ARM处理器的堆栈和函数调用,以及与Sparc的比较
主要描述一下ARM处理器的堆栈和函数调用过程,并和Sparc处理器进行对比分析。
关于ARM处理器的内容来自以下网址,该网站是个学习ARM汇编的好地方,对该篇文章注解了一下,最后和Sparc进行对比。
https://azeria-labs.com/functions-and-the-stack-part-7/
Sparc的原理,Sparc V8 汇编指令、寄存器窗口、堆栈、函数调用
STACK AND FUNCTIONS
In this part we will look into a special memory region of the process called the Stack. This chapter covers Stack’s purpose and operations related to it. Additionally, we will go through the implementation, types and differences of functions in ARM.
堆栈是进程的一个特殊内存区域。堆栈的使用对于不同处理器的实现是不一样的。介绍堆栈的实现,类型以及。。。
STACK
Generally speaking, the Stack is a memory region within the program/process. This part of the memory gets allocated when a process is created. We use Stack for storing temporary data such as local variables of some function, environment variables which helps us to transition between the functions, etc. We interact with the stack using PUSH and POP instructions. As explained in Part 4: Memory Instructions: Load And Store PUSH and POP are aliases to some other memory related instructions rather than real instructions, but we use PUSH and POP for simplicity reasons.
堆栈是属于某个程序或进程的。当进程创建时,这部分堆栈内存也被分配。用堆栈存储局部变量,用于帮助我们在函数之间转移的环境变量,等。为简便起见,用PUSH和POP来访问堆栈,类似Sparc的助记符。
Before we look into a practical example it is import for us to know that the Stack can be implemented in various ways. First, when we say that Stack grows, we mean that an item (32 bits of data) is put on to the Stack. The stack can grow UP (when the stack is implemented in a Descending fashion) or DOWN (when the stack is implemented in a Ascending fashion). The actual location where the next (32 bit) piece of information will be put is defined by the Stack Pointer, or to be precise, the memory address stored in the SP register. Here again, the address could be pointing to the current (last) item in the stack or the next available memory slot for the item. If the SP is currently pointing to the last item in the stack (Full stack implementation) the SP will be decreased (in case of Descending Stack) or increased (in case of Ascending Stack) and only then the item will placed in the Stack. If the SP is currently pointing to the next empty slot in the Stack, the data will be first placed and only then the SP will be decreased (Descending Stack) or increased (Ascending Stack).
In our examples we will use the Full descending Stack. Let’s take a quick look into a simple exercise which deals with such a Stack and it’s Stack Pointer.

按照堆栈的生长方向和堆栈指针SP指向的位置,堆栈可以分为4种。例子中使用Full descending Stack,即上图第二种,堆栈向低地址生长,SP指向最后一个数据。
文章制作了很多精美的gif图,下图是一个简单例子中堆栈和寄存器的变化。

We will see that functions take advantage of Stack for saving local variables, preserving register state, etc. To keep everything organized, functions use Stack Frames, a localized memory portion within the stack which is dedicated for a specific function. A stack frame gets created in the prologue (more about this in the next section) of a function. The Frame Pointer (FP) is set to the bottom of the stack frame and then stack buffer for the Stack Frame is allocated. The stack frame (starting from it’s bottom) generally contains the return address (previous LR), previous Frame Pointer, any registers that need to be preserved, function parameters (in case the function accepts more than 4), local variables, etc. While the actual contents of the Stack Frame may vary, the ones outlined before are the most common. Finally, the Stack Frame gets destroyed during the epilogue of a function.
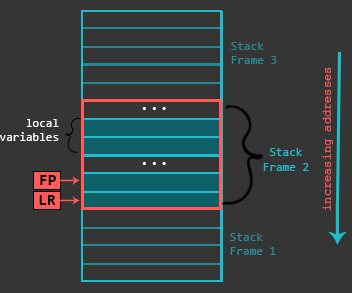
为了使堆栈使用有组织、有条理,函数使用栈帧stack frame,栈帧是专用于某个函数的堆栈的一部分内存区域。整个进程或任务的叫堆栈,某个函数的叫栈帧。
在函数起始处,分配函数的栈帧。FP会设置为栈帧的底部,SP设置为栈帧的顶部?
