腾讯云Redis混合存储版重磅推出,万字长文助你破解缓存难题!
导语 | 缓存+存储的系统架构是目前常见的系统架构,缓存层负责加速访问,存储层负责存储数据。这样的架构需要业务层或者是中间件去实现缓存和存储的双写、冷热数据的交换,同时还面临着缓存失效、缓存刷脏、数据不一致等问题。本文是对腾讯云数据库高级产品经理邹鹏老师在「云加社区沙龙online」的分享整理,希望与大家一同交流
一、前言
在互联网和移动互联网两波浪潮的推动下,存储技术有了飞速发展。移动互联网用户在过去十年增长了10倍,用户的增长带动了数据量的指数级增长,因为激烈的市场竞争,企业和用户对应用程序的响应性能要求越来越高,在完美应对庞大的用户规模和海量数据集的同时保证优秀的产品体验,是数据库面临的挑战。
在机械硬盘普及的时代,企业需要通过缓存技术加速数据的访问,在SSD存储介质普及后,企业需要缓存技术支撑高并发和大吞吐,通过引入分布式缓存方案,提升应用程序性能,消除数据库热点。
但是缓存技术的引入增加了业务架构的复杂度,降低了开发效率,同时还面临着缓存一致性、缓存击穿、缓存雪崩等挑战。腾讯云数据库团队推出的Redis混合存储产品,融合缓存和存储的统一架构,彻底解决了缓存难题,帮助企业的研发人员聚焦业务逻辑,提升生产效率。
二、缓存的三座大山

1. 缓存一致性
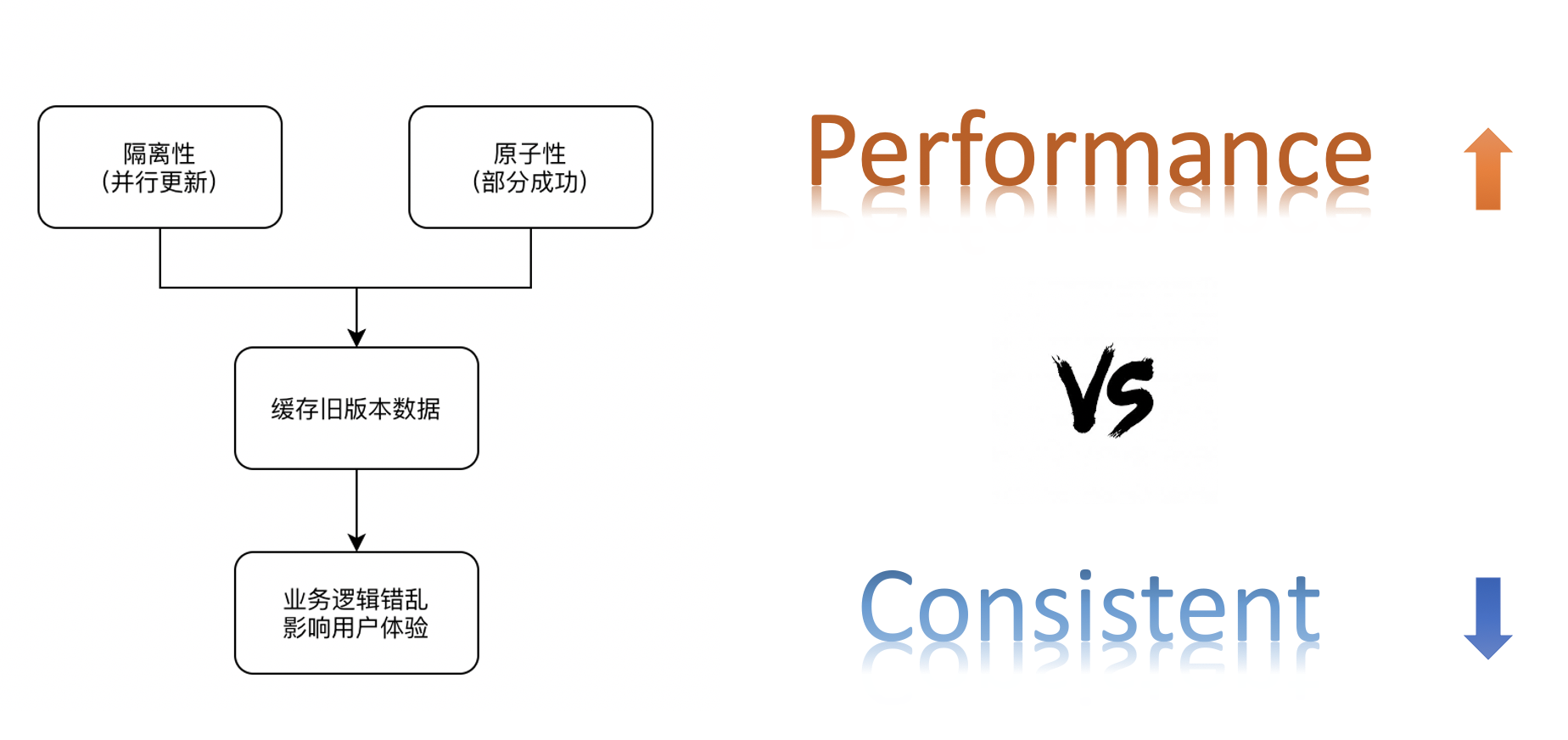
缓存一致性是指业务在引入分布式缓存系统后,业务对数据的更新除了要更新存储以外还需要同时更新缓存,对两个系统进行数据更新就要先解决分布式系统中的隔离性和原子性难题。
目前大多数业务在引入分布式缓存后都是通过牺牲小概率的一致性来保障业务性能,因为要在业务层严格保障数据的一致性,代价非常高,业务引入分布式缓存主要是为了解决性能问题,所以在性能和一致性面前,通常选择牺牲小概率的一致性来保障业务性能。
2. 缓存击穿
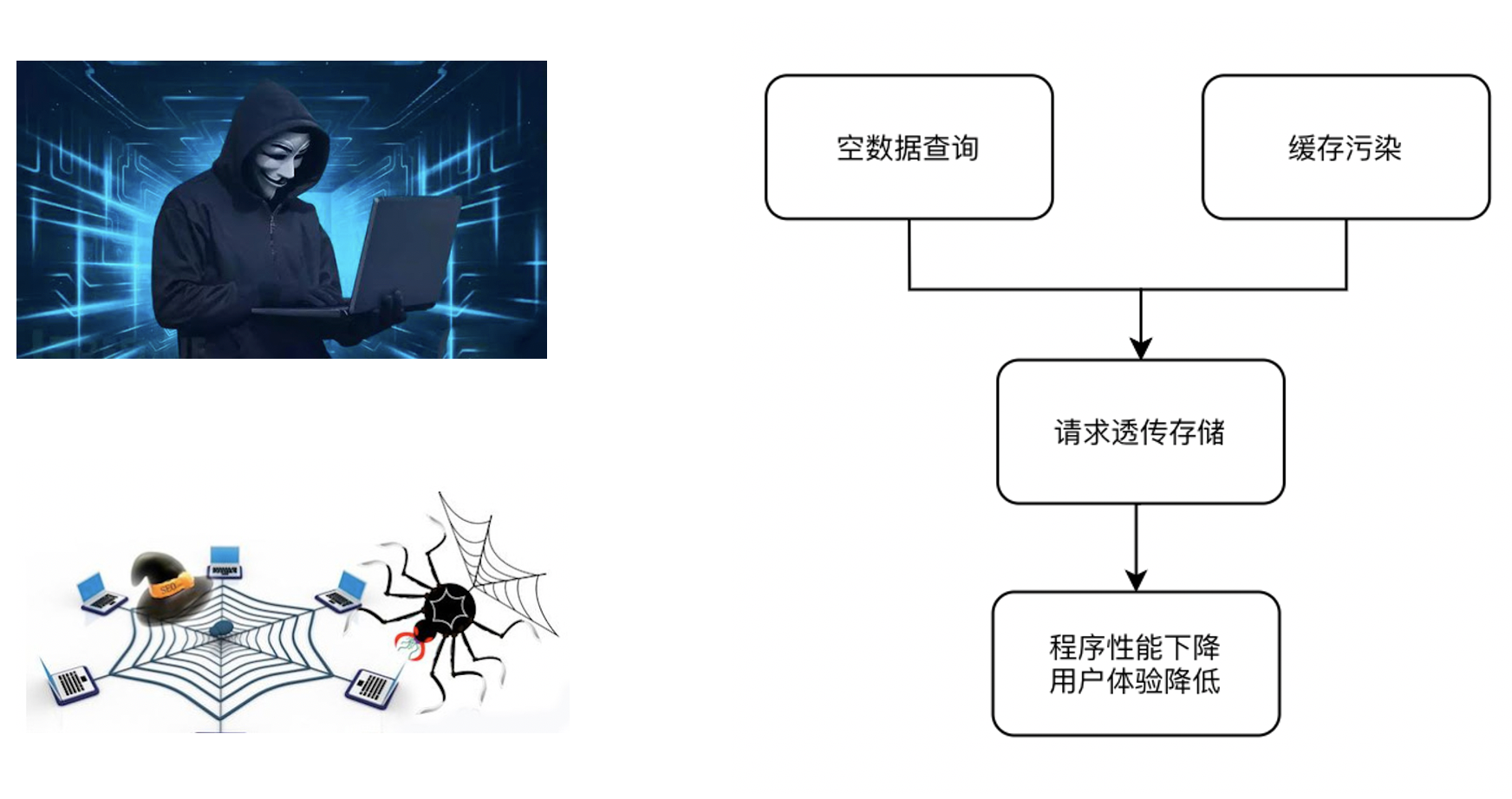
缓存击穿是指查询请求没有在缓存层命中而将查询透传到存储DB的问题,当大量的请求发生缓存击穿时,将给存储DB带来极大的访问压力,甚至导致DB过载拒绝服务。空数据查询(黑客攻击)和缓存污染(网络爬虫)是常见的引发缓存击穿的原因。
什么是空数据查询?空数据查询通常指攻击者伪造大量不存在的数据进行访问(比如不存在的商品信息、用户信息)。
