【课程学习】课程2:十行代码高效完成深度学习POC
本文用户记录黄埔学院学习的心得,并补充一些内容。
课程2:十行代码高效完成深度学习POC,主讲人为百度深度学习技术平台部:陈泽裕老师。
因为我是CV方向的,所以内容会往CV方向调整一下,有所筛检。
课程主要有以下三个方面的内容:
- 深度学习POC的基本流程
- 实用预训练模型应用工具快速验证
- 通用模型一键检测
- 十行代码完成工业级文本分类
- 自动化调参AutoDL Finetuner
一、深度学习POC的基本流程
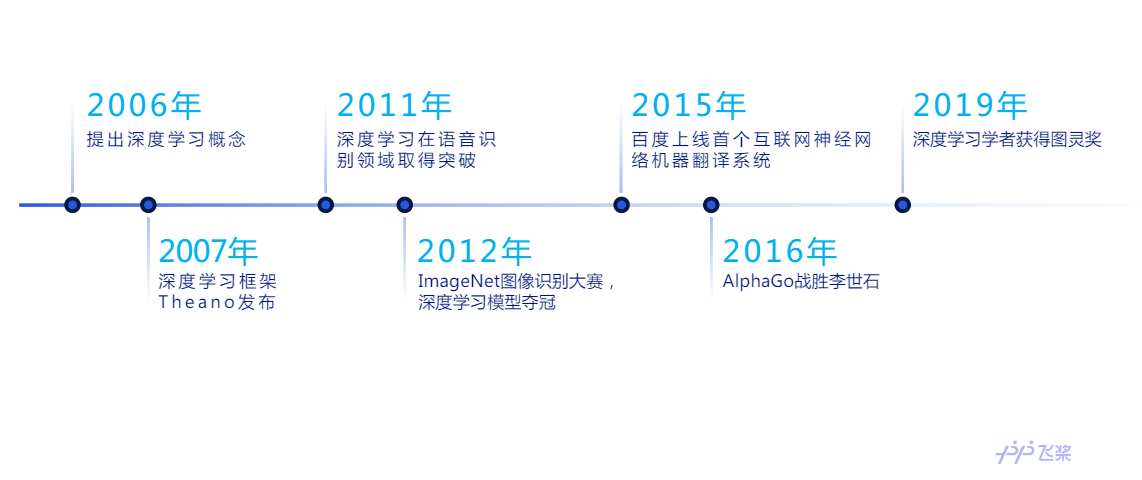
1.1 深度学习发展历程
2006年,这一年多伦多大学的Geoffrey Hinton教授发表的论文,提出了两个重要观点:(1)多层的神经网络模型有很强的特征学习能力,深度学习模型能够学习到的数据更本质的特征;(2)对于深度神经网络获得全局最优解的问题,可以采用逐层训练方法解决。自此,深度学习迅速发展。2007年,深度学习框架Theano发布,用于优化多维数组的计算。2011年,深度学习首先在语音识别领域取得突破。2012年,Krizhevsky等人首次将卷积神经网络应用至ImageNet图像识别大赛,大获全胜。随后,深度学习在自然语言处理、图像识别等多个领域遍地开发。2016年,基于深度强化学习的AlphaGo战胜李世石,大放异彩,以深度学习为代表的人工智能技术在广大群众中热议。2019年,三位深度学习之父:Geoffrey Hinton, Yann LeCun,和Yoshua Bengio共同获得了图灵奖。
1.2 深度学习的成功与局限
深度学习界的圣经,花书《Deep Learning》也提到,深度学习的成功有以下两个方面的原因:
(1)与日俱增的数据量:“要从一个深度学习算法获得良好的性能需要一些技巧。幸运的是,随着训练数据的增加,所需的技巧正在减少”。随着数据量的激增,以大数据驱动的深度学习算法在某些复杂任务上达到甚至超越了人类的水平。
(2)大算力背景下与日俱增的模型规模:越发庞大的计算资源可以允许我们运行更大的模型,Hinton教授以及很多联结主义的学者提到,模型的规模更大,特征学习能力更强(当然也不是模型越大越好)。
也正因为如此,深度学习在小样本、低算力的场景下效果受限,同时大模型的设计门槛也是比较高的。
1.3 深度学习技术的探索方向
多任务学习:比如基于预训练模型的迁移学习。实际上在很多场合下(特别是工业、医疗等场景),数据——尤其是负样本的数量是非常少的,基于预训练模型的迁移学习技术能够起到比较关键的作用。我在看科技部发的“新一代人工智能”相关文件的时候,很多项目都提到了研究技能迁移技术,可见其重要性。
