python2.7 操作ceph-cluster S3对象接口 实现: 上传 下载 查询 删除 顺便使用Docker装个owncloud 实现UI管理
python version: python2.7
需要安装得轮子:
boto
filechunkio command:
yum install python-pip&& pip install boto filechunkio ceph集群user(ceph-s3) 和 用户access_key,secret_key
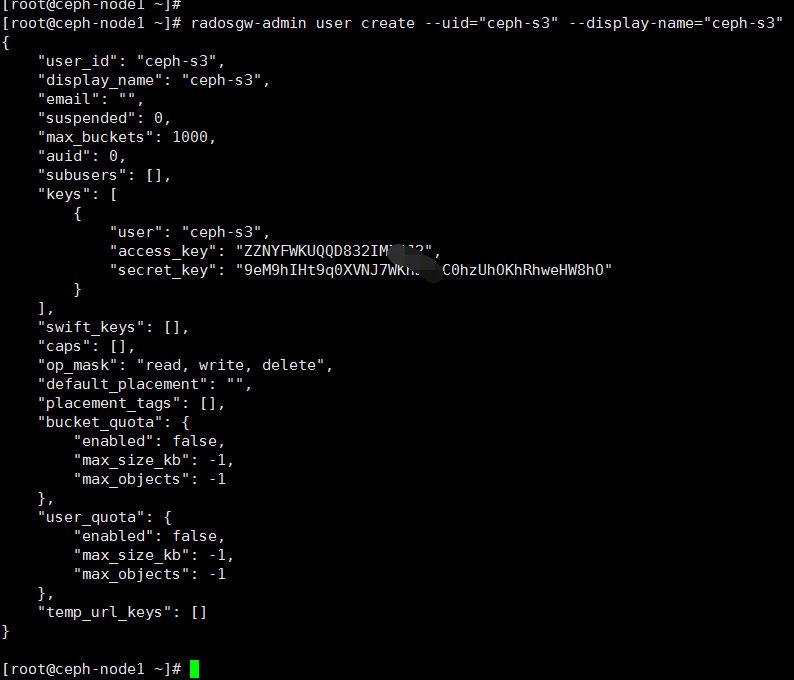
代码:
#_*_coding:utf-8_*_
#yum install python-boto
import boto
import boto.s3.connection
#pip install filechunkio
from filechunkio import FileChunkIO
import math
import threading
import os
import Queue
import sys
class Chunk(object):
num = 0
offset = 0
len = 0
def __init__(self,n,o,l):
self.num=n
self.offset=o
self.length=l
#条件判断工具类
class switch(object):
def __init__(self, value):
self.value = value
self.fall = False
def __iter__(self):
"""Return the match method once, then stop"""
yield self.match
raise StopIteration def match(self, *args):
"""Indicate whether or not to enter a case suite"""
if self.fall or not args:
return True
elif self.value in args: # changed for v1.5, see below
self.fall = True
return True
else:
return False class CONNECTION(object):
def __init__(self,access_key,secret_key,ip,port,is_secure=False,chrunksize=8<<20): #chunksize最小8M否则上传过程会报错
self.conn=boto.connect_s3(
aws_access_key_id=access_key,
aws_secret_access_key=secret_key,
host=ip,port=port,
is_secure=is_secure,
calling_format=boto.s3.connection.OrdinaryCallingFormat()
)
self.chrunksize=chrunksize
self.port=port #查询buckets内files
def list_all(self):
all_buckets=self.conn.get_all_buckets()
for bucket in all_buckets:
print u'PG容器名: %s' %(bucket.name)
for key in bucket.list():
print ' '*5,"%-20s%-20s%-20s%-40s%-20s" %(key.mode,key.owner.id,key.size,key.last_modified.split('.')[0],key.name) #查询所有buckets
def get_show_buckets(self):
for bucket in self.conn.get_all_buckets():
print "Ceph-back-Name: {name}\tCreateTime: {created}".format(
name=bucket.name,
created=bucket.creation_date,
) def list_single(self,bucket_name):
try:
single_bucket = self.conn.get_bucket(bucket_name)