缓存污染通常指在遍历数据等情况下冷数据把热数据驱逐出内存,导致缓存了大量冷数据而热数据被驱逐。缓存污染的场景我们目前还没有发现较好的解决方案,但是在空数据查询问题上我们可以改造业务,通过以下方式防止缓存击穿:
通过bloomfilter记录key是否存在,从而避免无效Key的查询;
在Redis缓存不存在的Key,从而避免无效Key的查询。
3. 缓存雪崩
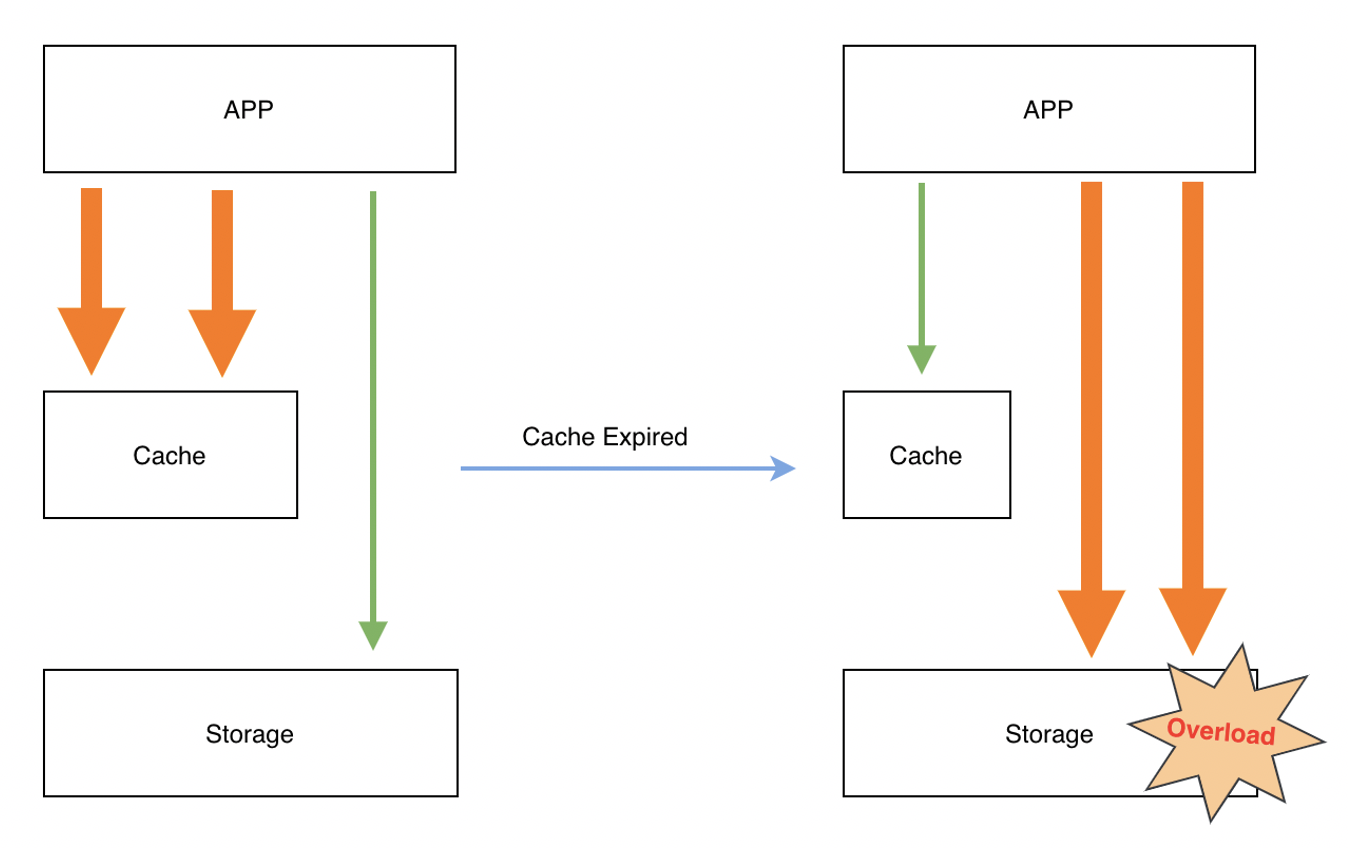
缓存雪崩是指由于大量的热数据设置了相同或接近的过期时间,导致缓存在某一时刻密集失效,大量请求全部转发到DB,或者是某个冷数据瞬间涌入大量访问,这些查询在缓存MISS后,并发的将请求透传到DB,DB瞬时压力过载从而拒绝服务。
目前常见的预防缓存雪崩的解决方案,主要是通过对key的TTL时间加随机数,打散key的淘汰时间来尽量规避,但是不能彻底规避。
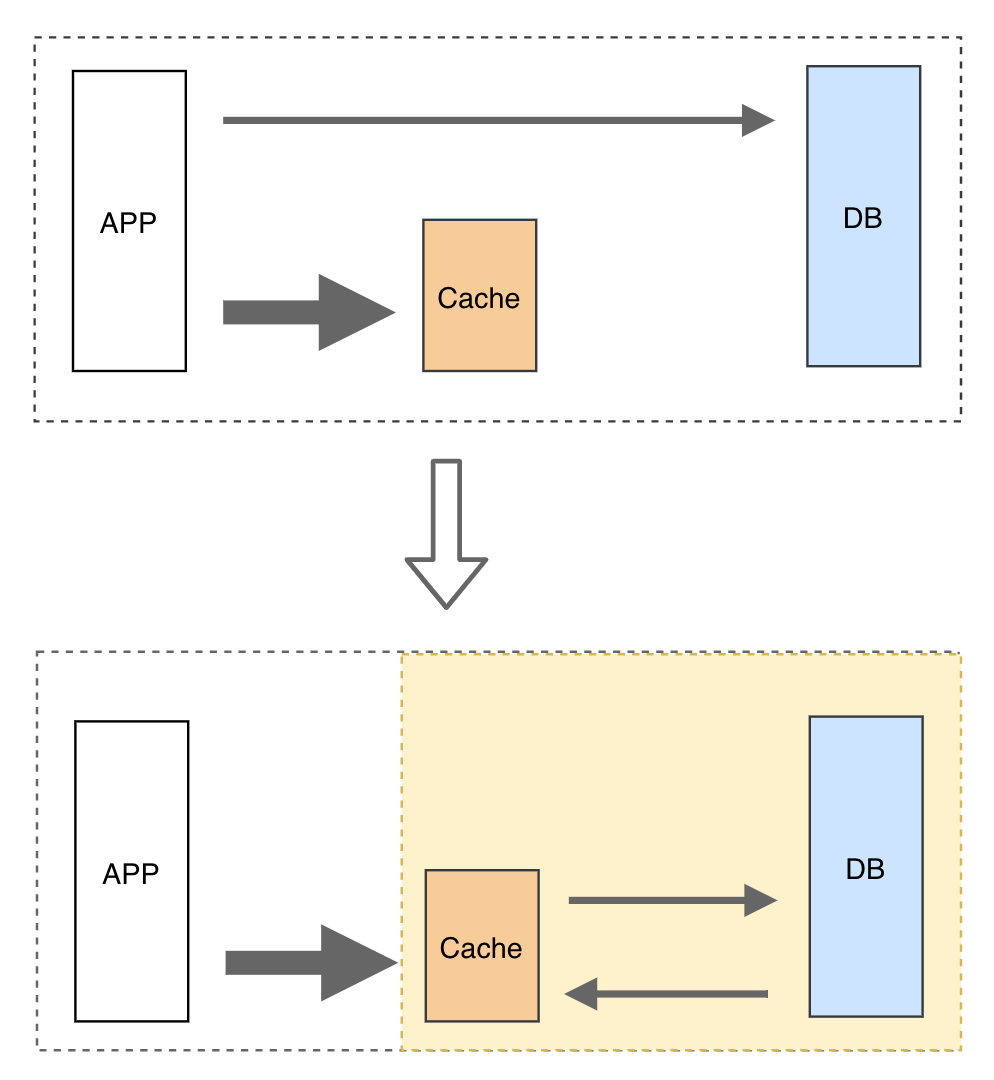
三、传统分布式缓存方案
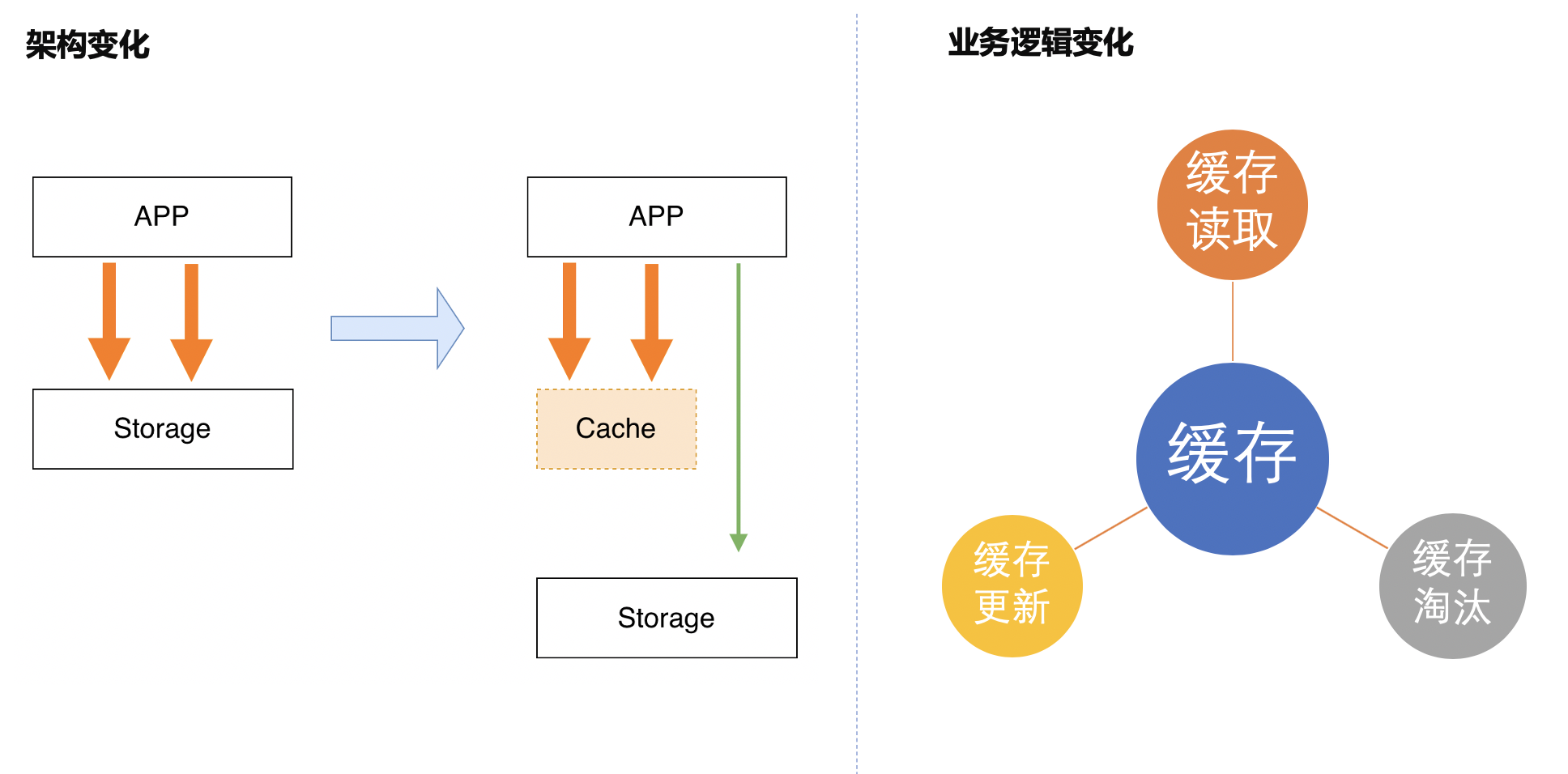
在引入分布式缓存后,我们的业务架构由原有两层架构(应用+数据库)变成了三层架构(应用+缓存+存储),缓存层缓存热数据,存储层负责全量数据持久化存储。
存储架构的变化要求业务对数据的存取逻辑进行相应调整,而且这个调整是巨大的。在缓存系统的选择上,常见的缓存数据库包括Memcached、Redis,目前使用最广泛的是Redis,存储数据常见的包括关系型数据库MySQL、PG、Oreacle、SQLServer等,NoSQL数据库MongoDB、Hbase等。
在引入分布式缓存后,业务逻辑需要做三个点的变化,缓存读取、缓存更新、缓存淘汰。
1. 缓存读取
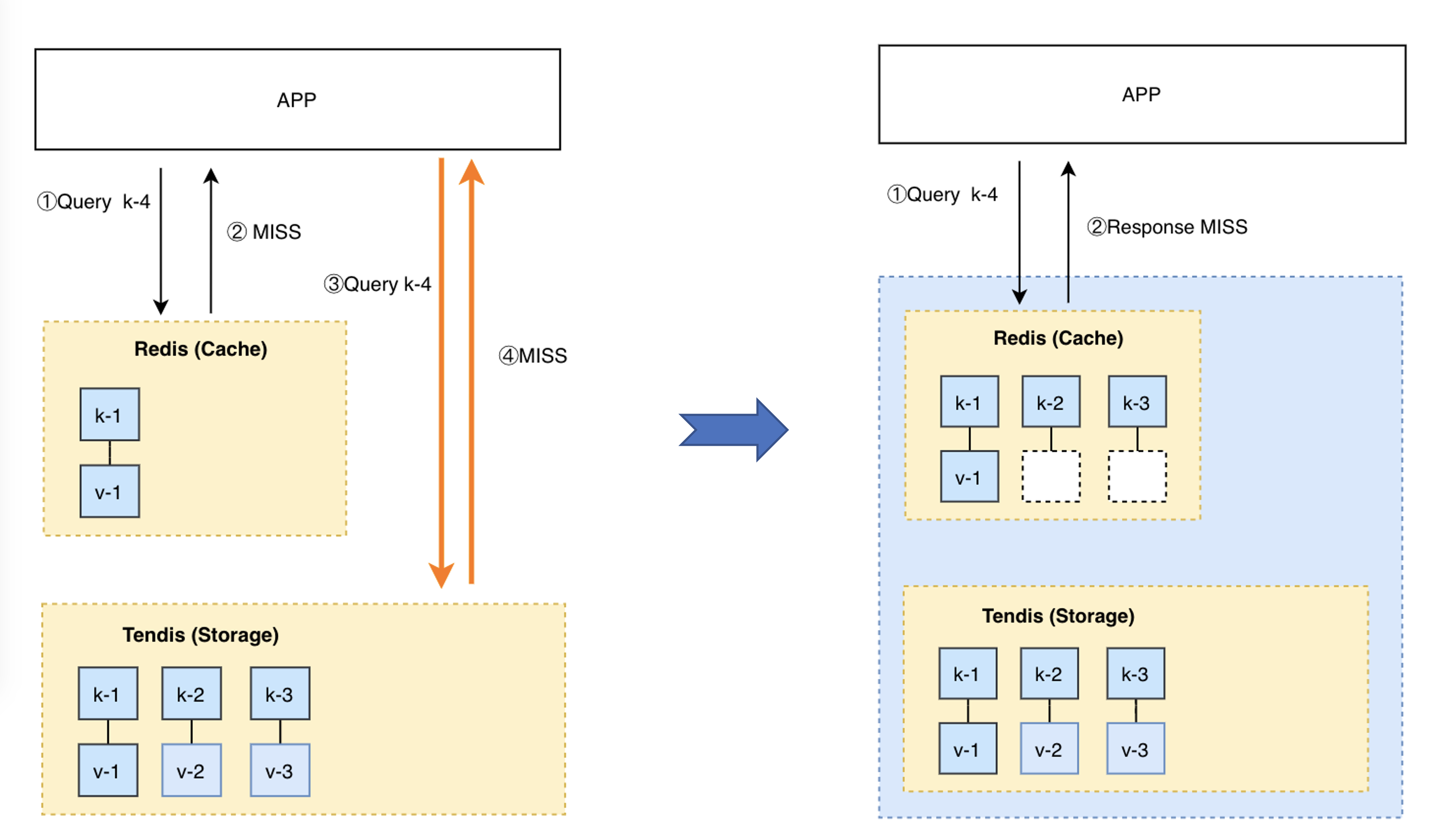
引入缓存层后,读数据就变得不是那么简单直接了,APP需要先去缓存读取数据,如果缓存MISS(数据没有被缓存),则需要从存储中读取数据,并将数据更新到缓存系统中,整个流程和代码如下所示:
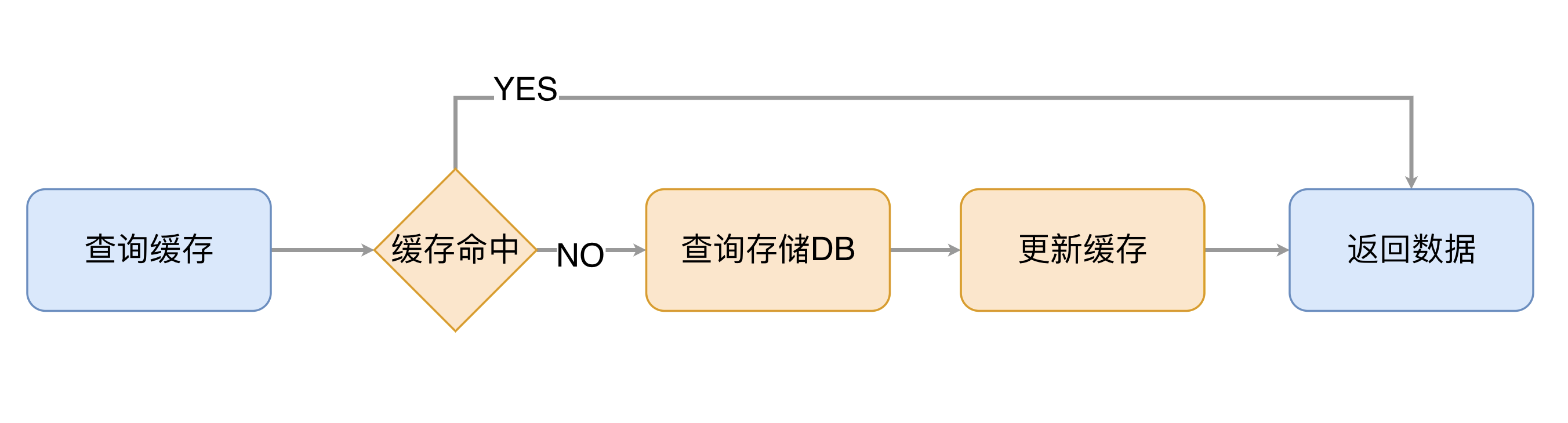