自监督学习:自监督学习是无监督学习的一种,也是为了解决小样本问题。深度学习需要的训练样本是需要人工贴标的,但是标注成本非常大。自监督学习的“标注”通常来自于数据本身,比如扣掉视频中的某些帧,覆盖掉图像中的某一部分,让模型依赖其周围的信息去预测缺失部分,从而学习到数据的特征。
1.4 深度学习POC的基本流程
POC,即Proof of Concept,POC的作用是在项目初始阶段进行方案的测试性验证。
深度学习POC的用于明确该项目能否采用深度学习技术完成,基本流程如下图所示:

(1)明确需求:首先需要明确任务的需求是什么,然后确定客户的技术指标,是否能与深度学习模型的效果建立关联。
(2)数据优化:采取深度学习技术做一个项目,很大比重的经历要放在数据采集、数据标注和清洗上。数据集的好坏直接关系到任务的上限。
(3)模型选型:确定客户任务的场景是否能用现成的预训练模型解决,比如人类检测、通用分类等等,找到一个合适的预训练模型可以说能够解决一半问题;结合部署环境和性能要求选择模型,比如节拍需求、精度要求、成本问题等等;确定是否需要结合传统的视觉技术,如图像分割,边缘检测等等;是否需要多个模型组合到一起,比如分类+分割,等等。
(4)调参训练:调参训练涉及到数据增强、网络调参和训练参数调参等等。现在有一些自动化的超参数优化策略。
(5)模型部署:部署时需要对边缘计算设备算力、成本等多方面考虑,通常需要进行模型压缩(详见第一课的内容)。要考虑是服务端部署,还是移动端、嵌入式设备、ASIC芯片部署、服务化部署等等。
1.5 视觉领域基础模型
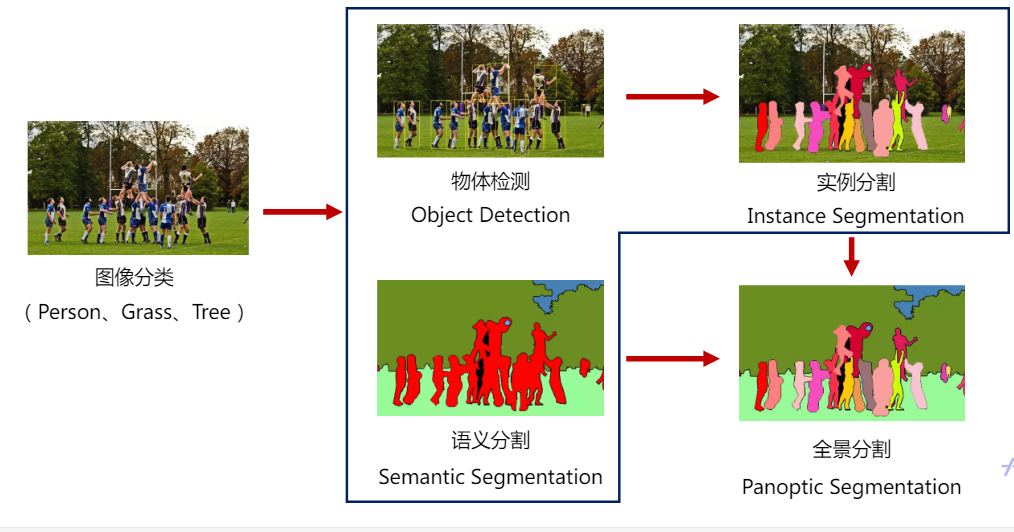
视觉领域有很多典型的模型,根据任务的不同可以分为图像分类、目标检测、分割任务。分类任务比较好理解,就是解释“Yes” or “No”的问题。目标检测任务需要解决“what is where”问题,不光要判断是什么,还有定位出它的位置。三种分割任务要解决的是每个像素点所属的类型,根据需求的不同分为语义分割、实例分割以及全景分割。
一般需要精细化检测的时候,需要用到语义分割或者实例分割。只需要知道“what is where”时,用目标检测就可以。
1.4 视觉预训练模型的选型
现在不管做CV还是NLP,都逐步进入了预训练时代。
下图表示的是各种的模型 Top-1准确率VS计算复杂度,圆圈大小表示占用内存开销。
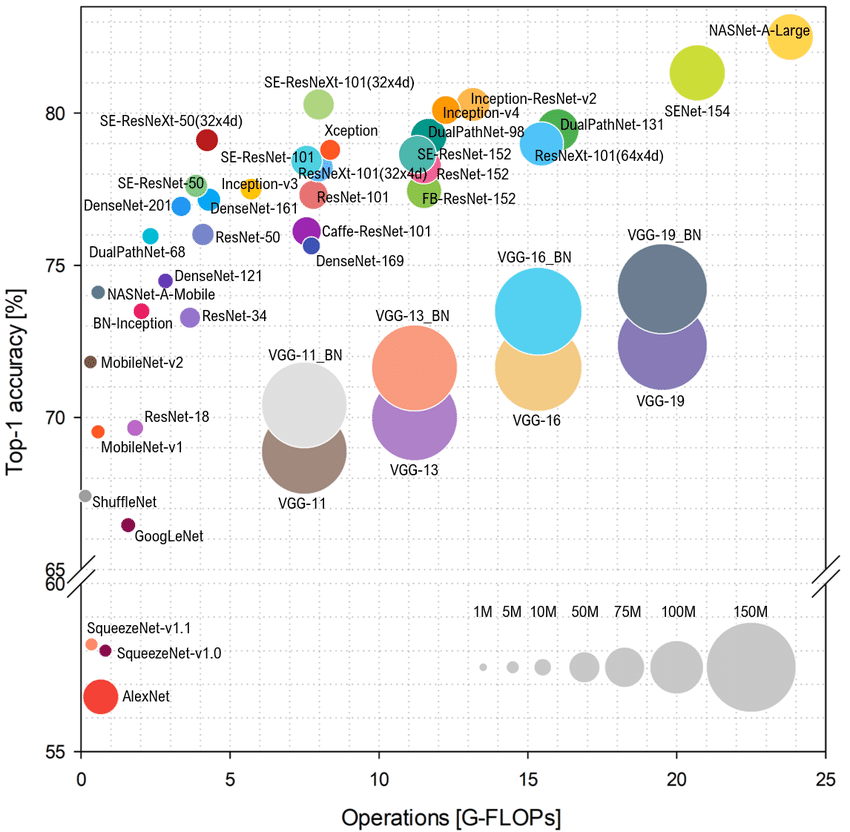
在分类的任务上,一般比较关注下图靠左的这些模型:精度相对比较高、模型也比较小,算力开销也不大,能够在算力有限的部署端取得不错的性能。在做检测任务的时候,需要关注单阶段还是两阶段。不过在实际的任务中,关注比较多的是多尺度。因为有很多小目标的检测,多尺度性能会高一些。分割任务的主流是Encoder-Decoder结构,需要关注的就是低层的backbone结构。
