TensorFlow v2.0实现逻辑斯谛回归
使用TensorFlow v2.0实现逻辑斯谛回归
此示例使用简单方法来更好地理解训练过程背后的所有机制
MNIST数据集概览
此示例使用MNIST手写数字。该数据集包含60,000个用于训练的样本和10,000个用于测试的样本。这些数字已经过尺寸标准化并位于图像中心,图像是固定大小(28x28像素),其值为0到255。
在此示例中,每个图像将转换为float32,归一化为[0,1],并展平为784个特征(28 * 28)的1维数组。

from __future__ import absolute_import,division,print_function
import tensorflow as tf
import numpy as np
# MNIST 数据集参数
num_classes = 10 # 数字0-9
num_features = 784 # 28*28
# 训练参数
learning_rate = 0.01
training_steps = 1000
batch_size = 256
display_step = 50
# 准备MNIST数据
from tensorflow.keras.datasets import mnist
(x_train, y_train),(x_test,y_test) = mnist.load_data()
# 转换为float32
x_train, x_test = np.array(x_train, np.float32), np.array(x_test, np.float32)
# 将图像平铺成784个特征的一维向量(28*28)
x_train, x_test = x_train.reshape([-1, num_features]), x_test.reshape([-1, num_features])
# 将像素值从[0,255]归一化为[0,1]
x_train,x_test = x_train / 255, x_test / 255
# 使用tf.data api 对数据随机分布和批处理
train_data = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_data = train_data.repeat().shuffle(5000).batch(batch_size).prefetch(1)
# 权值矩阵形状[784,10],28 * 28图像特征数和类别数目
W = tf.Variable(tf.ones([num_features, num_classes]), name="weight")
# 偏置形状[10], 类别数目
b = tf.Variable(tf.zeros([num_classes]), name="bias")
# 逻辑斯谛回归(Wx b)
def logistic_regression(x):
#应用softmax将logits标准化为概率分布
return tf.nn.softmax(tf.matmul(x,W) b)
# 交叉熵损失函数
def cross_entropy(y_pred, y_true):
# 将标签编码为一个独热编码向量
y_true = tf.one_hot(y_true, depth=num_classes)
# 压缩预测值以避免log(0)错误
y_pred = tf.clip_by_value(y_pred, 1e-9, 1.)
# 计算交叉熵
return tf.reduce_mean(-tf.reduce_sum(y_true * tf.math.log(y_pred)))
# 准确率度量
def accuracy(y_pred, y_true):
# 预测的类别是预测向量中最高分的索引(即argmax)
correct_prediction = tf.equal(tf.argmax(y_pred, 1), tf.cast(y_true, tf.int64))
return tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 随机梯度下降优化器
optimizer = tf.optimizers.SGD(learning_rate)
# 优化过程
def run_optimization(x, y):
#将计算封装在GradientTape中以实现自动微分
with tf.GradientTape() as g:
pred = logistic_regression(x)
loss = cross_entropy(pred, y)
# 计算梯度
gradients = g.gradient(loss, [W, b])
# 根据gradients更新 W 和 b
optimizer.apply_gradients(zip(gradients, [W, b]))
# 针对给定训练步骤数开始训练
for step, (batch_x,batch_y) in enumerate(train_data.take(training_steps), 1):
# 运行优化以更新W和b值
run_optimization(batch_x, batch_y)
if step % display_step == 0:
pred = logistic_regression(batch_x)
loss = cross_entropy(pred, batch_y)
acc = accuracy(pred, batch_y)
print("step: %i, loss: %f, accuracy: %f" % (step, loss, acc))
output:
step: 50, loss: 608.584717, accuracy: 0.824219
step: 100, loss: 828.206482, accuracy: 0.765625
step: 150, loss: 716.329407, accuracy: 0.746094
step: 200, loss: 584.887634, accuracy: 0.820312
step: 250, loss: 472.098114, accuracy: 0.871094
step: 300, loss: 621.834595, accuracy: 0.832031
step: 350, loss: 567.288818, accuracy: 0.714844
step: 400, loss: 489.062988, accuracy: 0.847656
step: 450, loss: 496.466675, accuracy: 0.843750
step: 500, loss: 465.342224, accuracy: 0.875000
step: 550, loss: 586.347168, accuracy: 0.855469
step: 600, loss: 95.233109, accuracy: 0.906250
step: 650, loss: 88.136490, accuracy: 0.910156
step: 700, loss: 67.170349, accuracy: 0.937500
step: 750, loss: 79.673691, accuracy: 0.921875
step: 800, loss: 112.844872, accuracy: 0.914062
step: 850, loss: 92.789581, accuracy: 0.894531
step: 900, loss: 80.116165, accuracy: 0.921875
step: 950, loss: 45.706650, accuracy: 0.925781
step: 1000, loss: 72.986969, accuracy: 0.925781
# 在验证集上测试模型
pred = logistic_regression(x_test)
print("Test Accuracy: %f" % accuracy(pred, y_test))
output:
Test Accuracy: 0.901100
# 可视化预测
import matplotlib.pyplot as plt
# 在验证集上中预测5张图片
n_images = 5
test_images = x_test[:n_images]
predictions = logistic_regression(test_images)
# 可视化图片和模型预测结果
for i in range(n_images):
plt.imshow(np.reshape(test_images[i],[28,28]), cmap='gray')
plt.show()
print("Model prediction: %i" % np.argmax(predictions.numpy()[i]))
output:
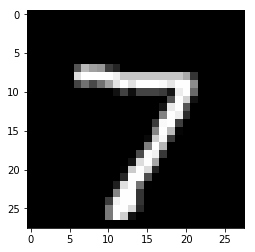
Model prediction: 7
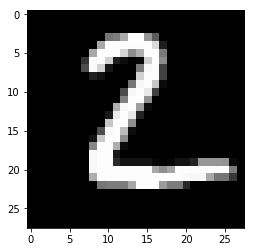
Model prediction: 2
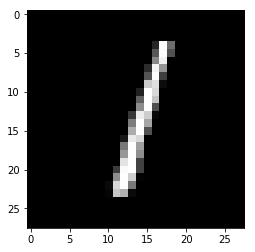
Model prediction: 1
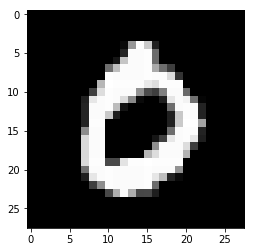
Model prediction: 0
Model prediction: 4
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
欢迎关注PyTorch官方中文教程站:
http://pytorch.panchuang.net/
TensorFlow v2.0实现逻辑斯谛回归的更多相关文章
- 使用TensorFlow v2.0构建多层感知器
使用TensorFlow v2.0构建一个两层隐藏层完全连接的神经网络(多层感知器). 这个例子使用低级方法来更好地理解构建神经网络和训练过程背后的所有机制. 神经网络概述 MNIST 数据集概述 此 ...