except Exception as e:
print 'bucket %s is not exist' %bucket_name
return
print u'容器名: %s' % (single_bucket.name)
for key in single_bucket.list():
print ' ' * 5, "%-20s%-20s%-20s%-40s%-20s" % (key.mode, key.owner.id, key.size, key.last_modified.split('.')[0], key.name) #普通小文件下载:文件大小<=8M
def dowload_file(self,filepath,key_name,bucket_name):
all_bucket_name_list = [i.name for i in self.conn.get_all_buckets()]
if bucket_name not in all_bucket_name_list:
print 'Bucket %s is not exist,please try again' % (bucket_name)
return
else:
bucket = self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()]
if key_name not in all_key_name_list:
print 'File %s is not exist,please try again' % (key_name)
return
else:
key = bucket.get_key(key_name) if not os.path.exists(os.path.dirname(filepath)):
print 'Filepath %s is not exists, sure to create and try again' % (filepath)
return if os.path.exists(filepath):
while True:
d_tag = raw_input('File %s already exists, sure you want to cover (Y/N)?' % (key_name)).strip()
if d_tag not in ['Y', 'N'] or len(d_tag) == 0:
continue
elif d_tag == 'Y':
os.remove(filepath)
break
elif d_tag == 'N':
return
os.mknod(filepath)
try:
key.get_contents_to_filename(filepath)
except Exception:
pass # 普通小文件上传:文件大小<=8M
def upload_file(self,filepath,key_name,bucket_name):
try:
bucket = self.conn.get_bucket(bucket_name)
except Exception as e:
print 'bucket %s is not exist' % bucket_name
tag = raw_input('Do you want to create the bucket %s: (Y/N)?' % bucket_name).strip()
while tag not in ['Y', 'N']:
tag = raw_input('Please input (Y/N)').strip()
if tag == 'N':
return
elif tag == 'Y':
self.conn.create_bucket(bucket_name)
bucket = self.conn.get_bucket(bucket_name)
all_key_name_list = [i.name for i in bucket.get_all_keys()]
if key_name in all_key_name_list:
while True:
f_tag = raw_input(u'File already exists, sure you want to cover (Y/N)?: ').strip()
if f_tag not in ['Y', 'N'] or len(f_tag) == 0:
continue
elif f_tag == 'Y':
