无损卡尔曼滤波UKF(3)-预测-生成Sigma点
无损卡尔曼滤波UKF(3)-预测-生成Sigma点
1 选择创建Sigma点
A 根据
已知上一个时间戳迭代出来的
后验状态 \(x_{k|k}\) 和后验协方差矩阵 \(P_{k|k}\)
他们代表当前状态的分布。
Sigma点的数量取决于状态向量的维度
\(n_{\sigma} = 2\cdot n_x + 1\)
如果以两个维度的状态向量为例。就可以生成五个sigma点。
\(X_{k|k} = [P1,P2,P3,P4,P5]\)
矩阵的每一列都代表一个Sigma点。
\(X_{k|k} = [x_{k|k},x_{k|k}+\sqrt[2]{(\lambda+n_x)P_{k|k}},x_{k|k}-\sqrt[2]{(\lambda+n_x)P_{k|k}} ]\)
关于Lambda,是一个设计的参数,一般情况下,按下面的设置,效果还不错
\(\lambda = 3 - n_x\)
求矩阵的平方根 => 找到矩阵A
\(A = \sqrt[2]{P_{k|k}} <= A^T A = P_{k|k}\)
第一个点就是状态向量的均值。
如果Lambda值大,Sigma点会距离均值点远一些。
生成Sigma点的代码(1)
/*
根据上述公式,完成生成Sigma点的函数
*/
void UKF::GenerateSigmaPoints(MatrixXd* Xsig_out) {
// 设置状态向量的维度
int n_x = 5;
// 定义传播参数
double lambda = 3 - n_x;
// 给定一个样例状态
VectorXd x = VectorXd(n_x);
x << 5.7441,
1.3800,
2.2049,
0.5015,
0.3528;