# Pythondef get_user(user_id):# Check the cacherecord = cache.get(user_id)if record is None:# Run a DB queryrecord = db.query("select * from users where id=?",user_id)# Populate the cachecache.set(user_id, record)return record# App codeuser = get_user(17)
示例代码
2. 缓存更新
我们把常见的缓存更新方案总结为两大类,业务层更新和外部组件更新,比较常见的是通过业务更新的方案。
(1)业务层更新缓存
a. 缓存更新的难点
刚开始接触缓存方案的同学可能会纠结几个点,先更新缓存还是先更新存储,缓存的处理是通过删除来实现还是通过更新来实现。
这里我们面临的问题本质上是一个数据库的分布式事务的问题,需要处理数据可靠性的挑战,并发更新带来的隔离性挑战,和数据更新原子性的挑战。
数据可靠性:如果要保证数据的可靠性,在业务逻辑成功之前,必须保障有一份数据落地,我们有以下两个选择:
先更新成功存储,再更新缓存;
先更新成功缓存,再更新存储,如果存储更新失败,删除缓存。
操作隔离性:一条数据的更新涉及到存储和缓存两套系统,如果多个线程同时操作一条数据,并且没有方案保证多个操作之间的有序执行,就可能会发生更新顺序错乱导致数据不一致的问题。
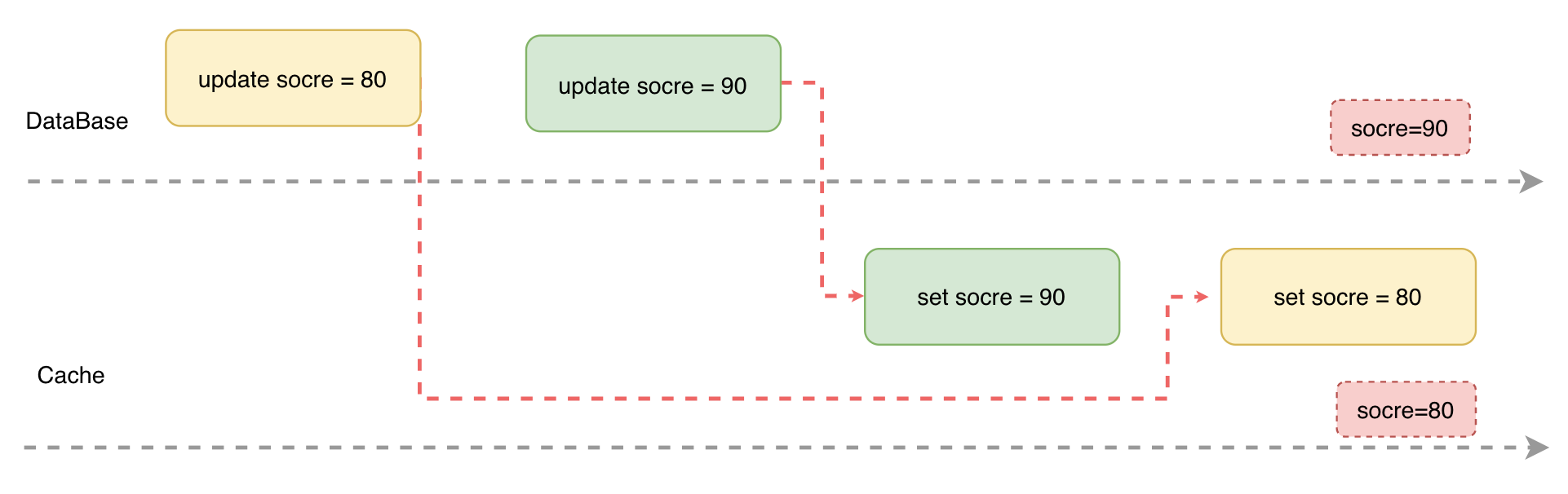
更新原子性:引入缓存后,我们需要保证缓存和存储要么同时更新成功,要么同时更新失败,否则部分更新成功就会导致缓存和存储数据不一致的问题。
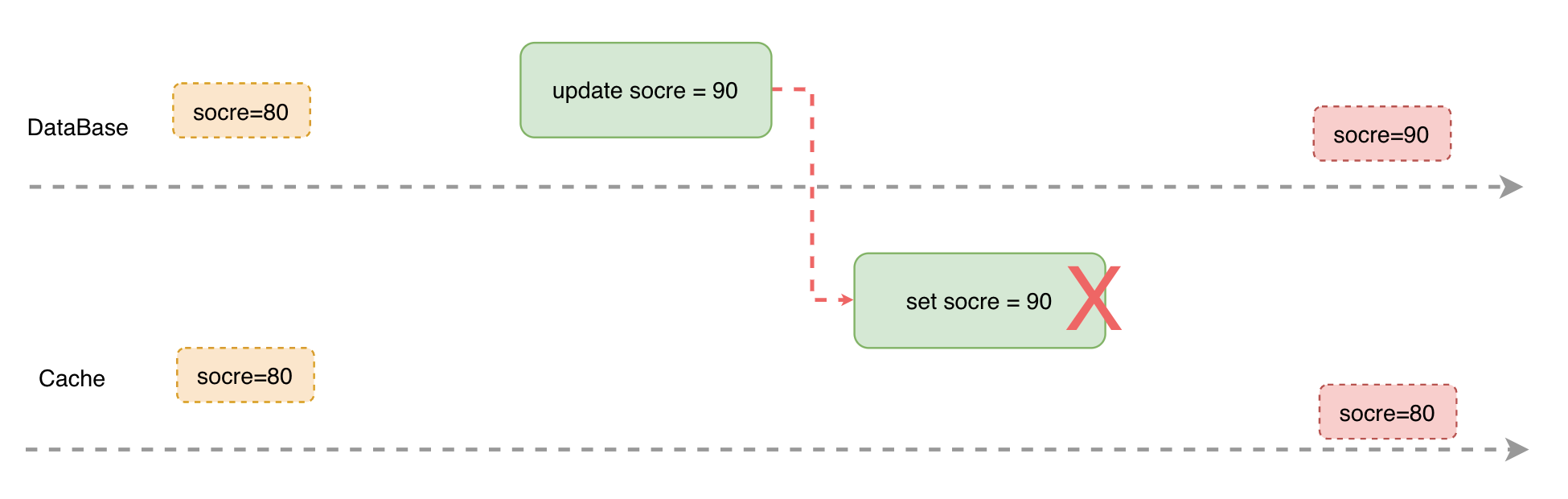
b. 业务层缓存更新方案
我们看到大多数的常见是选择以下方案,保障数据可靠性,尽量减少数据不一致的出现,通过TTL超时机制在一定时间段后自动解决数据不一致现象。
Step1:更新存储,保证数据可靠性;
Step2:更新缓存,2个策略怎么选:
惰性更新:删除缓存,等待下次读MISS再缓存(推荐方案);
积极更新:将最新的值更新到缓存(不推荐)。
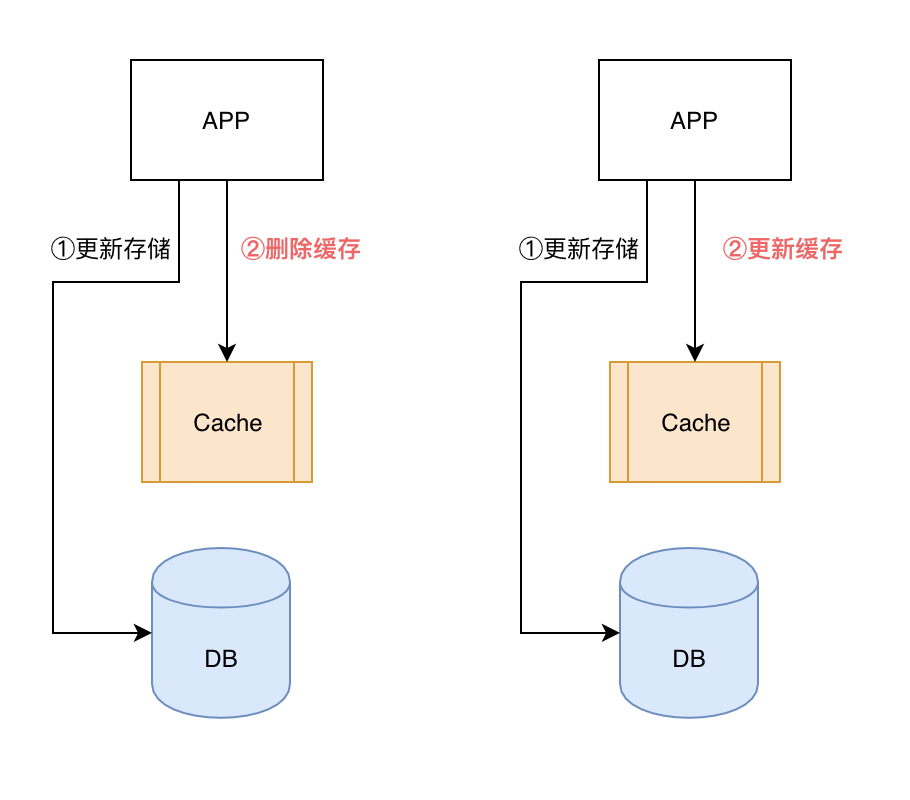
积极更新策略,缓存数据实时性更高,但是在缓存侧带来了更多的更新操作,这会提高更新冲突导致脏数据概率。
(2)外部组件更新缓存
a. 缓存MISS处理方案
在通过第三方组件更新的方案中,为了保障数据的一致性,避免对单条数据的并行更新,缓存的所有更新操作都需要交给同步组件,因此缓存MISS场景下的逻辑