栈帧一般用于保存返回地址(之前的LR),之前的FR,需要保存的寄存器,函数参数(如果函数参数超过4个的话),局部变量,等。
在函数结束处,栈帧会被释放。
一个例子,
/* azeria@labs:~$ gcc func.c -o func && gdb func */
int main()
{
int res = ;
int a = ;
int b = ;
res = max(a, b);
return res;
} int max(int a,int b)
{
do_nothing();
if(a<b)
{
return b;
}
else
{
return a;
}
}
int do_nothing()
{
return ;
}

We can see in the picture above that currently we are about to leave the function max (see the arrow in the disassembly at the bottom). At this state, the FP (R11) points to 0xbefff254 which is the bottom of our Stack Frame. This address on the Stack (green addresses) stores 0x00010418 which is the return address (previous LR). 4 bytes above this (at 0xbefff250) we have a value 0xbefff26c, which is the address of a previous Frame Pointer. The 0x1 and 0x2 at addresses 0xbefff24c and 0xbefff248 are local variables(其实是输入参数) which were used during the execution of the function max. So the Stack Frame which we just analyzed had only LR, FP and two local variables.
push {r11, lr}, 在该句之前$sp=0xbefff258,在该句之后,$sp=0xbefff250
add r11, sp, #4 r11=0xbefff254,即fp
sub sp, sp, #8 之前,已经用了2个单元的堆栈,还需要两个单元用于存储max的输入参数,因此,将sp=sp-8=0xbefff248
max函数的栈帧即为0xbefff248~~0xbefff254。
str r0, [r11, #-8] 将输入参数1(放在r0传递进来的)放在max的栈帧中
str r0, [r11, #-12] 将输入参数2(放在r1传递进来的)放在max的栈帧中
。。。
sub sp, r11, #4 将r11减去4赋值给sp(应该是+4啊?),即在max结束处,将sp复原为main的栈帧,sp=0xbefff258
pop {r11, pc} 将max第一句存的lr赋值给pc,将fp恢复回来
FUNCTIONS
To understand functions in ARM we first need to get familiar with the structural parts of a function, which are:
- Prologue,起始,序曲
- Body
- Epilogue,结束,尾声
The purpose of the prologue is to save the previous state of the program (by storing values of LR and R11 onto the Stack) and set up the Stack for the local variables of the function. While the implementation of the prologue may differ depending on a compiler that was used, generally this is done by using PUSH/ADD/SUB instructions. An example of a prologue would look like this:
函数起始:
(1)保存之前的状态(将LR和R11保存到堆栈,下面第1句)
(2)设置堆栈的fp,一般是将fp=sp+4(因为之前push已经移动了2个单位)
(3)设置堆栈的sp,sp现在已经移动了2个单位,再移动剩余所需的空间即可。
push {r11, lr} /* Start of the prologue. Saving Frame Pointer and LR onto the stack */
add r11, sp, # /* Setting up the bottom of the stack frame */
sub sp, sp, # /* End of the prologue. Allocating some buffer on the stack. This also allocates space for the Stack Frame */
The body part of the function is usually responsible for some kind of unique and specific task. This part of the function may contain various instructions, branches (jumps) to other functions, etc. An example of a body section of a function can be as simple as the following few instructions:
mov r0, # /* setting up local variables (a=1). This also serves as setting up the first parameter for the function max */
mov r1, # /* setting up local variables (b=2). This also serves as setting up the second parameter for the function max */
bl max /* Calling/branching to function max */
The sample code above shows a snippet of a function which sets up local variables and then branches to another function. This piece of code also shows us that the parameters of a function (in this case function max) are passed via registers. In some cases, when there are more than 4 parameters to be passed, we would additionally use the Stack to store the remaining parameters. It is also worth mentioning, that a result of a function is returned via the register R0. So what ever the result of a function (max) turns out to be, we should be able to pick it up from the register R0 right after the return from the function. One more thing to point out is that in certain situations the result might be 64 bits in length (exceeds the size of a 32bit register). In that case we can use R0 combined with R1 to return a 64 bit result.