// 给定一个样例状态的协方差矩阵
MatrixXd P = MatrixXd(n_x, n_x);
P << 0.0043, -0.0013, 0.0030, -0.0022, -0.0020,
-0.0013, 0.0077, 0.0011, 0.0071, 0.0060,
0.0030, 0.0011, 0.0054, 0.0007, 0.0008,
-0.0022, 0.0071, 0.0007, 0.0098, 0.0100,
-0.0020, 0.0060, 0.0008, 0.0100, 0.0123;
// 创建Sigma点的矩阵、一列代表一个Sigma点、
MatrixXd Xsig = MatrixXd(n_x, 2 * n_x + 1);
// 计算矩阵P的平方根
MatrixXd A = P.llt().matrixL();
// 设置Sigma矩阵的第一列,一列代表一个Sigma点
Xsig.col(0) = x;
// 设置Sigma矩阵剩下的点
for (int i = 0; i < n_x; ++i) {
Xsig.col(i+1) = x + sqrt(lambda+n_x) * A.col(i);
Xsig.col(i+1+n_x) = x - sqrt(lambda+n_x) * A.col(i);
}
// 打印结果
std::cout << "Xsig = " << std::endl << Xsig << std::endl;
// 返回结果
*Xsig_out = Xsig;
}
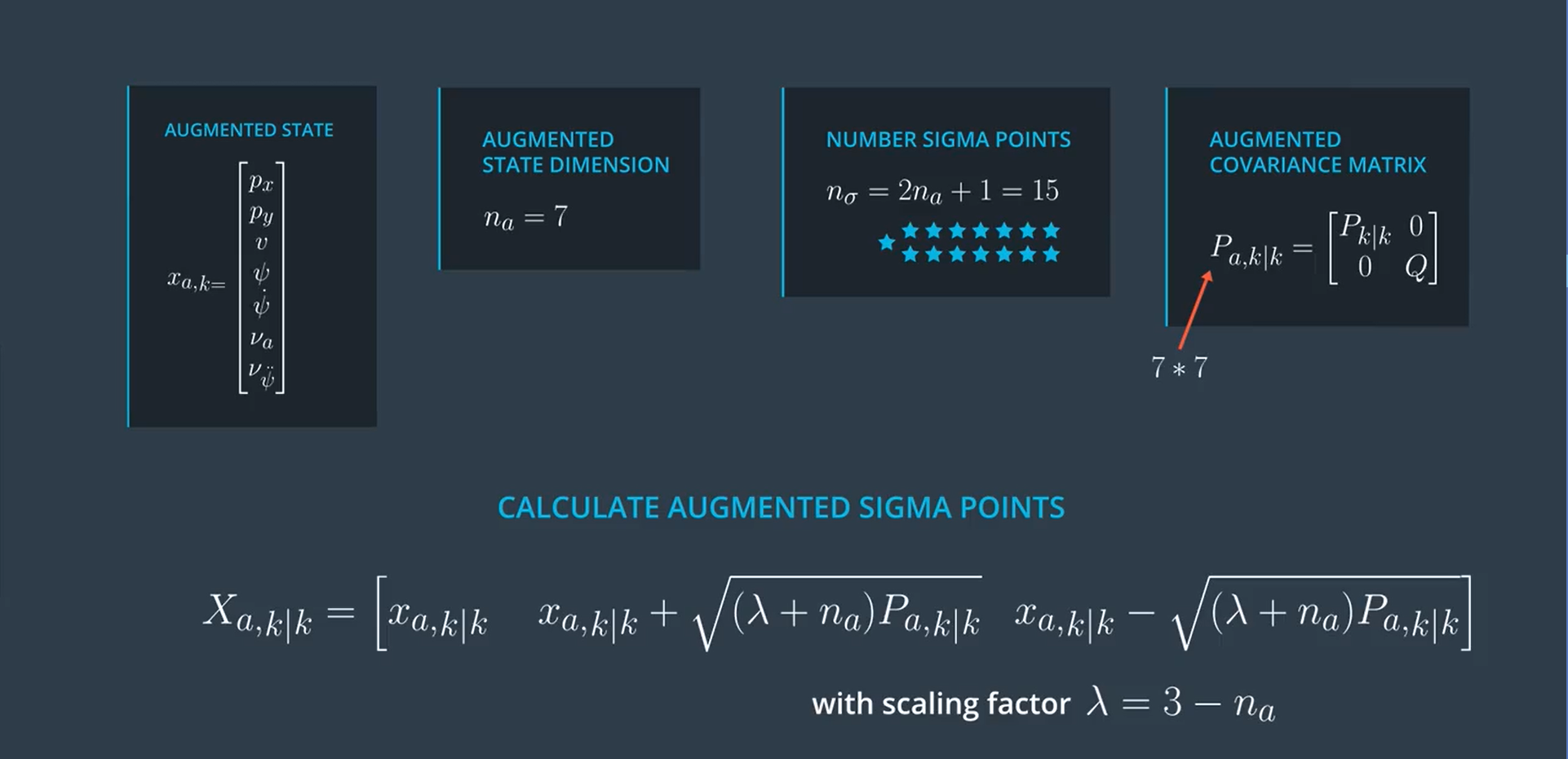
B 扩充后创建Sigma点
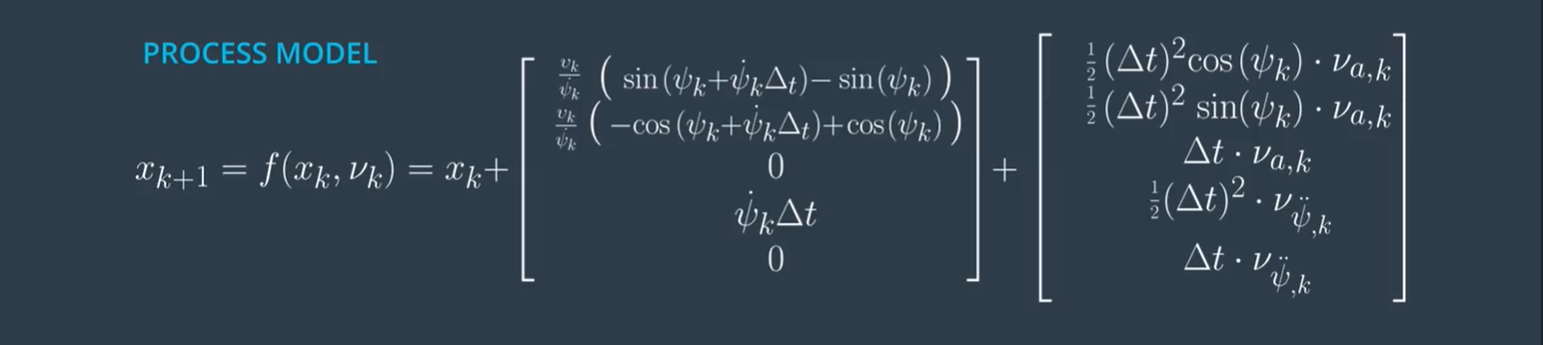

考虑到噪声的影响??