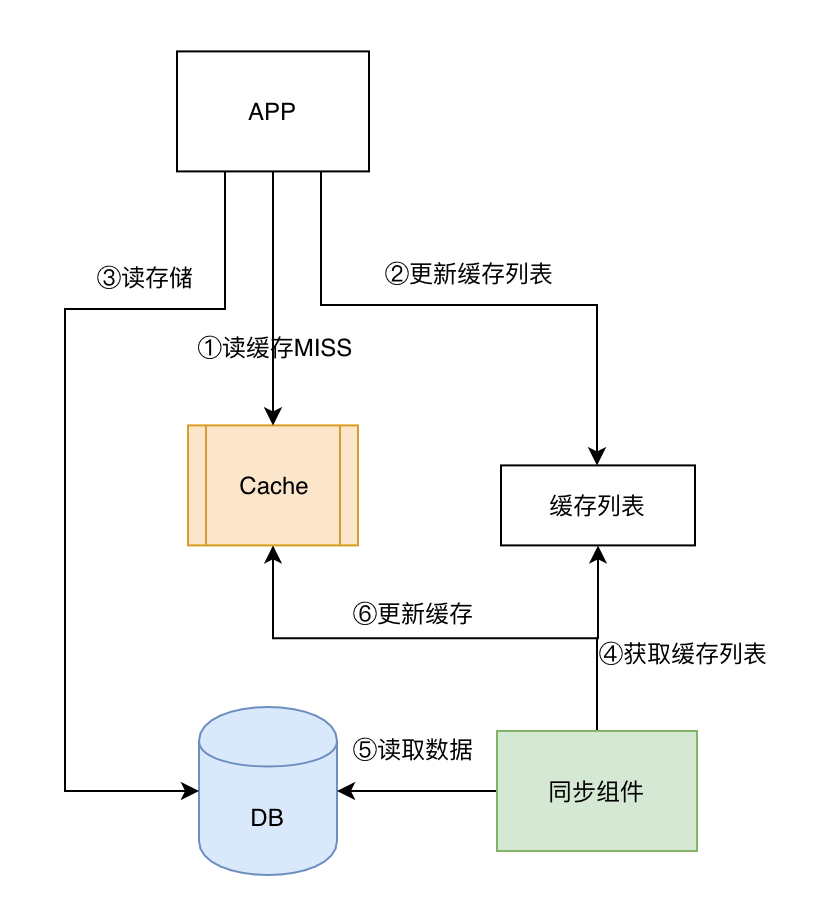
b. 缓存更新方案
先更新存储,由第三方组件异步更新缓存。该方案投入较大,只适合特定的场景,并且有以下3个难点:
需要监控存储的日志,或者通过Triger来监控存储数据的变更,需要对存储系统非常熟悉;
需要对更新进行过滤,我们的目的是缓存热数据,但是像DDL、批量更新这一系列的操作是不需要更新缓存的,要把非业务更新操作过滤;
同步组件需要理解数据,不通用。
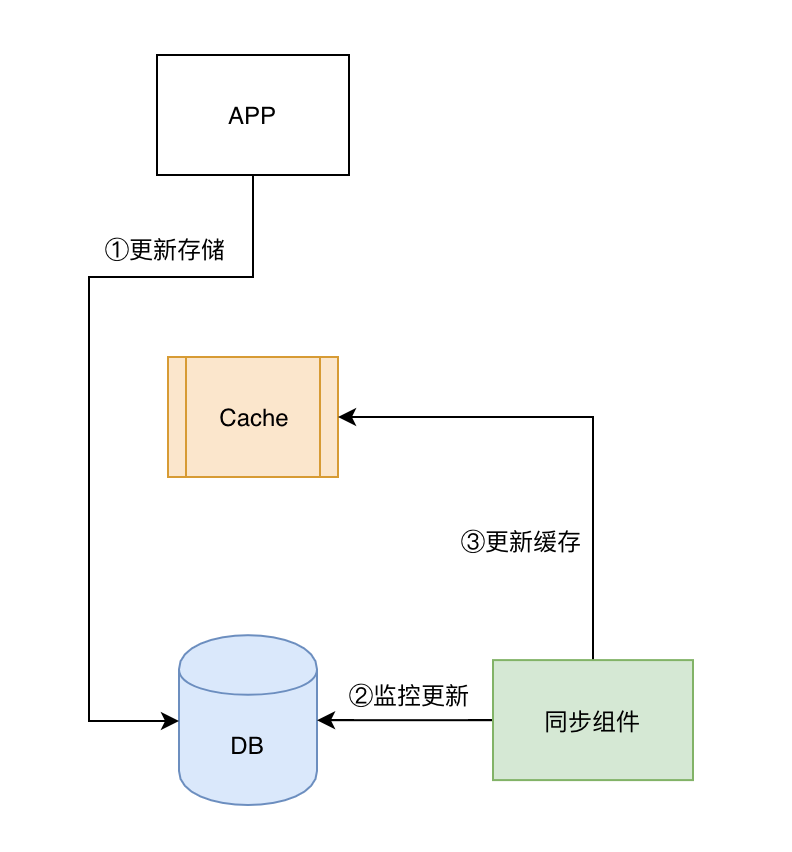
c. 其他缓存更新方案
在实际的生产中,我们还会看到很多先更新缓存,然后通过第三方组件更新存储的场景,但是这个方案也会面临数据一致性和数据可靠性的挑战,虽然不推荐,但是确实还是能看到有在使用这个方案的,我们拿出来探讨下。
这个场景数据可靠性,不及先更新存储的方案,但是写入性能高,延迟低;
这个方案APP和第三方组件都会更新Cache,会存在数据一致性的问题,因为很难保障两个组件更新的时序。
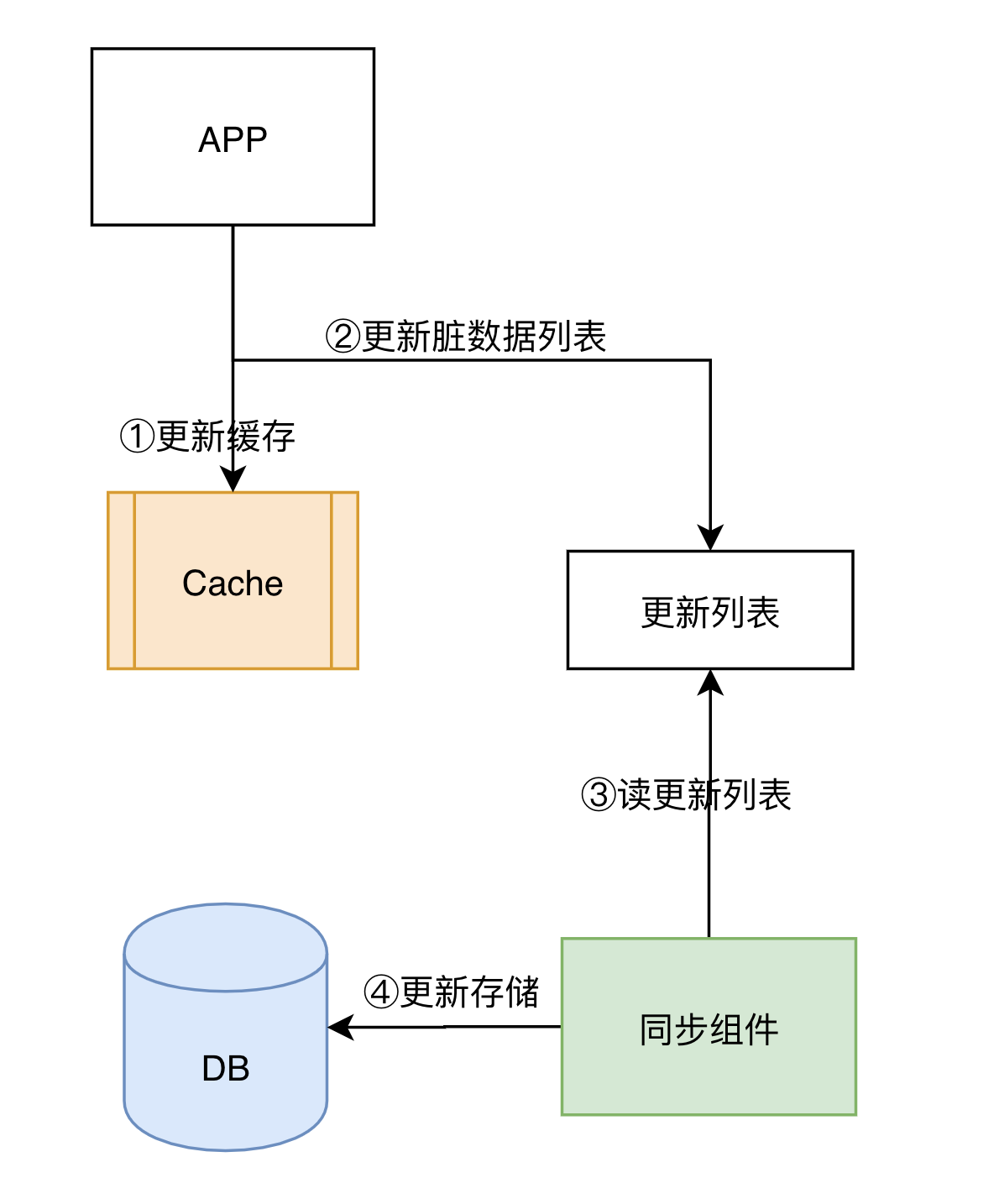
3. 缓存淘汰
缓存的作用是将热点数据缓存到内存实现加速,内存的成本要远高于磁盘,因此我们通常仅仅缓存热数据在内存,冷数据需要定期的从内存淘汰,数据的淘汰通常有两种方案:
主动淘汰:这是推荐的方式,我们通过对Key设置TTL的方式来让Key定期淘汰,以保障冷数据不会长久的占有内存。TTL的策略可以保证冷数据一定被淘汰,但是没有办法保障热数据始终在内存,这个我们在后面会展开;
被动淘汰:这个是保底方案,并不推荐,Redis提供了一系列的Maxmemory策略来对数据进行驱逐,触发的前提是内存要到达maxmemory(内存使用率100%),在maxmemory的场景下缓存的质量是不可控的,因为每次缓存一个Key都可能需要去淘汰一个Key。
四、腾讯云Redis混合产品介绍
1. 产品简介
腾讯云Redis混合存储版基于腾讯游戏线上运营多年的Tendis引擎打造。数据自动降冷,落盘压缩,最大可降低成本85%,100% 兼容Redis协议,可助力企业大幅提升生产效率,降低运营成本。
2. 产品特性
(1)研发效率+++
a. 混合存储解决方案
同样的三层架构,业务仅需要访问统一的Redis接口,让企业重新聚焦业务逻辑;
一套系统支撑,避免维护多套系统。