不超过4个的输入参数可以通过寄存器传递,若超过4个参数,则超过的需要通过堆栈传递。函数返回值也是通过R0传递。
The last part of the function, the epilogue, is used to restore the program’s state to it’s initial one (before the function call) so that it can continue from where it left of. For that we need to readjust the Stack Pointer. This is done by using the Frame Pointer register (R11) as a reference and performing add or sub operation. Once we readjust the Stack Pointer, we restore the previously (in prologue) saved register values by poping them from the Stack into respective registers. Depending on the function type, the POP instruction might be the final instruction of the epilogue. However, it might be that after restoring the register values we use BX instruction for leaving the function. An example of an epilogue looks like this:
函数结束,恢复初始状态:
(1)设置堆栈的sp,一般通过r11=fp来设置,通常应该是sp=r11+4。
(2)恢复之前保存的r11=fp和lr到r11和PC。
sub sp, r11, # /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11, pc} /* End of the epilogue. Restoring Frame Pointer from the Stack, jumping to previously saved LR via direct load into PC. The Stack Frame of a function is finally destroyed at this step. */
So now we know, that:
- Prologue sets up the environment for the function;
- Body implements the function’s logic and stores result to R0;
- Epilogue restores the state so that the program can resume from where it left of before calling the function.
Another key point to know about the functions is their types: leaf and non-leaf. The leaf function is a kind of a function which does not call/branch to another function from itself. A non-leaf function is a kind of a function which in addition to it’s own logic’s does call/branch to another function. The implementation of these two kind of functions are similar. However, they have some differences. To analyze the differences of these functions we will use the following piece of code:
另一个关于函数的要点是,函数分叶子函数和非叶子函数。叶子函数里不再继续调用其它函数,非叶子函数里会继续调用其它函数
/* azeria@labs:~$ as func.s -o func.o && gcc func.o -o func && gdb func */
.global main main:
push {r11, lr} /* Start of the prologue. Saving Frame Pointer and LR onto the stack */
add r11, sp, # /* Setting up the bottom of the stack frame */
sub sp, sp, # /* End of the prologue. Allocating some buffer on the stack */
mov r0, # /* setting up local variables (a=1). This also serves as setting up the first parameter for the max function */
mov r1, # /* setting up local variables (b=2). This also serves as setting up the second parameter for the max function */
bl max /* Calling/branching to function max */
sub sp, r11, # /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11, pc} /* End of the epilogue. Restoring Frame pointer from the stack, jumping to previously saved LR via direct load into PC */ max:
push {r11} /* Start of the prologue. Saving Frame Pointer onto the stack */
add r11, sp, # /* Setting up the bottom of the stack frame */
sub sp, sp, # /* End of the prologue. Allocating some buffer on the stack */
cmp r0, r1 /* Implementation of if(a<b) */
movlt r0, r1 /* if r0 was lower than r1, store r1 into r0 */
add sp, r11, # /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11} /* restoring frame pointer */
bx lr /* End of the epilogue. Jumping back to main via LR register */
The example above contains two functions: main, which is a non-leaf function, and max – a leaf function. As mentioned before, the non-leaf function calls/branches to another function, which is true in our case, because we branch to a function max from the function main. The function max in this case does not branch to another function within it’s body part, which makes it a leaf function.
Another key difference is the way the prologues and epilogues are implemented. The following example shows a comparison of prologues of a non-leaf and leaf functions. The main difference here is that the entry of the prologue in the non-leaf function saves more register’s onto the stack. The reason behind this is that by the nature of the non-leaf function, the LR gets modified during the execution of such a function and therefore the value of this register needs to be preserved so that it can be restored later. Generally, the prologue could save even more registers if it’s necessary.