break
elif f_tag == 'N':
return
key=bucket.new_key(key_name)
if not os.path.exists(filepath):
print 'File %s does not exist, please make sure you want to upload file path and try again' %(key_name)
return
try:
f=file(filepath,'rb')
data=f.read()
key.set_contents_from_string(data)
except Exception:
pass #删除bucket内file
def delete_file(self,key_name,bucket_name):
all_bucket_name_list = [i.name for i in self.conn.get_all_buckets()]
if bucket_name not in all_bucket_name_list:
print 'Bucket %s is not exist,please try again' % (bucket_name)
return
else:
bucket = self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()]
if key_name not in all_key_name_list:
print 'File %s is not exist,please try again' % (key_name)
return
else:
key = bucket.get_key(key_name) try:
bucket.delete_key(key.name)
except Exception:
pass #删除bucket
def delete_bucket(self,bucket_name):
all_bucket_name_list = [i.name for i in self.conn.get_all_buckets()]
if bucket_name not in all_bucket_name_list:
print 'Bucket %s is not exist,please try again' % (bucket_name)
return
else:
bucket = self.conn.get_bucket(bucket_name) try:
self.conn.delete_bucket(bucket.name)
except Exception:
pass #队列生成
def init_queue(self,filesize,chunksize): #8<<20 :8*2**20
chunkcnt=int(math.ceil(filesize*1.0/chunksize))
q=Queue.Queue(maxsize=chunkcnt)
for i in range(0,chunkcnt):
offset=chunksize*i
length=min(chunksize,filesize-offset)
c=Chunk(i+1,offset,length)
q.put(c)
return q #分片上传object
def upload_trunk(self,filepath,mp,q,id):
while not q.empty():
chunk=q.get()
fp=FileChunkIO(filepath,'r',offset=chunk.offset,bytes=chunk.length)
mp.upload_part_from_file(fp,part_num=chunk.num)
fp.close()
q.task_done() #文件大小获取---->S3分片上传对象生成----->初始队列生成(--------------->文件切,生成切分对象)
def upload_file_multipart(self,filepath,key_name,bucket_name,threadcnt=8):
filesize=os.stat(filepath).st_size
try:
bucket=self.conn.get_bucket(bucket_name)
except Exception as e:
print 'bucket %s is not exist' % bucket_name
