新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计
HBase是一个高可靠、高性能、面向列、可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群。
HBase 是Google Bigtable 的开源实现,与Google Bigtable 利用GFS作为其文件存储系统类似, HBase 利用Hadoop HDFS 作为其文件存储系统;Google 运行MapReduce 来处理Bigtable中的海量数据, HBase 同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable 利用Chubby作为协同服务, HBase 利用Zookeeper作为对应。
1.下载HBase并安装

1)下载Apache版本的HBase。
2)下载Cloudera版本的HBase。
3)这里选择下载cdh版本的hbase-0.98.6-cdh5.3.0.tar.gz,然后上传至bigdata-pro01.kfk.com节点/opt/softwares/目录下
4)解压hbase
tar -zxf hbase-0.98.6-cdh5.3.0.tar.gz -C /opt/modules/
2.分布式集群的相关配置
1)HBase架构体系

a.Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的单点问题。
b.HBase Master
每台HRegion服务器都会和HMaster服务器通信,HMaster的主要任务就是要告诉每台HRegion服务器它要维护哪些HRegion。 当一台新的HRegion服务器登录到HMaster服务器时,HMaster会告诉它先等待分配数据。而当一台HRegion死机时,HMaster会把它负责的HRegion标记为未分配,然后再把它们分配到其他HRegion服务器中。
c.HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
2)HBase集群规划
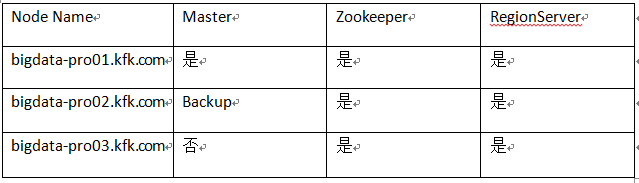
3)分布式集群相关配置
a.hbase-env.sh
#配置jdk
export JAVA_HOME=/opt/modules/jdk1.7.0_67
#使用独立的Zookeeper
export HBASE_MANAGES_ZK=false
b.hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>bigdata-pro01.kfk.com,bigdata-pro02.kfk.com,
bigdata-pro03.kfk.com</value>
</property>
</configuration>
c.regionservers
bigdata-pro01.kfk.com
bigdata-pro02.kfk.com
bigdata-pro03.kfk.com
d.backup-masters
bigdata-pro02.kfk.com
4)将hbase配置分发到各个节点
scp -r hbase-0.98.6-cdh5.3.0 bigdata-pro02.kfk.com:/opt/modules/
scp -r hbase-0.98.6-cdh5.3.0 bigdata-pro03.kfk.com:/opt/modules/
3.启动HBase服务
1)各个节点启动Zookeeper
zkServer.sh start
2)主节点启动HDFS
bin/start-dfs.sh
3)启动HBase
bin/start-hbase.sh
4)查看HBase Web界面
bigdata-pro01.kfk.com:60010/
如果各个节点启动正常,那么HBase就搭建完毕。
4.通过shell测试数据库
1)选择主节点进入HBase目录,启动hbase-shell
cd hbase-0.98.6-cdh5.3.0
bin/hbase-shell
2)查看所有表命令
list
3)使用help帮助命令
help
4)创建表
create 'test','info'
5)添加数据
put 'test','0001','info:userName','laocao'
6)全表扫描数据
scan 'test'
7)查看表结构
describe 'test'
8)删除表
disable 'test'
drop 'test'
5.根据业务需求创建表结构
1)下载数据源文件
2)HBase上创建表
create 'weblogs','info'
新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
- 新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析
(一)Hive 概述 (二)Hive在Hadoop生态圈中的位置 (三)Hive 架构设计 (四)Hive 的优点及应用场景 (五)Hive 的下载和安装部署 1.Hive 下载 Apache版本的H ...
- 新闻网大数据实时分析可视化系统项目——5、Hadoop2.X HA架构与部署
1.HDFS-HA架构原理介绍 hadoop2.x之后,Clouera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法实现的HDFS HA方案,它给出了一种较好的解 ...
随机推荐
- 2.0.FastDFS单机模式综合版
Centos610系列配置 1.什么是FastDFS? FastDFS是一个开源的分布式文件系统,她对文件进行管理,功能包括:文件存储.文件同步.文件访问(文件上传.文件下载)等,解决了大容量存储和负 ...
- springweb 详解。
spring web架构图 从图中可以看出, 如果要对输出的内容进行重构,不需要视图的话,在handlerMethodReturnValueHandler里进行操作,可以重构这个对象,以达到自定义输出 ...
- Thymeleaf Tutorial 文档 中文翻译
原文档地址:https://www.thymeleaf.org/doc/tutorials/3.0/usingthymeleaf.html Thymeleaf官网地址:https://www.thym ...
- Esp32的一些资料链接
http://wiki.ai-thinker.com/doku.php/utils/esp32_idf_menuconfig http://wiki.ai-thinker.com/doku.php ...
- 洛谷 P1082 同余方程(同余&&exgcd)
嗯... 题目链接:https://www.luogu.org/problem/P1082 这道题很明显涉及到了同余和exgcd的问题,下面推导一下: 首先证明有解情况: ax + by = m有解的 ...
- rem在三星s5部分机型情况下 设置的字体大小与手机实际字体大小不一致问题
rem在三星s5部分机型情况下 设置的字体大小与手机实际字体大小不一致问题 判断是特殊机型,做特殊处理. var u=navigator.userAgent; if($(window).width() ...
- highcharts饼图
效果: JSON加载数据: var chartseries2 = [ { name: '完成' + data.rate + '%', y: data.rate }, { name: '未完成' + d ...
- 类似discuz密码的生成规则
/* 生成一个串,uniqid(rand()): uniqid(prefix,more_entropy) 函数基于以微秒计的当前时间,生成一个唯一的 ID. 如果 prefix 参数为空,则返回的字符 ...
- spring cloud spring boot JPA 克隆对象修改属性后 无法正常的执行save方法进行保存或者更新
2019-12-1220:34:58 spring cloud spring boot JPA 克隆对象修改属性后 无法正常的执行save方法进行保存或者更新 未解决
- 吴裕雄--天生自然TensorFlow2教程:输出方式
sigmoid out' = sigmoid(out) # 把输出值压缩在0-1 import tensorflow as tf a = tf.linspace(-6., 6, 10) a tf.si ...