- 扩充状态的平均值中添加了两个噪声值。
- 纵向加速度项和角加速度项。均值为0 ,一定方差的正态分布。
- 他们的平均值为零,因此在平均状态的Sigma点,将他们的值设置为零。
- 用零填充扩充的协方差矩阵。
- 然后,使用topLeftcorner函数设置扩充的协方差矩阵的左上块。
- 方差放入增强矩阵的右下块。 该2x2块对应于矩阵QQ。
除了这次创建了更多的sigma点,其余部分与以前完全相同。
void UKF::AugmentedSigmaPoints(MatrixXd* Xsig_out) {
// 维数
int n_x = 5;
// 扩展后维数为7
int n_aug = 7;
// Process noise standard deviation longitudinal acceleration in m/s^2
double std_a = 0.2;
// Process noise standard deviation yaw acceleration in rad/s^2
double std_yawdd = 0.2;
// 定义传播参数
double lambda = 3 - n_aug;
VectorXd x = VectorXd(n_x);
x << 5.7441,
1.3800,
2.2049,
0.5015,
0.3528;
MatrixXd P = MatrixXd(n_x, n_x);
P << 0.0043, -0.0013, 0.0030, -0.0022, -0.0020,
-0.0013, 0.0077, 0.0011, 0.0071, 0.0060,
0.0030, 0.0011, 0.0054, 0.0007, 0.0008,
-0.0022, 0.0071, 0.0007, 0.0098, 0.0100,
-0.0020, 0.0060, 0.0008, 0.0100, 0.0123;
// 创建扩充后的平均值向量
VectorXd x_aug = VectorXd(7);
// 创建扩充后的状态协方差矩阵
MatrixXd P_aug = MatrixXd(7, 7);
// 创建扩充后的Sigma矩阵
MatrixXd Xsig_aug = MatrixXd(n_aug, 2 * n_aug + 1);
// 设置扩充后的平均值向量的参数值
x_aug.head(5) = x;
x_aug(5) = 0;
x_aug(6) = 0;
// 设置扩充后的状态协方差矩阵
P_aug.fill(0.0);
P_aug.topLeftCorner(5,5) = P;
P_aug(5,5) = std_a*std_a;
P_aug(6,6) = std_yawdd*std_yawdd;
// 求P的平方根
MatrixXd L = P_aug.llt().matrixL();
// 设置Sigma矩阵其他位置的值
Xsig_aug.col(0) = x_aug;
for (int i = 0; i< n_aug; ++i) {
Xsig_aug.col(i+1) = x_aug + sqrt(lambda+n_aug) * L.col(i);
Xsig_aug.col(i+1+n_aug) = x_aug - sqrt(lambda+n_aug) * L.col(i);
}
std::cout << "Xsig_aug = " << std::endl << Xsig_aug << std::endl;
*Xsig_out = Xsig_aug;
}
无损卡尔曼滤波UKF(3)-预测-生成Sigma点的更多相关文章
- LSTM生成尼采风格文章
LSTM生成文本 github地址 使用循环神经网络生成序列文本数据.循环神经网络可以用来生成音乐.图像作品.语音.对话系统对话等等. 如何生成序列数据? 深度学习中最常见的方法是训练一个网络模型(R ...
- 生成模型(Generative Model)和 判别模型(Discriminative Model)
引入 监督学习的任务就是学习一个模型(或者得到一个目标函数),应用这一模型,对给定的输入预测相应的输出.这一模型的一般形式为一个决策函数Y=f(X),或者条件概率分布P(Y|X). 监督学习方法又可以 ...
- 蛋白质组DIA深度学习之谱图预测
目录 1. 简介 2. 近几年发表的主要工具 1.DeepRT 2.Prosit 3. DIANN 4.DeepDIA 1. 简介 基于串联质谱的蛋白质组学大部分是依赖于数据库(database se ...
