是HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh和stop-yarn.sh中添加:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
免密登录需要设置密钥对:进入root目录,执行命令:ssh-keygen; 将生成的秘钥(公钥)拷贝到目标主机:ssh-copy-id 主机名/ip;
登录测试:ssh root@master (ssh root@ip)
(2-2)hadoop全分布式配置(多节点配置)
1、将master虚拟机中的hadoop拷贝到slave1和slave2中:scp -r /usr/local/apps/hadoop-3.1.2/ slave1:/usr/local/apps/
2、清除master中运行的数据(tmp为时的存储目录),这些数据中心含有master标记信息,如果不清楚就会出现冲突;(rm -rf tmp)
3、修改workers配置文件(hadoop-3.1.2/etc/hadoop/),添加从属节点(在master中)
4、将master的公钥拷贝到slave1和slave2中:ssh-copy-id slave1
5、测试启动:start-dfs.sh与start-yarn.sh,使用 jps 命令查看启动状况;
大数据之虚拟机配置和环境准备及hadoop集群搭建的更多相关文章
- Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程~(心血之作啊~~)
http://blog.csdn.net/licongcong_0224/article/details/12972889 历时一周多,终于搭建好最新版本hadoop2.2集群,期间遇到各种问题,作为 ...
- 大数据初级笔记二:Hadoop入门之Hadoop集群搭建
Hadoop集群搭建 把环境全部准备好,包括编程环境. JDK安装 版本要求: 强烈建议使用64位的JDK版本,这样的优势在于JVM的能够访问到的最大内存就不受限制,基于后期可能会学习到Spark技术 ...
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据 --> Hadoop集群搭建
Hadoop集群搭建 1.修改/etc/hosts文件 在每台linux机器上,sudo vim /etc/hosts 编写hosts文件.将主机名和ip地址的映射填写进去.编辑完后,结果如下: 2. ...
- 【Data Cluster】真机环境下MySQL数据库集群搭建
真机环境下MySQL-Cluster搭建文档 摘要:本年伊始阶段,由于实验室对不同数据库性能测试需求,才出现MySQL集群搭建.购置主机,交换机,双绞线等一系列准备工作就绪,也就开始集群搭建.起初笔 ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- 环境搭建-Hadoop集群搭建
环境搭建-Hadoop集群搭建 写在前面,前面我们快速搭建好了centos的集群环境,接下来,我们就来开始hadoop的集群的搭建工作 实验环境 Hadoop版本:CDH 5.7.0 这里,我想说一下 ...
- Hadoop集群搭建(完全分布式版本) VMWARE虚拟机
Hadoop集群搭建(完全分布式版本) VMWARE虚拟机 一.准备工作 三台虚拟机:master.node1.node2 时间同步 ntpdate ntp.aliyun.com 调整时区 cp /u ...
- 1.Hadoop集群搭建之Linux主机环境准备
Hadoop集群搭建之Linux主机环境 创建虚拟机包含1个主节点master,2个从节点slave1,slave2 虚拟机网络连接模式为host-only(非虚拟机环境可跳过) 集群规划如下表: 主 ...
随机推荐
- ROS学习笔记INF-重要操作列表
该笔记将重要操作的步骤进行列表,以便查询: 添加消息 在包中的msg文件夹中创建msg文件 确保package.xml中的如下代码段被启用: <build_depend>message_g ...
- 使用Hibernate+MySql+native SQL的BUG,以及解决办法
本来是mssql+hibernate+native SQL 应用的很和谐 但是到了把mssql换成mysql,就出了错(同样的数据结构和数据). 查询方法是: String sql = " ...
- 【LOJ2127】「HAOI2015」按位或
题意 刚开始你有一个数字 \(0\),每一秒钟你会随机选择一个 \([0,2^n-1]\) 的数字,与你手上的数字进行或操作.选择数字 \(i\) 的概率是 \(p[i]\) . 问期望多少秒后,你手 ...
- ROS-4 : ROS节点和主题
依照<ROS-3 : Catkin工作空间和ROS功能包>,创建catkin工作空间,并在起src下创建功能包ros_demo_pkg,依赖项为roscpp.std_msgs.action ...
- Jenkins + git + maven 安装
1.jenkins安装 sudo wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins-ci.org/redhat/jenkins.repo ...
- AC自动机 (模板)
AC自动机是用来干什么的: AC自动机是用来解决多模匹配问题,例如有单词s1,s2,s3,s4,s5,s6,问:在文本串ss中有几个单词出现过,类似. AC自动机实现这个功能需要三个部分: 1.将所有 ...
- python中logging的使用
什么是日志: 日志是一种可以追踪某些软件运行时所发生事件的方法 软件开发人员可以向他们的代码中调用日志记录相关的方法来表明发生了某些事情 一个事件可以用一个可包含可选变量数据的消息来描述 此外,事件也 ...
- iOS dismissViewControllerAnimated:completion:使用方法
我们都知道dismissViewControllerAnimated:completion:方法是针对被present出来的控制器的,一般我们这样使用:在一个控制器中present另外一个控制器A,然 ...
- vue :style 动态绑定style
<div class="right userPicture" :style="[{'background':`url(${userImg}) no-repeat c ...
- LInux的服务器编码格式的查看与更改
1.locale 命令查看字符编码 然后修改/etc/sysconfig/i18n,如改成中文编码: LANG=en_US.UTF-8 改为 LANG="zh_CN.GBK" 然后 ...