b. 解决缓存三大难题
一致性:通过内聚的设计,保障缓存和存储一致性
缓存击穿:All Keys In Memory设计,避免缓存击穿;
缓存持久:动态TTL设计,热数据即持久缓存。
c. 100%兼容Redis协议
100%兼容Redis协议,业务可顺畅接入。
d. 超高读写性能
高写入:为Redis定制的Rocksdb存储引擎,支持100万并发写入;
高读取:只能热数据缓存方案,提供1000万并发读取。
(2)运营成本-85%
a. 数据自动降冷
全量数据落盘,热数据缓存内存,相对全内存方案成本-85%;
数据自动降冷,成本可控。
b. 精准缓存
动态TTL淘汰方案,精准缓存热数据,有效避免缓存雪崩;
可控的冷数据缓存策略,快速解决缓存污染问题。
c. 数据压缩
Rocksdb独有的数据结构,保障性能和压缩效果平衡;
提供高达3~N倍(统计值)的数据压缩率 。
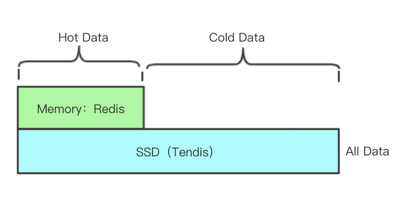
(3)突破内存限制
a. PB级KV存储解决方案
全量数据存储在磁盘,突破内存的容量限制;
计算&存储分离的存储架构,突破单机磁盘限制。
b. 高扩展性
水平扩展:支持水平扩展分片;
垂直扩展:秒级的垂直扩展存储;
读写分离:缓存层热点数据读写分离。
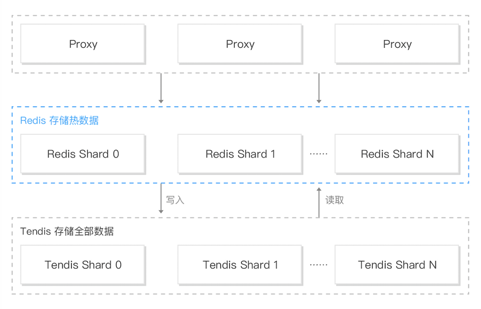
五、产品架构
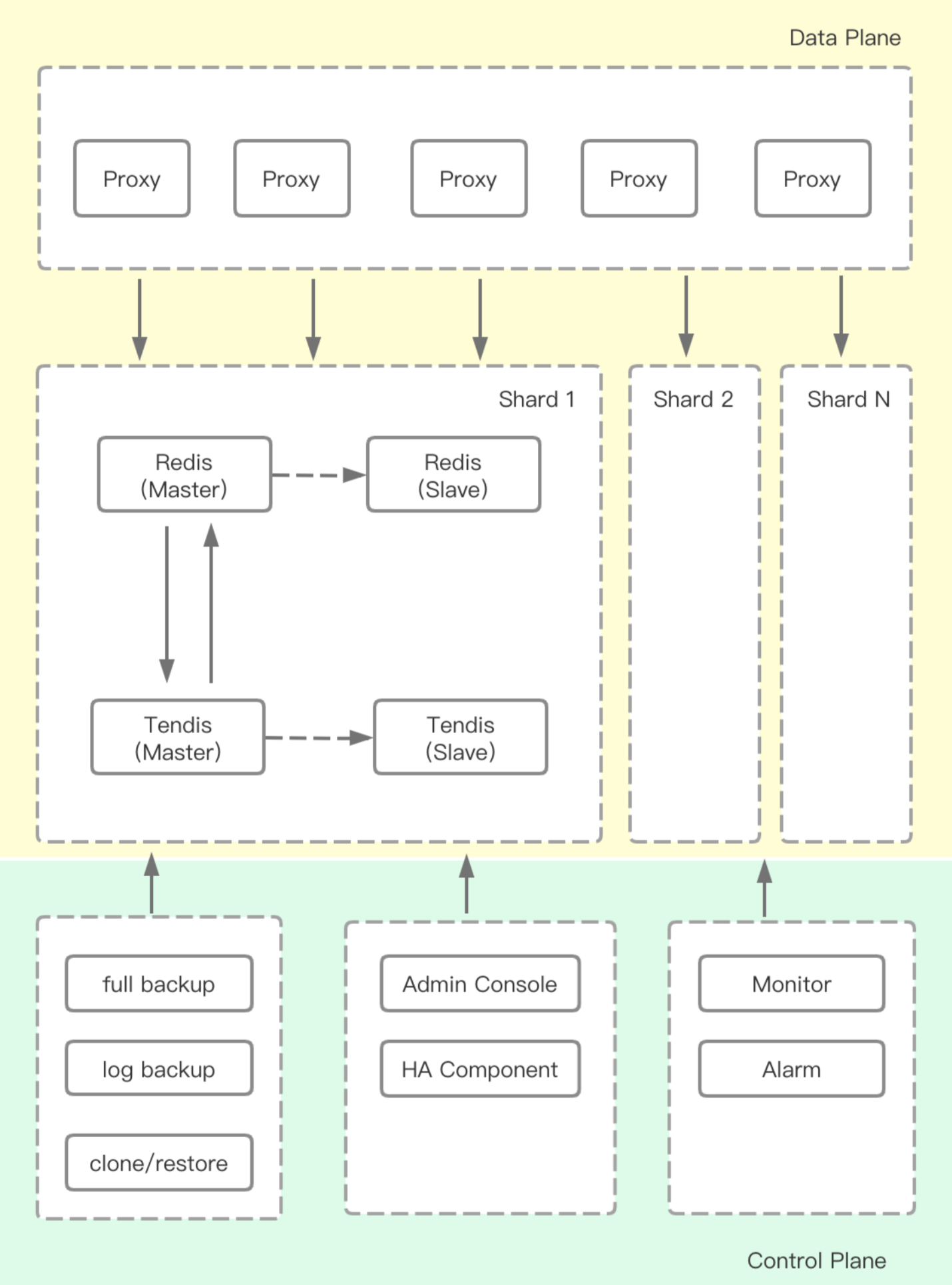
Redis混合存储版架构核心组件由Proxy、缓存Redis、存储Tendis组成,其中每个组件的功能介绍如下:
Proxy组件:负责对客户端请求进行路由分发,将不同的Key的命令分发到正确的分片,同时Proxy还负责了部分监控数据的采集,以及高危命令在线禁用等功能。
缓存Redis:缓存Redis组件源自于Redis 4.0 Cluster,为了支持冷数据自动降冷,我们对Redis进行了Value淘汰、写入数据同步Tendis、冷数据访问、主备热数据同步、按时间淘汰Value等核心功能的改造,改造后的混合存储版100%兼容Redis Cluster命令。
存储Tendis:Tendis是腾讯自研的KV存储引擎,一个兼容Redis协议的Rocksdb存储引擎,该引擎已经在腾讯集团内部运营多年,性能和稳定性得到了充分的验证。在混合存储系统中主要负责全量数据的存储和读取,以及数据备份,增量日志备份等功能。