- 使用TensorFlow v2.0构建卷积神经网络
使用TensorFlow v2.0构建卷积神经网络. 这个例子使用低级方法来更好地理解构建卷积神经网络和训练过程背后的所有机制. CNN 概述 MNIST 数据集概述 此示例使用手写数字的MNIST数 ...
- TensorFlow v2.0实现Word2Vec算法
使用TensorFlow v2.0实现Word2Vec算法计算单词的向量表示,这个例子是使用一小部分维基百科文章来训练的. 更多信息请查看论文: Mikolov, Tomas et al. " ...
- TensorFlow v2.0的基本张量操作
使用TensorFlow v2.0的基本张量操作 from __future__ import print_function import tensorflow as tf # 定义张量常量 a = ...
- 在Anaconda3环境下安装并切换 Tensorflow 2.0 环境
背景 Anaconda切换各种环境非常方便,现在我们就来介绍一下如何使用anaconda安装tensorflow环境. anaconda v3.5 from 清华镜像站 tensorflow v2.0 ...
- TensorFlow 2.0 新特性
安装 TensorFlow 2.0 Alpha 本文仅仅介绍 Windows 的安装方式: pip install tensorflow==2.0.0-alpha0 # cpu 版本 pip inst ...
- TensorFlow 2.0高效开发指南
Effective TensorFlow 2.0 为使TensorFLow用户更高效,TensorFlow 2.0中进行了多出更改.TensorFlow 2.0删除了篇冗余API,使API更加一致(统 ...
- 三分钟快速上手TensorFlow 2.0 (下)——模型的部署 、大规模训练、加速
前文:三分钟快速上手TensorFlow 2.0 (中)——常用模块和模型的部署 TensorFlow 模型导出 使用 SavedModel 完整导出模型 不仅包含参数的权值,还包含计算的流程(即计算 ...
- 使用TensorFlow v2库实现线性回归
使用TensorFlow v2库实现线性回归 此示例使用简单方法来更好地理解训练过程背后的所有机制 from __future__ import absolute_import, division, ...
随机推荐
- NIPS 2016:普及机器学习
2016:普及机器学习" title="NIPS 2016:普及机器学习"> 左起:微软研究员Robert Schapire,John Langford,Al ...
- Spring-cloud微服务实战【十】:消息总线Bus
回忆一下,在上一篇文章中,我们使用了分布式配置中心config来管理所有微服务的配置文件,那这样有没有什么问题?有,那就是无法配置文件无法自动更新,当我的git服务器上的配置文件更新后,不能同步更 ...
- 编写一个可复用的SpringBoot应用运维脚本
前提 作为Java开发者,很多场景下会使用SpringBoot开发Web应用,目前微服务主流SpringCloud全家桶也是基于SpringBoot搭建的.SpringBoot应用部署到服务器上,需要 ...
- Golang/Python/PHP带你彻底学会gRPC
目录 一.gRPC是什么? 二.Protocol Buffers是什么? 三.需求:开发健身房服务 四.最佳实践 Golang 1. 安装protoc工具 2. 安装protoc-gen-go 3. ...
- 将mysql数据库集成到idea中
将mysql数据库集成到idea中
- 如何看待Java是世界上最好的语言?
Java出现二十多年以来,一直都是主流的开发语言,Java创建于 1995 年,在 20多年的发展历程中,Java 已经证明自己是用于自定义软件开发的顶级通用编程语言. Java 广泛应用于科学教育. ...
- PHP压缩文件夹 php
$path = PUBLIC_DIR.'/images/'; //待压缩文件夹父目录 $zipPath = PUBLIC_DIR.'/images_zip/'; //压缩文件保存目录 !is_dir( ...
- 第一篇:注册中心Eureka
1.什么是Eureka,有什么用? Eureka是Netflix开源的一款提供服务注册和发现的产品,它提供了完整的Service Registry和Service Discovery实现.也是spri ...
- SIP 协议详解
SIP 协议详解 2013年参与过一个"视频通讯的App"项目,使用Sip协议通信.当时通信协议这块不是自己负责,加上时间紧.任务重等方面的原因,一直未对Sip协议进行过深入的了解 ...
- Java基础篇(02):特殊的String类,和相关扩展API
本文源码:GitHub·点这里 || GitEE·点这里 一.String类简介 1.基础简介 字符串是一个特殊的数据类型,属于引用类型.String类在Java中使用关键字final修饰,所以这个类 ...