整体来说需要关注三个方面:
(1)综合考虑精度、预测性能、还有内存开销
(2)在未来的有根据硬件特性来设计模型的趋势
(3)AutoML技术
二、实用预训练模型应用工具快速验证
2.1 通用模型一键检测
PaddleHub是飞桨的预训练模型管理和迁移学习工具,其中内置了面向多种场景和多项任务的预训练模型。采取高质量的预训练模型+Fine-tune的方式,可以快速完成迁移学习到部署过程。
链接为:https://github.com/PaddlePaddle/PaddleHub/
一个高质量的预训练模型需要算法+算力+数据+专家知识四个因素结合起来才能完成。PaddleHub的架构如下图所示,预训练模型很丰富,覆盖了图像分类、检测等多种任务。

PaddleHub有一个特点,就是把模型都作为Python的软件包管理起来,这就非常便捷易用了。
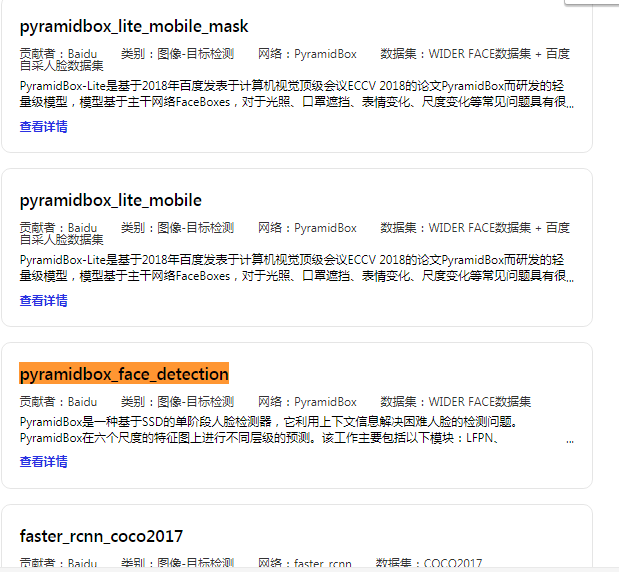
如下图所示,PaddleHub里有很多预训练模型。以上一节课提到的人脸识别来说,就可以调用PaddleHub里的pyramidbox_face_detection:
仅仅需要几行代码就能实现人脸识别:
import paddlehub as hub module = hub.Module(name="pyramidbox_face_detection")
input_dict = {"image": ["PATH/TO/IMAGE"]}
results = module.face_detection(data=input_dict)
类似的例子还有很多,涵盖图像、文本、视频等多个领域的多项内容,覆盖面非常全,就不一一列举了。
2.1 十行代码完成工业级文本分类
课程中介绍如何使用PaddleHub和Fine-tune API,通过极少的代码量完成一个工业级的文本分类。
采用预训练模型加微调的方式,一般需要少量的用户数据和超大规模预训练模型,这里使用的大规模预训练模型为ERNIE。
代码及备注如下:
import paddlehub as hub # 载入ChnSentiCorp中文情感分析数据集
dataset = hub.dataset.ChnSentiCorp()
# 下载并加载ERNIE模型,可在PaddleHub官网搜索
ernie= hub.Module(name=“ernie”)
# trainable=True表示预训练模型的参数可以被训练
inputs, outputs, program = ernie.context(trainable=True)