tag=raw_input('Do you want to create the bucket %s: (Y/N)?' %bucket_name).strip()
while tag not in ['Y','N']:
tag=raw_input('Please input (Y/N)').strip()
if tag == 'N':
return
elif tag == 'Y':
self.conn.create_bucket(bucket_name)
bucket = self.conn.get_bucket(bucket_name)
all_key_name_list=[i.name for i in bucket.get_all_keys()]
if key_name in all_key_name_list:
while True:
f_tag=raw_input(u'File already exists, sure you want to cover (Y/N)?: ').strip()
if f_tag not in ['Y','N'] or len(f_tag) == 0:
continue
elif f_tag == 'Y':
break
elif f_tag == 'N':
return mp=bucket.initiate_multipart_upload(key_name)
q=self.init_queue(filesize,self.chrunksize)
for i in range(0,threadcnt):
t=threading.Thread(target=self.upload_trunk,args=(filepath,mp,q,i))
t.setDaemon(True)
t.start()
q.join()
mp.complete_upload() #文件分片下载
def download_chrunk(self,filepath,key_name,bucket_name,q,id):
while not q.empty():
chrunk=q.get()
offset=chrunk.offset
length=chrunk.length
bucket=self.conn.get_bucket(bucket_name)
resp=bucket.connection.make_request('GET',bucket_name,key_name,headers={'Range':"bytes=%d-%d" %(offset,offset+length)})
data=resp.read(length)
fp=FileChunkIO(filepath,'r+',offset=chrunk.offset,bytes=chrunk.length)
fp.write(data)
fp.close()
q.task_done() #下载 > 8MB file
def download_file_multipart(self,filepath,key_name,bucket_name,threadcnt=8):
all_bucket_name_list=[i.name for i in self.conn.get_all_buckets()]
if bucket_name not in all_bucket_name_list:
print 'Bucket %s is not exist,please try again' %(bucket_name)
return
else:
bucket=self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()]
if key_name not in all_key_name_list:
print 'File %s is not exist,please try again' %(key_name)
return
else:
key=bucket.get_key(key_name) if not os.path.exists(os.path.dirname(filepath)):
print 'Filepath %s is not exists, sure to create and try again' % (filepath)
return if os.path.exists(filepath):
while True:
d_tag = raw_input('File %s already exists, sure you want to cover (Y/N)?' % (key_name)).strip()
if d_tag not in ['Y', 'N'] or len(d_tag) == 0:
continue
elif d_tag == 'Y':
os.remove(filepath)
break
elif d_tag == 'N':
return
os.mknod(filepath)
filesize=key.size
q=self.init_queue(filesize,self.chrunksize)
for i in range(0,threadcnt):
t=threading.Thread(target=self.download_chrunk,args=(filepath,key_name,bucket_name,q,i))
t.setDaemon(True)
t.start()
q.join() #生成下载URL
def generate_object_download_urls(self,key_name,bucket_name,valid_time=0):
all_bucket_name_list = [i.name for i in self.conn.get_all_buckets()]
if bucket_name not in all_bucket_name_list:
print 'Bucket %s is not exist,please try again' % (bucket_name)
return
else:
bucket = self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()]
if key_name not in all_key_name_list:
print 'File %s is not exist,please try again' % (key_name)
return
else:
key = bucket.get_key(key_name) try:
key.set_canned_acl('public-read')
download_url = key.generate_url(valid_time, query_auth=False, force_http=True)
if self.port != 80:
x1=download_url.split('/')[0:3]
x2=download_url.split('/')[3:]
s1=u'/'.join(x1)
s2=u'/'.join(x2) s3=':%s/' %(str(self.port))
download_url=s1+s3+s2
print download_url except Exception:
pass #操作对象
class ceph_object(object):
def __init__(self,conn):
self.conn=conn def operation_cephCluster(self,filepath,command):
back = os.path.dirname(filepath).strip('/')
path = os.path.basename(filepath) for case in switch(command):
if case('delfile'):
print "正在删除:"+back+"__BACK文件夹中___FileName:"+path
self.conn.delete_file(path,back)
self.conn.list_single(back)
break
if case('push'): #未实现超过8MB文件上传判断
print "上传到:"+back+"__BACK文件夹中___FileName:"+path
self.conn.create_bucket(back)
self.conn.upload_file_multipart(filepath,path,back)
self.conn.list_single(back)
break
if case('pull'):#未实现超过8MB文件上传判断
print "下载:"+back+"back文件中___FileName:"++path
conn.download_file_multipart(filepath,path,back)
os.system('ls -al')
break