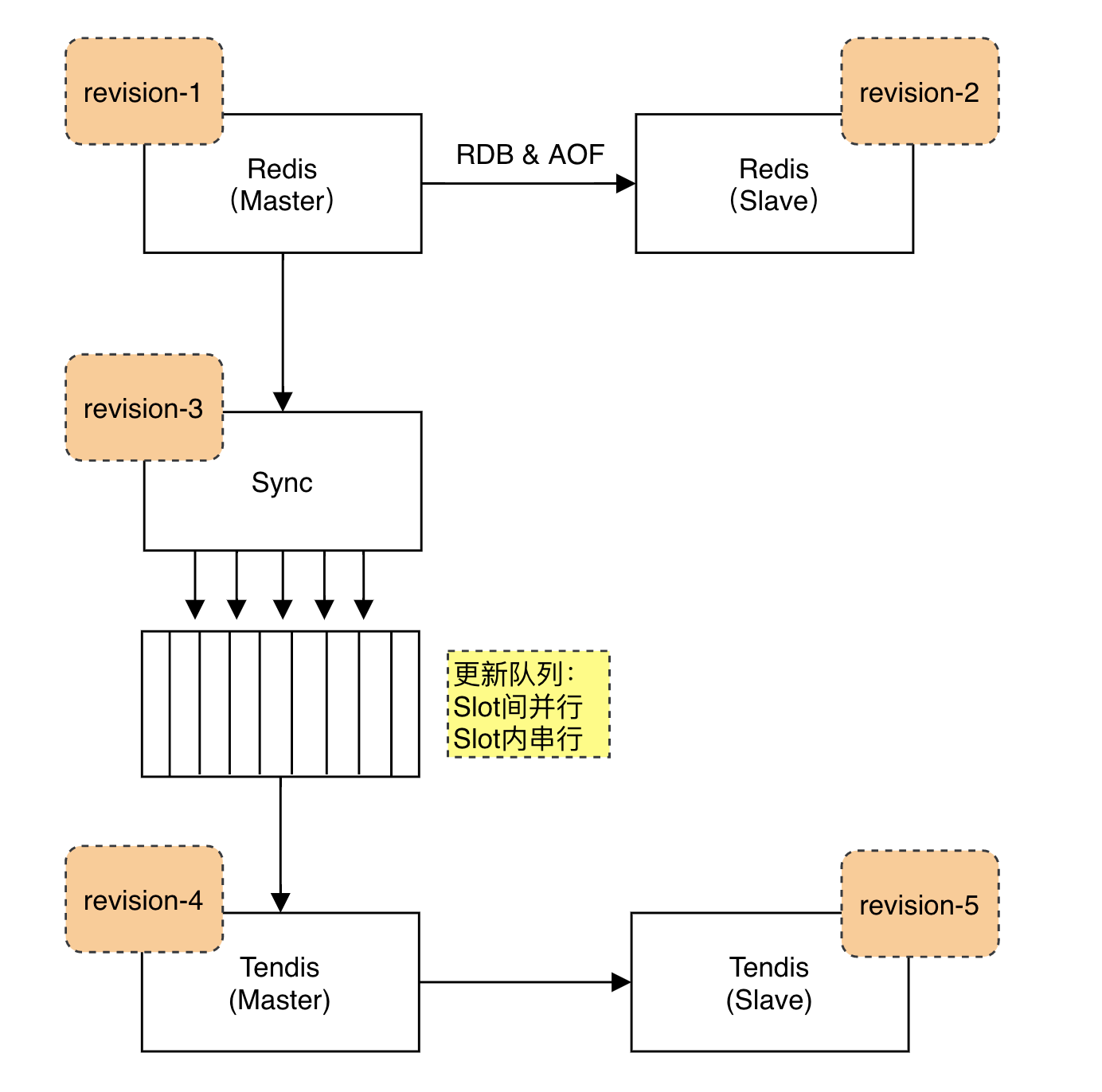
六、混合存储带你翻越缓存三座大山
1. 一致性解决方案
(1)并行更新(隔离性)
串行更新:单Key串行更新,保证时序;
并行更新:Slot维度并行更新,提升性能。
(2)部分成功(原子性)
系统联动:缓存&存储实时同步更新状态,通过revision同步状态;
部分成功:缓存更新成功,存储更新失败,触发HA,保障写入成功(日志幂等)。
(3)读一致性
revision:每个Key都带有一个revision,通过revision识别数据新旧;
淘汰控制:Redis不淘汰存储未更新的数据(Redis不淘汰revision <4的 数据),保证Redis不缓存旧版本数据。
2. 缓存击穿解决方案
(1)空数据查询
缓存所有Key 和 热数据Value,在缓存层拦截空数据查询,避免无效查询透传;
(2)缓存污染
可控的冷数据缓存策略,提供可配置的了冷数据缓存配置,例如业务可以配置在5分钟内访问次数超过3次才缓存在内存,可以有效防御缓存污染。
value-cache-policy-period(缓存策略时间窗);
value-cache-policy-threhold(value-cache-policy-period 时间窗内触发缓存的访问频率)。
3. 缓存雪崩解决方案
前面介绍到,缓存雪崩主要在两种情况会触发:
第一:大量热Key同时被淘汰,其中到原因是TTL设置时间接近。Redis混合存储版支持动态TTL,每次对Key的访问都会触发TTL更新,保障热数据持久缓存,有效规避缓存密集淘汰,我们通过两个参数配置来实现动态TTL:
value-eviction-policy:设置为time-to-eviction,启用全局动态TTL;
value-time-to-eviction:设施动态TTL的时长,取值范围[1h-180d]。
第二:一个冷Key瞬间产生大量的访问,由于缓存MISS导致大量请求透传到存储层,Redis混合存储版通过合并冷数据缓存的请求,同一个key的请求只访问一次存储层(Ten第三),可以将对存储层的访问降到最低,从而避免存储层过载。
4. 产品试用入口
Redis混合存储版已在腾讯云正式上线,扫描下方二维码即可进入免费试用申请页面(目前仅对腾讯云官网注册的企业账户开放申请)。

Q&A
Q:缓存击穿和缓存穿透有什么区别?