函数起始:对于非叶子函数,因为进一步调用其它函数会改变LR寄存器,因此,在函数起始,需要将r11和LR一起压入堆栈存储。而对于叶子函数,不再调用其它函数,LR不会改变,因此,不需要将LR压入堆栈。
/* A prologue of a non-leaf function */
push {r11, lr} /* Start of the prologue. Saving Frame Pointer and LR onto the stack */
add r11, sp, # /* Setting up the bottom of the stack frame */
sub sp, sp, # /* End of the prologue. Allocating some buffer on the stack */ /* A prologue of a leaf function */
push {r11} /* Start of the prologue. Saving Frame Pointer onto the stack */
add r11, sp, # /* Setting up the bottom of the stack frame */
sub sp, sp, # /* End of the prologue. Allocating some buffer on the stack */
The comparison of the epilogues of the leaf and non-leaf functions, which we see below, shows us that the program’s flow is controlled in different ways: by branching to an address stored in the LR register in the leaf function’s case and by direct POP to PC register in the non-leaf function.
函数结束:对于叶子函数,可以直接bx lr,跳转到LR处继续执行,因为,LR未改变。BX的意思为Branch and eXchange ARM/Thumb模式。
对于非叶子函数,需要将之前保存的LR恢复给PC,来继续执行。
/* An epilogue of a leaf function */
add sp, r11, # /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11} /* restoring frame pointer */
bx lr /* End of the epilogue. Jumping back to main via LR register */ /* An epilogue of a non-leaf function */
sub sp, r11, # /* Start of the epilogue. Readjusting the Stack Pointer */
pop {r11, pc} /* End of the epilogue. Restoring Frame pointer from the stack, jumping to previously saved LR via direct load into PC */
Finally, it is important to understand the use of BL and BX instructions here. In our example, we branched to a leaf function by using a BL instruction. We use the the label of a function as a parameter to initiate branching. During the compilation process, the label gets replaced with a memory address. Before jumping to that location, the address of the next instruction is saved (linked) to the LR register so that we can return back to where we left off when the function max is finished.
在BL的时候,将调用指令的下一条指令地址已经保存(链接)在了LR寄存器。
The BX instruction, which is used to leave the leaf function, takes LR register as a parameter. As mentioned earlier, before jumping to function max the BL instruction saved the address of the next instruction of the function main into the LR register. Due to the fact that the leaf function is not supposed to change the value of the LR register during it’s execution, this register can be now used to return to the parent (main) function. As explained in the previous chapter, the BX instruction can eXchange between the ARM/Thumb modes during branching operation. In this case, it is done by inspecting the last bit of the LR register: if the bit is set to 1, the CPU will change (or keep) the mode to thumb, if it’s set to 0, the mode will be changed (or kept) to ARM. This is a nice design feature which allows to call functions from different modes.
