sklearn中实现随机梯度下降法(多元线性回归)
sklearn中实现随机梯度下降法
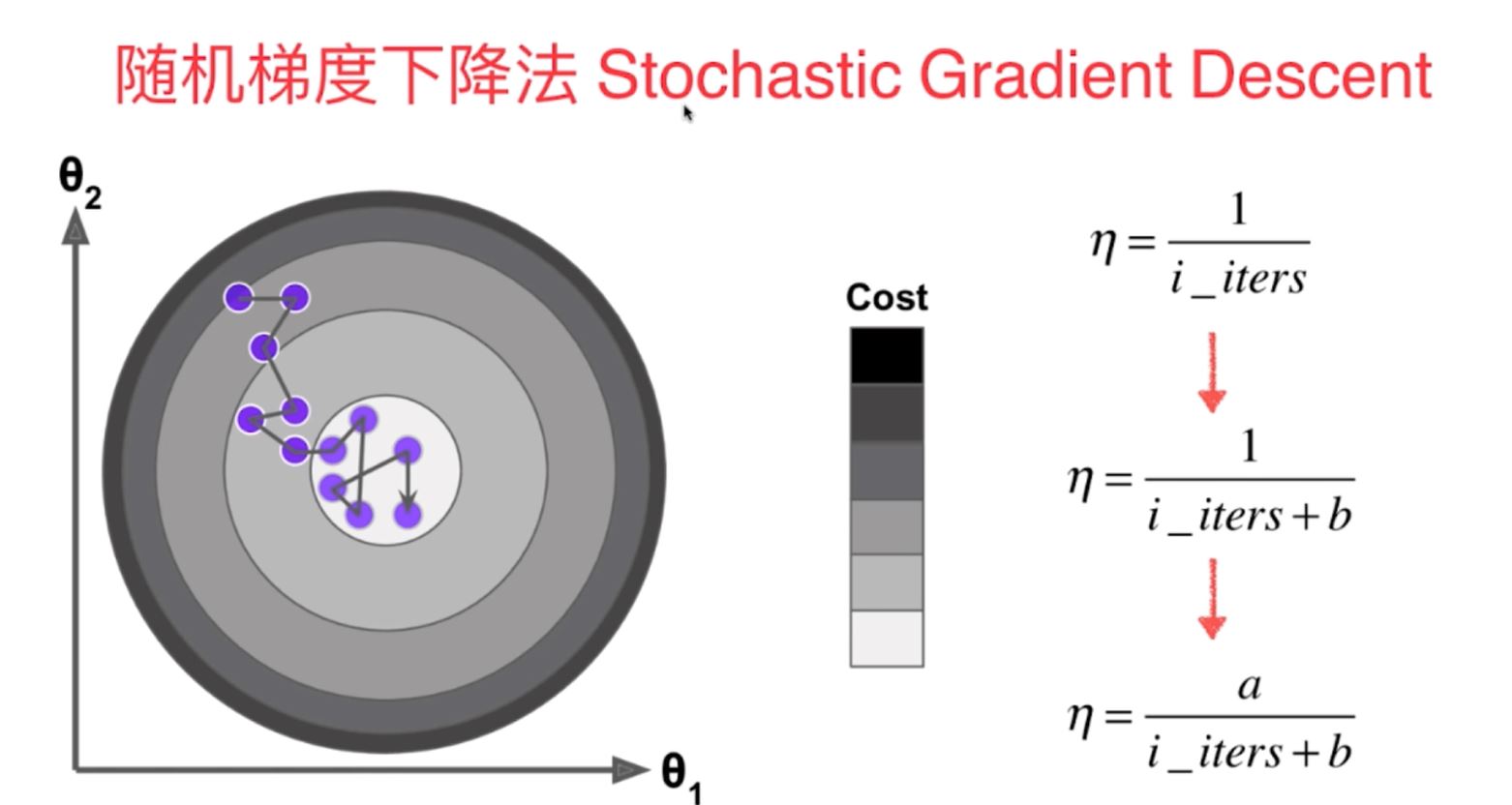
随机梯度下降法是一种根据模拟退火的原理对损失函数进行最小化的一种计算方式,在sklearn中主要用于多元线性回归算法中,是一种比较高效的最优化方法,其中的梯度下降系数(即学习率eta)随着遍历过程的进行在不断地减小。另外,在运用随机梯度下降法之前需要利用sklearn的StandardScaler将数据进行标准化。

#sklearn中实现随机梯度下降多元线性回归
#1-1导入相应的数据模块
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(666)
#1-2导入相应的基础训练数据集
x=np.random.random(size=1000)
y=x*3.0+4+np.random.normal(size=1000)
x=x.reshape(-1,1)
from sklearn import datasets
d=datasets.load_boston()
x=d.data[d.target<50]
y=d.target[d.target<50]
from sklearn.model_selection import train_test_split
x_train1,x_test1,y_train1,y_test1=train_test_split(x,y,random_state=1)
#1-3进行数据的标准化
from sklearn.preprocessing import StandardScaler
stand1=StandardScaler()
stand1.fit(x_train1)
x_train_standard=stand1.transform(x_train1)
x_test_standard=stand1.transform(x_test1)
#1-4导入随机梯度下降法的多元线性回归算法进行数据的训练和预测
from sklearn.linear_model import SGDRegressor
sgd1=SGDRegressor()
sgd1.fit(x_train_standard,y_train1)
print(sgd1.coef_)
print(sgd1.intercept_)
print(sgd1.score(x_test_standard,y_test1))
sgd2=SGDRegressor()
sgd2.fit(x_train1,y_train1)
print(sgd2.coef_)
print(sgd2.intercept_)
print(sgd2.score(x_test1,y_test1)) 注解:对于多元回归的随机梯度下降法需要对数据进行向量化和标准化
sklearn中实现随机梯度下降法(多元线性回归)的更多相关文章
- 机器学习---用python实现最小二乘线性回归算法并用随机梯度下降法求解 (Machine Learning Least Squares Linear Regression Application SGD)
在<机器学习---线性回归(Machine Learning Linear Regression)>一文中,我们主要介绍了最小二乘线性回归算法以及简单地介绍了梯度下降法.现在,让我们来实践 ...