A:缓存击穿和穿透,我们可以理解为缓存层失效了,压力都到了存储层。
Q:还招人么?
A:在大量招,如果有对 Redis 了解的同学更加欢迎。请投至邮箱:lynzou@tencent.com
Q:接入这套解决方案多少钱?看来不是开源的,有计划没?
A:目前是在公有云公开售卖,能看到价格。我们也给大家提供了一个数字,最大可比用纯内存版节省成本 85%。后续有计划做开源,因为这块技术后续会往这个方向发展。
Q:Redis本身的内存及CPU消耗是个什么水平?
A:我把这个问题理解成 Redis 混合存储版对CPU和内存的消耗。你可以把它理解成现在我们混合群组里面缓存这一层的 Redis,会比原来纯 Redis 的消耗高一点点,因为涉及到了在里面引入revision。还有它的缓存和淘汰逻辑会更复杂,因为在这一个层面我们会去做缓存淘汰,所以光Redis 这个层面性能相对纯内存会有所下降。
我们目前能够看到,整个系统的稳定性能大概是在2万到3万,极限压测能够到四五万的样子,但是一旦到高负载压测的时候,磁盘的问题就出现了,在压到三万以上的时候就很可能会出现抖动,抖动带来的问题就是时延加大,甚至写入失败。
Q:数据压缩是否带来CPU的开销影响效率?
A:这是必然的。我们在空间和时间上面肯定都有换算。
目前来看,我们看到压缩的性能消耗还是其次的, Tendis 的主要开销除了传统的写入。RocksDB有一个compaction,它所有的请求都会顺序写入,然后再分级进行合并。这个合并的开销是蛮大的,合并的目的是为了合并存储空间。
所以大家在使用这个版本的时候,可能会碰到磁盘空间是一个曲线不停的在变化,一会大一会小。在写入的时候肯定会变大,过一会儿又会自动变小。这是因为 compaction 在合并时候的一个机制。
Q:这个和Redis本身处理空查询有什么区别?
A:Redis 本身没有处理空查询的能力,通常需要业务去使用布隆过滤器等方案来处理空查询。
目前有一些的业务方案是:如果查到一个缓存是空的,我们把key丢到缓存中,把它置为一个空的value,下一次查询时会查询是命中,并且返回的值是空的,这样就可以解决这个问题,但是需要业务层去开发写逻辑才可以,而我们直接就把这部分的事情做了。
Q:请问冷数据value为空(只缓冲key), 与该key的真实value为空,两者如何判断?
A:我们在做开发的时候有一个逻辑,会有一个标识位,在Redis 中通过这个标识位就可以判断是被淘汰了还是为空。
Q:老师能不能介绍一下备份机制呢?
A:目前混合存储板的主要场景还是存储,这个版本的备份机制是通过RocksDB来实现的。所以备份的是RocksDB 的SST文件。这个备份和MySQL的备份机制是一样的,备份全量的数据和增量的日志。所以混合存储板可以像MySQL一样支持按时间点回档,并且还有一个好处。很多数据库在备份的时候会先锁个表把全量的数据拷出来,不管是用逻辑还是物理的方式,然后再去备份增量的数据。这样备份很耗性能和空间。但RocksDB有一个好处,就是它每一次的写入都是增量的,做全量备份的时候直接切一个快照,然后把在这个点之前的文件全部直接拖走就可以,基本上是秒级就可以实现全量备份。全量备份和存量备份结合起来就可以实现任意时间点的回档。
Q:Redis混合存储适用于哪些应用场景,哪些场景不适用?
A:两个推荐:
需要自带缓存加速的KV存储场景,比如Redis+MySQL的架构,但是你又不需要MySQL的复杂查询,仅仅是通过MySQL实现数据可靠性存储;
分布式大容量KV存储场景,TB甚至数百TB级别的分布式KV存储方案。
两个不推荐:
纯缓存场景,混合存储由于引入磁盘引擎,冷数据的访问在高负载情况下可能会存储时延大的问题,没有办法像内存版Redis一样保证稳定的访问时延,同时这个版本的性能要明显的低于内存版本,特别是写入性能会收到磁盘的限制;
计算密集场景,如果你是计算密集的场景,并且数据不存储冷热分界,这个也不推荐。
Q:前面说Redis数据有版本号,如果没有落地就不会失效,防止查询存储层的脏数据。如果这个时候Redis出故障呢?数据丢了呢?
A:这个问题不是一致性的问题,而是可靠性的问题。Redis混合存储版在可靠性方面有两个可选选项。
第一个性能优先是优先,先写缓存,异步去写Tendis。如果这个时候Redis挂了,并且Redis 的从机没有收到最新的数据,这个时候就可能会丢失数据。这就和MySQL异步复制一样,会存在没有同步的数据被丢掉。所以这种场景下的可靠性和MySQL异步复制是一样的。
接下来还会提供一个版本,就是每一次写入的数据后会更新Tendis,Tendis更新OK之后会返回ACK,Redis收到ACK之后才会告诉应用程序更新成功。如果更新Redis成功、更新Tendis失败,就会把更新的数据失效掉。这样就能保证缓存和存储在可靠性上能够做到一致。
Q:在访问缓存层和数据层之前将存在的key用布隆过滤器提前保存起来,做第一层拦截,但是代码维护感觉复杂 有什么别的方案吗?(千万级数据集)
A:空数据查询的时候,通常使用的一个方案是在前面加过滤器,用过滤器拦截掉不存在的key。Redis混合存储版会在内存里面缓存所有的key,空数据在缓存的时候就直接被拦截了,不会到达存储层,这是我们现在的一个解决方案。
Q:灾备是怎么处理的,全依靠腾讯云吗?
A:腾讯云的Redis内存板正在做一个全球同步的版本,无论你的灾备异地只读还是多活都能够支持,在内存版之后,也会逐步去支持混合存储版,也就是把代码同步到混合存储版,到时候混合存储版也能做到存储的灾备、异地的灾备以及异地多活的架构。
Q:是否可以自建机房,对服务器有什么要求,必须是固态硬盘吗?
A:这个问题我理解为混合存储版能不能够支持私有化的部署。后面我们是有私有化部署的计划,在公有云上我们的版本成熟后,就会往专有云的版本去输出。对于是否必须是固态硬盘,目前来看主要是取决于业务需求,如果性能要求高,肯定要求固态硬盘,如果对性能要求不高,传统的机械磁盘也OK。
Q:关于分布式锁咱们的产品有自己的实现方式么?
A:现在大部分都是用redlock用的多,更优雅的是用CAS的原子命令去实现。后面我们也会去支持CAS相关的原子命令。
Q:cache节点是单点吗,cache节点故障检测/容忍和恢复的细节过程是什么?
A:首先,cache节点不是单节点,是个主备的架构。而且我们会支持一组多备去扩展读性能的架构。节点故障的检测/容忍和恢复的细节,Redis是一个Redis cluster,本身自己会进行简单的检查,外部也会有一些机制,比如check物理机或者内存块去检查。和纯内存的Redis高可用架构是一样的。
这里还有一个细节,因为这个版本我们引入了Tendis,所以在Redis HA的时候,我们会去check存储和缓存的数据的版本,有可能会从存储里面去刷数据,也就是我们的缓存版本会低于存储的版本。
Q:Redis更新后什么时候发起Tendis的异步更新,cache节点故障下,在还没有更新Tendis情况下,数据可能丢失吗?
A:Redis 的更新目前是异步更新到Tendis。目前数据的可靠性有两个版本,第一个是我们刚才介绍到的性能优先的版本,它是异步更新的。如果Redis故障并且数据没有刷到Tendis,而且从机也没有复制这个数据,那么这个数据是会被丢掉。原理就等价于MySQL的异步复制,保证数据的可靠性。
Q:同步组件实现目前选择什么方案?
A:目前的同步组件是自研的一个方案,大致的原理是从AOF复制数据,再把一些数据拆分同步到Tendis。
Q:请问一个更新操作在进行到哪一步会向客户端返回成功?主从架构下,数据同步到slave是异步的吗?如果数据还未同步到slave而master宕机,数据是否有丢失风险?
A:异步复制的版本中,只要写入成功之后就会直接返回,如果是同步复制的逻辑,会在更新Redis并且更新Tendis成功之后,才会返回。
Q:Redis的内存大小和tendis的磁盘大小,两者比例是多少?是否可以配置?
A:目前我们提供的是一个分布式的,也就是多分片的一个架构。Redis的内存和Tendis 的磁盘两者是可配的,而且是可调整的。这个配置是自己可调的,可以在腾讯的控制台直接拖你的磁盘,选择什么样的规格。
Q:compaction的过程会不会出现短暂的相应延时较高?
A:如果存储引擎写入的负载非常高就会出现这种情况。虽然会有一定的延时,但compaction在聚合的时候非常耗CPU,如果层级上下层的比例很大时,它一定回去强行触发合并,这是可能就会短暂的出现延时较高的问题。
Q:如何做到只查cache就知道key也不在下层存储里面?