BX LR指令中LR寄存器的最后1bit还可以用于切换ARM和Thumb模式。
最后一个关于叶子函数和非叶子函数的例子,gif动态图很长,可以用一些gif编辑软件,暂停看。

ARM和Sparc比较
之前整理的Sparc的原理,Sparc V8 汇编指令、寄存器窗口、堆栈、函数调用,https://www.cnblogs.com/yanhc/p/12255886.html
关于函数的调用和返回
ARM
ARM跳转有BL指令,Branch Link(Saves (PC+4) in LR and jumps to function),即首先将跳转指令的下一条指令地址保存在LR寄存器中,以便调用函数返回时能找到返回地址,然后执行跳转。
如果是non-leaf函数,在调用函数起始,则会将LR和r11=fp都压入堆栈,在结束时,则弹出给PC和r11;
如果是leaf函数,在调用函数起始,则只会将r11=fp压入堆栈,在结束时,则弹出给r11,同时跳转到LR,bx lr。
Sparc
对于Sparc处理器,在执行call label时,会将PC拷贝到o7(r15,address of call instruction),call指令本身叫call and link,其中link与ARM中BL的link是一个意思,即保存一个调用函数的链接。不同的是ARM保存的是跳转指令的下一条指令地址,Sparc保存的是跳转指令地址,这没关系,对于Sparc来说,只需在返回的时候+4即可得到下一条要执行的地址,即返回的地址。
在调用函数起始,如果是非叶子函数,会执行save,旋转寄存器窗口,该动作相当于将o7=LR保存起来,同时,上一窗口的sp保存在当前窗口的fp中。如果是叶子函数,则不会旋转寄存器窗口。
在调用函数结束,返回是ret和retl(retl中l为leaf的意思)。注意到call的时候将PC放在了o7中,所以,返回时,只需要跳转到o7+8即可。
而对于leaf和non-leaf又有点差别,
对于leaf函数,没有执行save,没有寄存器旋转,因此,retl指令jmpl的目标地址为o7+8;
而对于non-leaf函数,执行了save,有寄存器旋转,之前的o7变为现在的i7,因此ret指令jmpl的目标地址为i7+8。
同时,对于sparc来说,在non-leaf中还会restore,将寄存器旋转回来;在leaf中则没有restore。
关于函数调用时的frame pointer,fp保存
对于ARM,r11为fp。在调用callee函数中,会
(1)将fp和lr压入堆栈push {r11, lr},
(2)让fp=sp,add r11, sp, #0,
(3)sp减去栈帧长度,sub sp, sp, #16。
对于Sparc,fp=i6,sp=o6。在调用callee函数中,执行save %sp, -1024, %sp时,寄存器窗口会旋转,从而做了
(1)将fp和lr压入堆栈(当前未使用的寄存器窗口发挥了部分堆栈的作用),
(2)让fp=sp(fp=i6,sp=o6,以及寄存器窗口旋转方向,完成了fp=sp操作),
(3)sp减去栈帧长度(save有add的作用)。
总结一下函数调用和返回
调用时,要保存返回地址,arm用BL保存在LR,sparc用call保存在o7。
调用函数的起始:要保存返回地址和栈帧(通过保存fp),同时更新栈帧。arm将r11,fp压入堆栈,sub sp;sparc用save旋转寄存器将o7和fp保存起来,同时sub sp。
调用函数的结束:跳转到返回地址,同时恢复栈帧。arm令sp=r11,出栈r11和LR到r11和pc;sparc用ret返回(jmpl o7+8),同时用restore旋转寄存器恢复sp=fp。
ARM处理器的堆栈和函数调用,以及与Sparc的比较的更多相关文章
- ARM处理器的寄存器,ARM与Thumb状态,7中运行模式 【转】
转自:http://blog.chinaunix.net/uid-28458801-id-3494646.html ARM处理器工作模式一共有 7 种 : USR 模式 正常用户模式,程序正常 ...
- ARM处理器的寄存器,ARM与Thumb状态,7中运行模式
** ARM处理器的寄存器,ARM与Thumb状态,7中运行模式 分类: 嵌入式 ARM处理器工作模式一共有 7 种 : USR 模式 正常用户模式,程序正常执行模式 FIQ模式(Fast ...
- ARM处理器解析
按图分析: ARM处理器有七种工作模式,为的是形成不同的使用级别,以防造成对系统的破坏.不同模式可以访问的寄存器不同,可以运行的指令不同. (1)user(10000):普通应用程序运行的模式(应用程 ...
- ARM处理器寄存器
参考:ARM Architecture Reference Manual的39页 1.ARM处理器寄存器纵览 ARM微处理器共有37个32位寄存器,其中31个为通用寄存器(R13和R13_svc不是同 ...
- [国嵌笔记][021-022][ARM处理器工作模式]
[ARM处理器工作模式] 处理器工作模式 1.User(urs):用户模式,linux应用程序运行在用户模式 2.FIQ(fiq):快速中断模式 3.IRQ(irq):中断模式 4.Superviso ...