- 线性回归(最小二乘法、批量梯度下降法、随机梯度下降法、局部加权线性回归) C++
We turn next to the task of finding a weight vector w which minimizes the chosen function E(w). Beca ...
- 一种利用 Cumulative Penalty 训练 L1 正则 Log-linear 模型的随机梯度下降法
Log-Linear 模型(也叫做最大熵模型)是 NLP 领域中使用最为广泛的模型之一,其训练常采用最大似然准则,且为防止过拟合,往往在目标函数中加入(可以产生稀疏性的) L1 正则.但对于这种带 L ...
- Gradient Descent 和 Stochastic Gradient Descent(随机梯度下降法)
Gradient Descent(Batch Gradient)也就是梯度下降法是一种常用的的寻找局域最小值的方法.其主要思想就是计算当前位置的梯度,取梯度反方向并结合合适步长使其向最小值移动.通过柯 ...
- 谷歌机器学习速成课程---降低损失 (Reducing Loss):随机梯度下降法
在梯度下降法中,批量指的是用于在单次迭代中计算梯度的样本总数.到目前为止,我们一直假定批量是指整个数据集.就 Google 的规模而言,数据集通常包含数十亿甚至数千亿个样本.此外,Google 数据集 ...
- 1. 批量梯度下降法BGD 2. 随机梯度下降法SGD 3. 小批量梯度下降法MBGD
排版也是醉了见原文:http://www.cnblogs.com/maybe2030/p/5089753.html 在应用机器学习算法时,我们通常采用梯度下降法来对采用的算法进行训练.其实,常用的梯度 ...
- 随机梯度下降法(Stochastic gradient descent, SGD)
BGD(Batch gradient descent)批量梯度下降法:每次迭代使用所有的样本(样本量小) Mold 一直在更新 SGD(Stochastic gradientdescent)随机 ...
- Stochastic Gradient Descent 随机梯度下降法-R实现
随机梯度下降法 [转载时请注明来源]:http://www.cnblogs.com/runner-ljt/ Ljt 作为一个初学者,水平有限,欢迎交流指正. 批量梯度下降法在权值更新前对所有样本汇总 ...
- sklearn中的随机森林
阅读了Python的sklearn包中随机森林的代码实现,做了一些笔记. sklearn中的随机森林是基于RandomForestClassifier类实现的,它的原型是 class RandomFo ...
随机推荐
- 通过python调用jenkins 常用api操作
# -*- coding: utf-8 -*- import jenkins class TestJenkins(object): def __new__(cls, *args, **kwargs): ...
- spring boot 整合mapreduce运行的ClassNotFoundException
问题 一个wordcount运行总是报错 java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.hadoop. ...
- 【PAT甲级】1047 Student List for Course (25 分)
题意: 输入两个正整数N和K(N<=40000,K<=2500),接下来输入N行,每行包括一个学生的名字和所选课程的门数,接着输入每门所选课程的序号.输出每门课程有多少学生选择并按字典序输 ...
- 洛谷P1009 阶乘之和 题解
想看原题请点击这里:传送门 看一下原题: 题目描述 用高精度计算出S=!+!+!+…+n! (n≤) 其中“!”表示阶乘,例如:!=****××××. 输入格式 一个正整数N. 输出格式 一个正整数S ...
- nyoj 11
水题... #include <stdio.h> #include <algorithm> #include <iostream> int main() { int ...
- Mysql基本用法-left join、right join、 inner join、子查询和join-02
left join #左连接又叫外连接 left join 返回左表中所有记录和右表中连接字段相等的记录 test_user表 phpcvs表 SQL: select * from test_use ...
- SpringBoot下配置Druid
什么是Druid:Druid是阿里发开的一套基于database的监控平台,相对于其他监控来说对于中文的支持更亲民.. 前言:最近这段时间发现项目整体运行响应速度较慢,打算对系统进行深层次的优化(尤其 ...
- 如何去掉Eclipse注释中英文单词的拼写错误检查
- 关于java自学的内容以及感受(7.21)
直接切入正题说一下自学到的内容: 定义合法标识符的规则: 可以由英文字母,数字,_,$组成. 不能数字开头和包含空格. 不可以使用关键字和保留字,但是可以包含关键字和保留字. byte short i ...
- 阿里云Centos7安装mysql5.7
下载mysql安装包 wget http://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm 安装mysql yum -y ...