- 一文洞悉Python必备50种算法!资深大牛至少得掌握25种!
一.环境需求 二.怎样使用 三.本地化 3.1扩展卡尔曼滤波本地化 3.2无损卡尔曼滤波本地化 3.3粒子滤波本地化 3.4直方图滤波本地化 四.映射 4.1高斯网格映射 4.2光线投射网格映射 4. ...
- opencv3.1自带demo的介绍和运行操作。转载
opencv3.1自带demo的介绍和运行操作. 下列实验基本都试过,有些需要根据自己的电脑修改一些路径或者调试参数. 值得注意的是,控制台程序输入有时候要在图像所在的窗口输入相应的指令.我的电脑上安 ...
- 学习笔记TF060:图像语音结合,看图说话
斯坦福大学人工智能实验室李飞飞教授,实现人工智能3要素:语法(syntax).语义(semantics).推理(inference).语言.视觉.通过语法(语言语法解析.视觉三维结构解析)和语义(语言 ...
- Generative Adversarial Nets[Theory&MSE]
本文来自<deep multi-scale video prediction beyond mean square error>,时间线为2015年11月,LeCun等人的作品. 从一个视 ...
- 盖茨基金会:如何使用Python拯救生命
每年全球都要花费数十亿美元来预防疾病,减少死亡,资助预防保健及治疗的各种研发项目,以及其他的健康方案.但资金毕竟是有限的,所以一些组织,比如全球卫生资金的主要捐助者比尔&梅林达·盖茨基金会(B ...
- tensorflow的写诗代码分析【转】
本文转载自:https://dongzhixiao.github.io/2018/07/21/so-hot/ 今天周六,早晨出门吃饭,全身汗湿透.天气真的是太热了!我决定一天不出门,在屋子里面休息! ...
随机推荐
- linux 上安装 java
一.源码安装 1.本地下载 java, 并上传到 linux 上 2.解压文件 tar -zxvf jdk-7u72-linux-i586.gz 3.配置环境变量 vi /etc/profile ...
- linux清除cache的方法
1 Linux下内存占用多的原因 当linux第一次读取一个文件运行时,一份放到一片内存中cache起来,另一份放入运行程序的内存中,正常运行,当程序运行完,关闭了,cache中的那一分却没有释放, ...
- php 二维码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- kafka spark steam 写入elasticsearch的部分问题
应用版本 elasticsearch 5.5 spark 2.2.0 hadoop 2.7 依赖包版本 docker cp /Users/cclient/.ivy2/cache/org.elastic ...
- 通过HTTP向kafka发送数据
在大数据整个处理流程过程中,数据的流向是一个很重要的问题,本篇博客主要记录数据是怎么从http发送到kafka的. 使用技术点: 1. java的Vert.x框架 (关于java框架Vert.x的使用 ...
- Java中的基本运算符
一.算术运算符运算符:对常量或者变量进行操作的符号表达式:用运算符把常量或者变量连接起来符合java语法的式子就可以称为表达式.注意:不同运算符连接的表达式体现的是不同类型的表达式. + 加法运算,字 ...
- 接受H0的坏处|试验误差|置信度由来|
生物统计与实验设计 置信度(0.05 0.01)是通过实验次数估计值的分布得到的,它是整个分布的期望,这个值的确立需要具体情况具体分析. 肯定很难,因为否定一次很容易.虽然如果没有否定(eg:得到p= ...
- 【转】【关于 A^x = A^(x % Phi(C) + Phi(C)) (mod C) 的若干证明】【指数循环节】
[关于 A^x = A^(x % Phi(C) + Phi(C)) (mod C) 的若干证明][指数循环节] 原文地址:http://hi.baidu.com/aekdycoin/item/e493 ...
- MOOC(1)-使用pycharm新建Django项目、开发post接口
https://www.cnblogs.com/liqu/p/9308966.html 1.安装Django的两种方式: > 1) pip install django 2)下载离线安装包,进入 ...
- 吴裕雄--天生自然HTML学习笔记:HTML 样式- CSS
CSS (Cascading Style Sheets) 用于渲染HTML元素标签的样式. <!DOCTYPE html> <html> <head> <me ...