if case('delback'):
print "删除:"+back+"-back文件夹"
self.conn.delete_bucket(back)
self.conn.list_all()
break
if case('check'):
print "ceph-cluster所有back:"
self.conn.get_show_buckets()
break
if case('checkfile'):
self.conn.list_all()
break
if case('creaetback'):
self.conn.create_bucket(back)
self.conn.get_show_buckets()
break
if case(): # default, could also just omit condition or 'if True'
print "something else! input null"
# No need to break here, it'll stop anyway if __name__ == '__main__':
access_key = 'ZZNYFWKUQQD832IMIGJ2'
secret_key = '9eM9hIHt9q0XVNJ7WKhBPlC0hzUhOKhRhweHW8hO'
conn=CONNECTION(access_key,secret_key,'192.168.100.23',7480)
ceph_object(conn).operation_cephCluster(sys.argv[1], sys.argv[2]) #Linux 操作
# ceph_object(conn).operation_cephCluster('/my-first-s31-bucket/Linux.pdf','check')
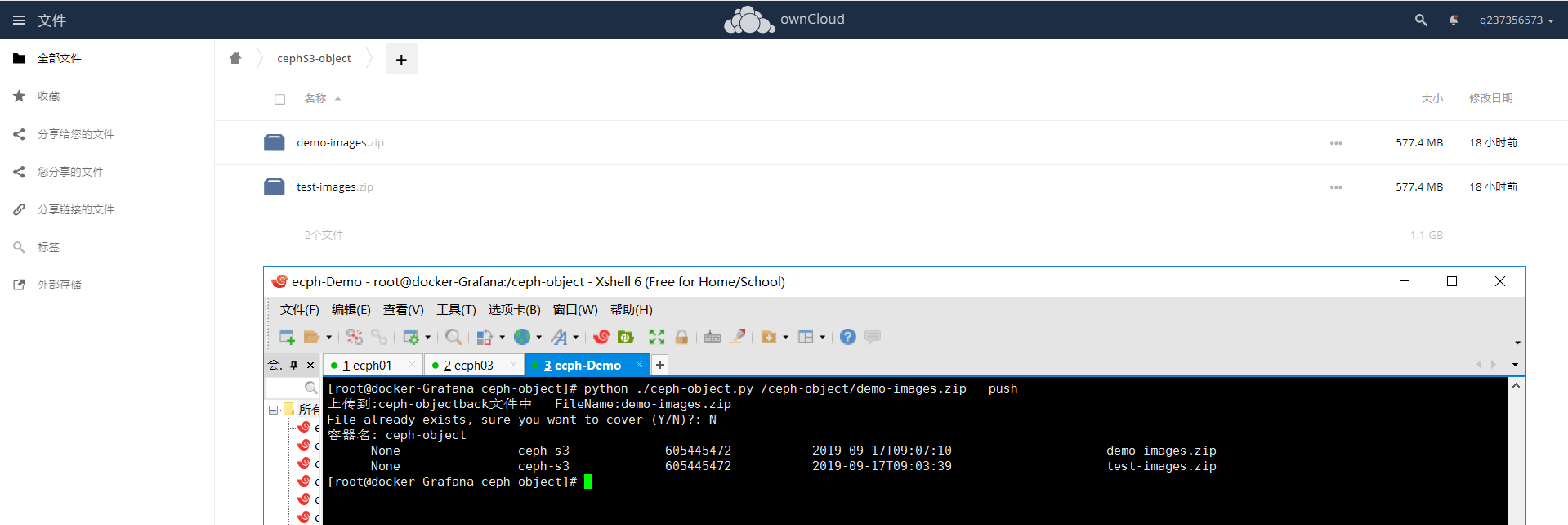
在来张图吧:
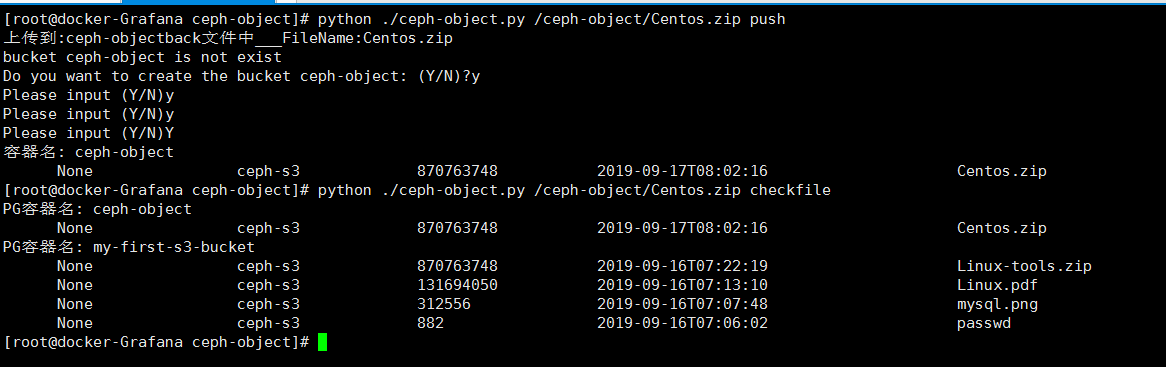
当然你还可以用docker , docker-compose 搭一个owncloud 实现对ceph-cluster WEB Ui界面管理
docker-compose 编排代码如下:
version: ''
services:
owncloud:
image: owncloud
restart: always
links:
- mysql:mysql
volumes:
- "./owncloud-data/owncloud:/var/www/html/data"
ports:
- 80:80
mysql:
image: migs/mysql-5.7
restart: always
volumes:
- "./mysql-data:/var/lib/mysql"
ports:
- 3306:3306
environment:
MYSQL_ROOT_PASSWORD: ""
MYSQL_DATABASE: ownCloud
配置如下:
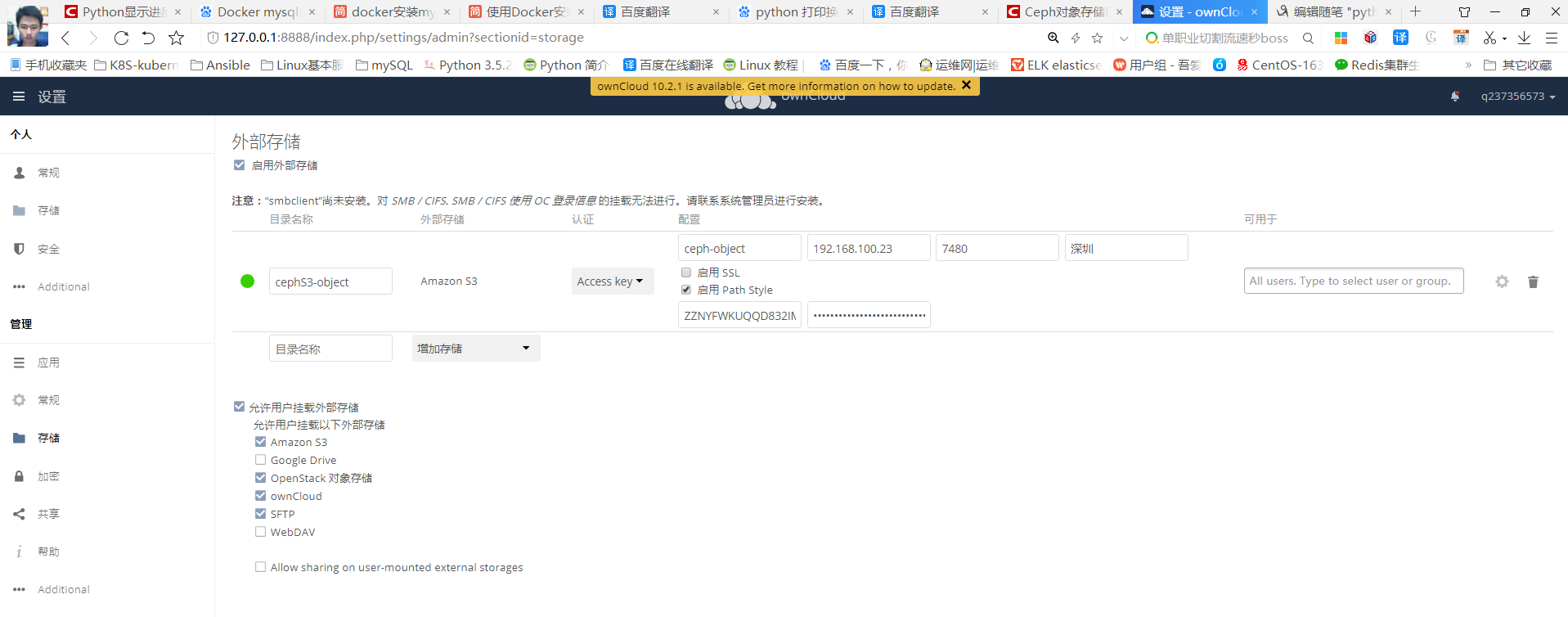
最终效果
python2.7 操作ceph-cluster S3对象接口 实现: 上传 下载 查询 删除 顺便使用Docker装个owncloud 实现UI管理的更多相关文章
- Java 客户端操作 FastDFS 实现文件上传下载替换删除
FastDFS 的作者余庆先生已经为我们开发好了 Java 对应的 SDK.这里需要解释一下:作者余庆并没有及时更新最新的 Java SDK 至 Maven 中央仓库,目前中央仓库最新版仍旧是 1.2 ...
- Python 自动化paramiko操作linux使用shell命令,以及文件上传下载linux与windows之间的实现
# coding=utf8 import paramiko """ /* python -m pip install paramiko python version 3. ...
- AWS S3 API实现文件上传下载
http://blog.csdn.net/marvin198801/article/details/47662965
- 如何利用京东云的对象存储(OSS)上传下载文件
作者:刘冀 在公有云厂商里都有对象存储,京东云也不例外,而且也兼容S3的标准因此可以利用相关的工具去上传下载文件,本文主要记录一下利用CloudBerry Explorer for Amazon S3 ...