# 数据预处理,设置最大序列长度
reader = hub.reader.ClassifyReader(
dataset=dataset, max_seq_len=128,
vocab_path=ernie.get_vocab_path())
# 配置Tensor
feed_list= [inputs["input_ids"].name, inputs["position_ids"].name,
inputs["segment_ids"].name, inputs["input_mask"].name]
# 配置优化策略,优化器Adam,学习率衰减
strategy = hub.AdamWeightDecayStrategy(learning_rate=5e-5)
# 配置训练的参数
config= hub.RunConfig(num_epoch=3, strategy=strategy)
# 创建迁移学习任务
task = hub.TextClassifierTask(
data_reader=reader,
feature=outputs["pooled_output"],
feed_list=feed_list,
num_classes=dataset.num_labels,
config=config
)
# 启动Fine-tuning,自动评估、保存、可视化
task.finetune_and_eval()
如果对目标检测、人脸检测等任务的迁移学习比较感兴趣的话,百度也提供了免费的教程可以学习:
https://aistudio.baidu.com/aistudio/course/introduce/1070
三、自动化调参AutoML Finetuner
3.1 模型调优策略
斯坦福大学的吴恩达教授在他的深度学习课程上,用非常形象的方式将模型的调优策略分成两类:熊猫策略和鱼子酱策略。(因为一个生的少但精心养护,一个虽然不管不问但奈何比较能生。。。)
所谓的熊猫策略就依赖对模型非常熟悉的专家,对一个比较重要的模型精心调优,让它每天都能优化一点点。鱼子酱策略就是多组模型并行训练,随便设置若干组超参数,让模型自己去跑,然后再去甄别哪一组超参数下的模型效果最好。

模型调优是一个黑盒优化问题,在调优的过程中只看到模型的输入和输出,而看不到调优过程中的梯度信息。所以优化的关键就在于,怎么能尽可能少的次数找到一组超参数,能让模型的效果最优,就涉及到超参搜索的问题。
3.2 超参数搜索
超参搜索的策略有两种:网格搜索(Grid Search)和随机搜索(Random Search)。