- 基于ARM处理器的反汇编器软件简单设计及实现
写在前面 2012年写的毕业设计,仅供参考 反汇编的目的 缺乏某些必要的说明资料的情况下, 想获得某些软件系统的源代码.设计思想及理念, 以便复制, 改造.移植和发展: 从源码上对软件的可靠性和安全性 ...
- 热烈祝贺华清远见《ARM处理器开发详解》第2版正式出版
2014年6月,由华清远见研发中心组织多名业 内顶尖讲师编写的<ARM处理器开发详解>一书正式出版.本书以S5PV210处理器为平台,详细介绍了嵌入式系统开发的各个主要环节,并注重实践,辅 ...
- ARM处理器的寄存器
在ARM体系中通常有以下3种方式控制程序的执行流程: **在正常执行过程中,每执行一条ARM指令,程序计数器(PC)的值加4个字节:每执行一条Thumb指令,程序计数器寄存器(PC)加2个字节.整个过 ...
- ARM 处理器的几个相关术语
生产ARM的厂商很多,自然ARM处理器的名字就五花八门.但是,它们有些共同点,那就是:架构和核心. 架构这个概念太宽不太懂,一般不同的架构会有不同的指令集,在不同的架构下面还可以有多种核心.核心就是指 ...
随机推荐
- PyMuPDF库(处理PDF)
昨天在公司需要把一份PDF格式认证表转换为图片JPEG格式,所以在网上查询了一些与此相关的python库,最后看网上大多都是使用Wand和PyMuPDF,在安装了Wand库后,导入相应的模块后报错了, ...
- fsLayuiPlugin联动表格使用(一)
简单联动表格使用 点击主表格,加载副表格数据, 演示地址:http://fslayuiplugin.fallsea.com/views/linkageDatagrid/index.html 联动表格配 ...
- frp 内网穿透访问内网Web服务
ps:最近想要通过域名(公网)访问或者测试在本地搭建的 web 服务(不想在公网IP服务器上再部署个服务,也不想通过teamview等工具远程卡到爆!), 由于本地机器没有公网 IP,无法将域名解析到 ...
- RabbitMQ面试题集锦(精选)(另附思维导图)
1.使用RabbitMQ有什么好处? 1.解耦,系统A在代码中直接调用系统B和系统C的代码,如果将来D系统接入,系统A还需要修改代码,过于麻烦! 2.异步,将消息写入消息队列,非必要的业务逻辑以异步的 ...
- 手机app抓包工具,安卓手机adb无线连接
默认手机已经usb调试配置完成 网络必须在同一网络中,每次断开wifi连接,都必须重新重做一次 使用数据线连接电脑 cmd 打开一个命令行 输入 # abd如果没有配置环境变量,请配置或者进入adb文 ...
- TypeScript Jest 调试
本文简要介绍了如何在 Jest 单元测试中利用 Chrome Node DevTools 来辅助调试. 背景 代码是 TS 写的 所测功能无 UI 界面,出现Bug后不容易定位 用 console 式 ...
- Mathtype快捷键&小技巧
Mathtype使用方便,能插入到Office等编辑器中,Latex公式在某些地方更加通用,如网页和书籍. 1. Mathtype简介 数学公式编辑器(MathType)是一款专业的数学公式编辑工具, ...
- php通过单例模式使一个类只能创建一个对象。
单例模式也就是一个类只能创建出一个对象 首先你要知道它的基本思想为:三私一公! 何为三私一公? 1(私).防止用户通过构造方法创建对象,因此私有化构造方法. 2(公).创建一个公共静态函数用来进入 ...
- ASP.net MVC 构建layui管理后台(整体效果)
登录页: 首页 模块管理 角色管理,角色分配 用户管理
- *fetch(_, { call, put }) { --- generator
effects: { *fetch(_, { call, put }) { const response = yield call(queryUsers); yield put({ type: 'sa ...