- Django 08 Django模型基础3(关系表的数据操作、表关联对象的访问、多表查询、聚合、分组、F、Q查询)
Django 08 Django模型基础3(关系表的数据操作.表关联对象的访问.多表查询.聚合.分组.F.Q查询) 一.关系表的数据操作 #为了能方便学习,我们进入项目的idle中去执行我们的操作,通 ...
- java微信接口之四—上传素材
一.微信上传素材接口简介 1.请求:该请求是使用post提交地址为: https://api.weixin.qq.com/cgi-bin/media/uploadnews?access_token=A ...
- jm解决乱码问题-参数化-数据库操作-文件上传下载
jm解决乱码问题-参数化-数据库操作-文件上传下载 如果JM出果运行结果是乱码(解决中文BODY乱码的问题) 找到JM的安装路径,例如:C:\apache-jmeter-3.1\bin 用UE打开jm ...
- 配置允许匿名用户登录访问vsftpd服务,进行文档的上传下载、文档的新建删除等操作
centos7环境下 临时关闭防火墙 #systemctl stop firewalld 临时关闭selinux #setenforce 0 安装ftp服务 #yum install vsftpd - ...
- SFTP上传下载文件、文件夹常用操作
SFTP上传下载文件.文件夹常用操作 1.查看上传下载目录lpwd 2.改变上传和下载的目录(例如D盘):lcd d:/ 3.查看当前路径pwd 4.下载文件(例如我要将服务器上tomcat的日志文 ...
随机推荐
- C语言中的快速排序函数
C库中有自带的快排函数 qsort() ; 它的函数原型为: void qsort(void * , size_t ,size_t size , int (__cdecl *)(const void ...
- python实现队列(queue)
队列队列是一种先进先出的数据结构,主要操作包括入队,出队.入队的元素加入到对尾,从队头取出出队的元素.这里用列表简单模拟队列,其实现如下: queue()is_empty()size()enqueue ...
- IIS7和IIS8环境下 ThinkPHP专用URL Rewrite伪静态规则
这是适用于IIS7,IIS7.5,IIS8.0及以上的ThinkPHP的伪静态规则,把以下代码保存成web.config文件,放到FTP的web目录内即可. <?xml version=&q ...
- kubernetes从入门到放弃(二)
kubernetes对象之pod 1.pod的认识 Pod直译是豆荚,可以把容器想像成豆荚里的豆子,把一个或多个关系紧密的豆子包在一起就是豆荚(一个Pod).在Kubernetes中我们不会直接操作容 ...
- word2vec 构建中文词向量
词向量作为文本的基本结构——词的模型,以其优越的性能,受到自然语言处理领域研究人员的青睐.良好的词向量可以达到语义相近的词在词向量空间里聚集在一起,这对后续的文本分类,文本聚类等等操作提供了便利,本文 ...
- Python 文件和目录操作学习
文件与文件路径 文件有两个关键属性:文件名和路径. 路径指明了文件在计算机上的位置. 文件名中,最后一个句点之后的部分称为文件的"扩展名",它指出了文件的类型 目录也叫文件夹,文件 ...
- flask exception
flask exception 1.1. abort 概念:flask中的异常处理语句,功能类似于python中raise语句,只要触发abort,后面的代码不会执行,abort只能抛出符合ht ...
- C++查找指定路径下的特定类型的文件
转载:https://www.cnblogs.com/tinaluo/p/6824674.html 例子:找到C盘中所有后缀为exe的文件(不包括文件夹下的exe文件) #include<std ...
- 【PAT甲级】1015 Reversible Primes (20 分)
题意: 每次输入两个正整数N,D直到N是负数停止输入(N<1e5,1<D<=10),如果N是一个素数并且将N转化为D进制后逆转再转化为十进制后依然是个素数的话输出Yes,否则输出No ...
- Dynamic Programming(动态规划)
钢材分段问题 #include<iostream> #include<vector> using namespace std; class Solution { public: ...