正如表面意思,网格搜索指的是以某种组合规律来均匀的分布超参数,随机搜索就是直接在参数的设置空间里随机的撒入参数组,看看哪一组比较好。

在工业中,一般随机搜索会取得更好的效果。这是因为深度学习模型的超参数中有些是非常重要的(比如学习率),有些是没那么重要的。所以没必要给重要的超参数和不重要的超参数相同的搜索机会。比如上图左侧:重要的和不重要的都给了三次搜索机会。随机搜索就可以让重要超参数和搜索机会更密集一些,得到的效果也就更好。
除了这两种自动化调参算法之外,还有遗传算法、粒子群优化、贝叶斯优化等等。不过前两种优化算法所需的初始样本点较多,优化效率也一般。业界用的相对多一些的是贝叶斯优化。
不同黑盒优化策略的对比如下表所示:
| 熊猫策略 | 网格搜索 | 随机搜索 | 贝叶斯优化 | |
| 优点 | 可以取得较好的超参设置 | 实现简单,可并行搜索 | 搜索空间友好,可并行搜索 | 搜索效率高,鲁棒性强 |
| 缺点 | 耗时耗力,成本高 | 搜索空间高维灾难 | 超参搜索相互独立 | 需要顺序优化,并行度低 |
2017年,Population Based Training(PBT)被提出,下图中最上面的长条代表网络性能,中间的圆圈代表超参数,下面的长条代码模型参数。
图中(a)策略采取的是一种“串行”的优化策略:先设置一种超参数,经过训练后看一看模型的效果,然后来评估哪些超参要调整一下。一般人工调参就采取这种策略,成本非常高,效率比较低。
图中(b)策略采取的是并行的优化策略:在大算力的支持下,同时设置若干组超参去训练,然后看看哪一组效果最好。这种方式虽然效率会高一些,但是组与组之间的结果是没有相互交流的,都在各干各的。
图中(c)策略就是PBT:在并行优化的过程中,就评估哪一组超参下的模型效果比较好,接着在这一组效果比较好的超参的基础上,添加一些随机扰动,然后把它经过轻微改动的超参分享给其他组,加强组与组之间的交流。
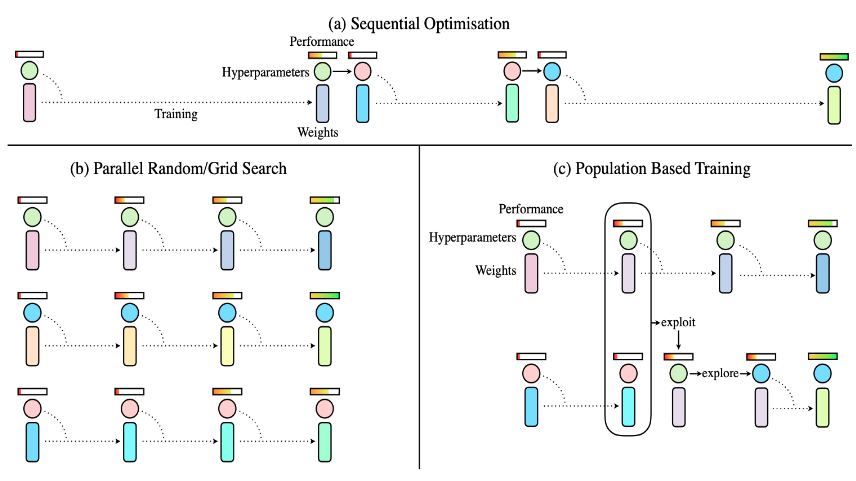
3.4 AutoDL Finetuner自动化超参搜索
PaddleHub中的超参搜索工具AutoDL Finetune,提供了两种优化算法:HAZero和PSHE2。HAZero的核心思想是通过对正态分布中协方差矩阵的调整来处理变量之间的依赖关系和scaling。PSHE2采用哈密尔顿动力系统搜索参数空间中“势能”最低的点,即超参数的最优组合。
为了评估搜索的超参的效果,AutoDL Finetuner提供了两种超参评估策略:
Full-Trail::给定一组超参,利用这组超参从头开始Fine-tune一个新模型,之后在验证集评估这个模型;