A:我们会在缓存层里面把所有的key都给存储起来,这样相当于一个过滤器,你的key全部存在缓存就知道了,不用再去查存储。
Q:值是永久存储吗?即使在Redis中过期了
A:过期这个概念需要简单介绍一下。在混合存储版中TTL的语义没有发生改变,TTL到期或者仍然会删除数据,所以说这个版本的正确使用姿势就是,不需要删除的key就不要去设expire,不然你的数据会被删除,我们会在缓存层自动做一个缓存的调配,但是数据是持久化的磁盘,这一点是一个区别。
Q:公有云上,如果是典型的常规网管类应用(设备接入、认证、配置&管理、报表、关联分析),用传统的分布式数据库更有优势还是Redis更有优势?
A:Redis 主要是在互联网产品非结构化的数据和科学存储,它能够支持非常轻量的范围查询。但我理解像网管类的应用设备,还是更偏传统的关系型数据库。Redis还是偏互联网场景,更能够支持的设备都是带模式的表结构的数据库。
Q:大key存储方面有哪些限制?
A:大key存储目前没有限制,但是会在初期的版本上设置一个阈值,就是大于8M的一个value,我们暂时不会把它从内存驱逐。因为我们从把它存储层面捞起来的时候,整个耗时会非常长,也会明显的影响我们的性能。针对这个场景我们后面会优化一个大key场景的缓存,会把结构复杂的key穿透到存储层解决。
Q:现在Redis混合存储版SLA能达到几个9?日常烧内存或SSD损坏频率高吗?
A:混合存储版的SLA和其他存储数据库都是一样的,我们可用性的SLA是三个9,一个月99.95%。
日常烧内存还好,内存主要是SSD,但我们现在用的是分布式的存储,所以这一块暂时不是我们维护。SSD我觉得它有一个优势,就是我们这个版本因为是顺序写入的,肯定比随机写要好一点,IO的频率会低一些。从这个角度来说,它应该会比其他的数据库对SSD的保护更好一些。
Q:哨兵模式不能启用吗?
A:如果选用Redis混合存储版,直接把哨兵的逻辑去掉就可以了。我们会提供一个VIP,直接把它当成单机版使用就可以。
Q:Redis如何保障多中心双活?部署架构是什么样的?
A:我们会提供灾备和多AZ部署的方案。灾备的方案就是在多个地域或者多个AZ去部署单独实例,通过全球复制的功能实现灾备。多中心双活,我们后面会提供一个全球多活这样一个可以多点写入的方案,可以在后面关注我们产品上线的一个进度。
Q:大量数据过期,后台会自动清理吗?
A:如果是混合存储版设置了一个过期的时间,到时间之后后台就会把key删除掉,在缓存和存储同时删除。
Q:范围扫描的操作,性能如何?
A:如果执行的命令不涉及到value,它的性能就和内存版是一样的,如果涉及到value,其实就是磁盘版的性能。
Q:刚提到计划全球同步,面临最大的挑战是什么?个人认为物理延迟是无法避免的,强一致是很难的,物理链路决定了延时。那是否只能保证最终一致性?
A:我们在全球同步的时候,比如国内和海外有100甚至200、300毫秒的时延,如果要求强一致业务肯定是不能接受的。
这个问题最终还是要回归到用户的真实场景,假如在全球同步全球多活的场景下,可能会有异地读的需求。比如游戏的排行榜,玩家在国内刷新数值,会立即更新到国内的排行榜,同时也会异步更新到海外的Redis,数据可能会有一点延迟,但最终大家看到排行榜的数据是一致的。
这种场景对数据实时性的要求肯定不是特别高,如果真的特别高就不能够选择这种方案。所以一般是由业务进行选择,业务如果接受全球复制,那么一定能够接受数据的延迟。
Q:用了这个,是不是就没有必要在用关系型数据库像MySQL?
A:这个是我们设计这个产品的一个初衷,因为我们发现很多使用Redis+MySQL的场景,MySQL的作用仅仅是为了保障数据的可靠性,这种场景下我们使用一个混合存储就够了。或者是我们使用MySQL的目的是为了数据落地和做离线的分析,那可以把这个拆开,线上业务使用混合存储版保障业务逻辑简单,存储性能足够高,线下的分析的数据存储在MySQL。但是这个方案不是万能的,因为Redis是一个NoSQL数据库,没有完整的事务支持,不能支持复杂的查询操作,所以最佳的时间是将非结构化的数据存储在混合存储版,结构化数据存储在关系型数据库。
Q:是基于k8s吗,怎么暴露服务的?k8s的网络有优化吗?
A:架构不是基于k8s,暴露服务是一个VIP,每一个实例每一个集群会提供一个vip,像操作单机版一样使用。
Q:集群版是社区版cluster的还是proxy的,性能损失多少?
A:集群版是proxy加cluster的架构,但Redis我们改造的点还蛮多的。因为要解决数据一致性,淘汰value等。
混合存储版本,如果他和纯内存的Redis版本相比,冷数据的读写性能一定是磁盘的性能,而不是Redis的性能,磁盘的性能和Redis的性能不是一个量级的。目前单分片的磁盘性能大概是2-3万,极限压测能够达到4万多的情况。但纯内存版的随便可以跑到10万,所以是有明显的下降,还有时延的问题。
腾讯云Redis混合存储版重磅推出,万字长文助你破解缓存难题!的更多相关文章
- Redis 混合存储最佳实践指南
Redis 混合存储实例是阿里云自主研发的兼容Redis协议和特性的云数据库产品,混合存储实例突破 Redis 数据必须全部存储到内存的限制,使用磁盘存储全量数据,并将热数据缓存到内存,实现访问性能与 ...
- Redis混合存储-冷热数据识别与交换
Redis混合存储产品是阿里云自主研发的完全兼容Redis协议和特性的混合存储产品. 通过将部分冷数据存储到磁盘,在保证绝大部分访问性能不下降的基础上,大大降低了用户成本并突破了内存对Redis单实例 ...
- 腾讯云Redis全面升级,性能提升400%,可用性高达5个9
2022年6月,腾讯云Redis全新升级,发布高性能版本,单节点可提供50W+吞吐,性能是原生Redis的4倍.同时,腾讯云Redis推出全球复制功能,解决原生Redis诸多痛点问题,可用性升级高达9 ...
- 腾讯云 COS 对象存储使用
目前使用腾讯云的对象存储cos服务,将本地的文件同步到cos中,看了腾讯云的用户文档,发现使用COS Migration 工具还是挺适合的. 原因 因为服务器已经安装有java环境,而cos的几个用户 ...
- Go操作腾讯云COS对象存储的简单使用案例
准备环境 安装Go环境 Golang:用于下载和安装 Go 编译运行环境,请前往 Golang 官网进行下载 安装SDK go get -u github.com/tencentyun/cos-go- ...
- 腾讯云COS对象存储 Web 端直传实践(JAVA实现)
使用 腾讯云COS对象存储做第三方存储云服务,把一些文件都放在上面,这里主要有三中实现方式:第一种就是在控制台去设置好,直接上传文件.第二种就是走服务端,上传文件,就是说,上传文件是从服务端去上传上去 ...
- 腾讯云COS对象存储占据数据容灾C位
说到公有云容灾,大家首先想到的是云上数据备份. 然而,随着企业核心业务逐渐从线下迁移到云上,客户提出了更高的要求.如何确保云上业务的高可用.数据的高可靠,这对云厂商提出了新的挑战. 腾讯云作为全球领先 ...
- 腾讯云原生混合云-第三方集群弹EKS应对突发流量的利器
作者 何鹏飞,腾讯云专家产品经理,曾作为容器私有云.TKEStack的产品经理兼架构师,参与腾讯云内部业务.外部客户容器化改造方案设计,目前负责云原生混合云产品方案设计工作. 胡晓亮,腾讯云专家工程师 ...
- 腾讯云点播视频存储(Web端视频上传)
官方文档 前言 所谓视频上传,是指开发者或其用户将视频文件上传到点播的视频存储中,以便进行视频处理.分发等. 一.简介 腾讯云点播支持如下几种视频上传方式: 控制台上传:在点播控制台上进行操作,将本地 ...
随机推荐
- idea打印中文乱码
一.问题情况: IntelliJ IDEA 控制台输出中文乱码部分如图所示: 二.解决方法: 1.打开tomcat配置页面,Edit Configurations. 2.选择项目部署的tomcat,在 ...
- js中 addEventListener 和removeEventListener
js中添加事件监听本来是非常常见的事情,但是去除监听一般很少去干,最近项目中需要监听页面显示或者隐藏 代码如下 document.addEventListener(visibilitychange', ...
- Robot Framework(11)- 用户关键字的详解
如果你还想从头学起Robot Framework,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1770899.html 什么是用户关键字 ...
- [json-server] RESTful API 中,取主数据时,同时获取多个关联子表的数据
项目背景: back-end:ASP.NET Core WebAPI front-end:Vue(+vue-router +vuex +axios)(webpack)(json-server + mo ...
- Java 获取IP工具类、Vo类整理记录
前言 日常开发中,获取ip是常用的功能,本文记录如何在Java中获取本机外网ip.地理位置,访问用户的外网ip.地理位置,以及指定外网ip的地理位置: 代码编写 1.获取访问用户外网ip,我们从访问者 ...
- Java学习之路【第一篇】:前言
Java 语言概述 一.什么是Java语言 Java语言是美国Sun公司(Stanford University Network),在1995年推出的高级的编程语言.所谓编程语言,是计算机的语言,人们 ...
- [256个管理学理论]001.蝴蝶效应(Butterfly Effect)
蝴蝶效应(Butterfly Effect) 来自于大洋彼岸的让你看不懂的解释: 蝴蝶效应是指在一个动力系统中,初始条件下微小的变化能带动整个系统的长期的巨大的连锁反应,是一种混沌的现象.“蝴蝶效应” ...
- Spring_管理bean的生命周期
Spring IOC 容器对 Bean 的生命周期进行管理的过程:通过构造器或工厂方法创建 Bean 实例为 Bean 的属性设置值和对其他 Bean 的引用将 Bean 实例传递给 Bean 后置处 ...
- GNS3配置问题(持续更新)
GNS3配置问题 1.关于All in One的GNS3提示"判断dynamips版本失败"的解决办法 当我们找到GNS3根目录里的dynamips.exe,执行会报错告诉我们缺少 ...
- js 识别二维码
本文引用analyticCode.js.llqrcode.js实现识别二维码功能 html代码: <div class="box" id="analytic&quo ...