Population-Based:给定一组超参,若这组超参是第一轮尝试的超参组合,则从头开始Fine-tune一个新模型;否则基于前几轮已保存的较好模型,在当前的超参数组合下继续Fine-tune并评估。
四、总结
总结一下PaddleHub的内容:
(1)丰富、优秀的预训练模型库,涵盖了自然语言处理和计算机视觉两个方面;
(2)模型即软件,便捷、易用的迁移学习,仅需几行代码就能实现迁移学习;
(3)提供自动化的超参数搜索算法和评估算法,优化模型,降低训练门槛。
【课程学习】课程2:十行代码高效完成深度学习POC的更多相关文章
- 中文译文:Minerva-一种可扩展的高效的深度学习训练平台(Minerva - A Scalable and Highly Efficient Training Platform for Deep Learning)
Minerva:一个可扩展的高效的深度学习训练平台 zoerywzhou@gmail.com http://www.cnblogs.com/swje/ 作者:Zhouwan 2015-12-1 声明 ...
- Caffe——清晰高效的深度学习(Deep Learning)框架
Caffe(http://caffe.berkeleyvision.org/)是一个清晰而高效的深度学习框架,其作者是博士毕业于UC Berkeley的贾扬清(http://daggerfs.com/ ...
- 深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全
深度学习与计算机视觉(12)_tensorflow实现基于深度学习的图像补全 原文地址:Image Completion with Deep Learning in TensorFlow by Bra ...
- 人工智能深度学习Caffe框架介绍,优秀的深度学习架构
人工智能深度学习Caffe框架介绍,优秀的深度学习架构 在深度学习领域,Caffe框架是人们无法绕过的一座山.这不仅是因为它无论在结构.性能上,还是在代码质量上,都称得上一款十分出色的开源框架.更重要 ...
- 开源项目kcws代码分析--基于深度学习的分词技术
http://blog.csdn.net/pirage/article/details/53424544 分词原理 本小节内容参考待字闺中的两篇博文: 97.5%准确率的深度学习中文分词(字嵌入+Bi ...
- [深度学习大讲堂]从NNVM看2016年深度学习框架发展趋势
本文为微信公众号[深度学习大讲堂]特约稿,转载请注明出处 虚拟框架杀入 从发现问题到解决问题 半年前的这时候,暑假,我在SIAT MMLAB实习. 看着同事一会儿跑Torch,一会儿跑MXNet,一会 ...
- 小白学习之pytorch框架(2)-动手学深度学习(begin-random.shuffle()、torch.index_select()、nn.Module、nn.Sequential())
在这向大家推荐一本书-花书-动手学深度学习pytorch版,原书用的深度学习框架是MXNet,这个框架经过Gluon重新再封装,使用风格非常接近pytorch,但是由于pytorch越来越火,个人又比 ...
- DeepLearning.ai学习笔记(一)神经网络和深度学习--Week3浅层神经网络
介绍 DeepLearning课程总共五大章节,该系列笔记将按照课程安排进行记录. 另外第一章的前两周的课程在之前的Andrew Ng机器学习课程笔记(博客园)&Andrew Ng机器学习课程 ...
- DeepLearning.ai学习笔记(一)神经网络和深度学习--Week4深层神经网络
一.深层神经网络 深层神经网络的符号与浅层的不同,记录如下: 用\(L\)表示层数,该神经网络\(L=4\) \(n^{[l]}\)表示第\(l\)层的神经元的数量,例如\(n^{[1]}=n^{[2 ...
随机推荐
- pc 媒体查询
PC端 按屏幕宽度大小排序(主流的用橙色标明) 分辨率 比例 | 设备尺寸 1024*500 (8.9寸) 1024*768 (比例4:3 | 10.4寸.12.1寸.14.1寸.15寸; ) ...
- Mol Cell Proteomics. | Proteomics Analysis of Extracellular Matrix Remodeling During Zebrafish Heart Regeneration (解读人:徐宁)
文献名:Proteomics Analysis of Extracellular Matrix Remodeling During Zebrafish Heart Regeneration(斑马鱼心脏 ...
- 强智教务系统验证码识别 Tensorflow CNN
强智教务系统验证码识别 Tensorflow CNN 一直都是使用API取得数据,但是API提供的数据较少,且为了防止API关闭,先把验证码问题解决 使用Tensorflow训练模型,强智教务系统的验 ...
- .net core 依赖注入, autofac 简单使用
综述 ASP.NET Core 支持依赖注入, 也推荐使用依赖注入. 主要作用是用来降低代码之间的耦合度. 什么是控制反转? 控制反转(Inversion of Control,缩写为IoC),是面 ...
- ORM常用字段及方式
创建小型数据库 模型层 ORM常用字段 AutoField int自增列,必须填入参数 primary_key=True.当model中如果没有自增列,则自动会创建一个列名为id的列. Integer ...
- Linux基本操作 ------ 文件处理命令
显示目录文件 ls //显示当前目录下文件 ls /home //显示home文件夹下文件 ls -a //显示当前目录下所有文件,包括隐藏文件 ls -l //显示当前目录下文件的详细信息 ls - ...
- 北邮OJ 89. 统计时间间隔 java版
89. 统计时间间隔 时间限制 1000 ms 内存限制 65536 KB 题目描述 给出两个时间(24小时制),求第一个时间至少要经过多久才能到达第二个时间.给出的时间一定满足的形式,其中x和y分别 ...
- 服务器模型---socket!!!
/*********************服务器模型******************/ 一.循环服务器:循环服务器在同一时刻只可以相应一个客户端请求: 二.并发服务器:并发服务器在同一时刻可以相 ...
- Building Applications with Force.com and VisualForce(Dev401)(十二):Implementing Business Processes:Automating Business Processes Part 1
ev401-013:Implementing Business Processes:Automating Business Processes Part 1 Module Objectives1.Li ...
- TensorFlow 安装官方教程:Ubuntu 安装,Mac OS X 安装,Windows 安装
从我的使用体验来看 Ubuntu 是最好的, Mac 没有显卡,后期跑大项目比较鸡肋,Windows 安装各种依赖各种坑.Ubuntu 安装 TensorFlow 方便,后面安装 TensorFl ...