redis(2)
目 录
1内容 3
2 redis集群简介 3
2.1 集群的概念 3
2.1.1 使用redis集群的必要性 3
2.1.2 如何学习redis集群 3
3 redis主从复制 4
3.1 概念 4
3.2 特点 4
3.3 基于配置实现 4
3.3.1 需求 4
3.3.2 配置步骤 5
3.3.3 测试 6
4 Sentinel哨兵模式 7
4.1 主从模式的缺陷 7
4.2 哨兵的任务 7
4.2.1 监控(Monitoring) 8
4.2.2 自动故障切换(Automatic failover) 8
4.3 哨兵模式部署 10
4.3.1 需求 10
4.3.2 配置Sentinel 10
4.3.3 测试 12
4.4 结论 12
4.5 注意事项 12
5 Redis-cluster集群 13
5.1 哨兵模式的缺陷 13
5.2 Redis-cluster集群概念 13
5.3 集群节点复制 13
5.4 故障转移 14
5.5 集群分片策略 14
5.6 集群redirect转向 15
5.7 集群搭建 15
5.7.1 准备工作 15
5.7.2 集群规划 16
5.7.3 启动每个结点redis服务 17
5.7.4 执行创建集群命令 17
5.7.5 查询集群信息 17
5.8 集群管理 18
5.8.1 添加主节点 18
5.8.2 添加从节点 20
5.8.3 删除结点: 21
6 java程序连接redis集群 22
6.1 连接步骤 22
6.1.1 第一步:创建项目,导入jar包 22
6.1.2 第二步:创建redis集群的客户端 22
6.2 注意事项: 23
6.3 测试 23
1内容
(1)Redis集群概述
(2)Redis主从复制
(3)Redis哨兵模型
(4)Redis-Cluster集群(重点)
2 redis集群简介
2.1 集群的概念
所谓的集群,就是通过添加服务器的数量,提供相同的服务,从而让服务器达到一个稳定、高效的状态。
2.1.1 使用redis集群的必要性
问题:我们已经部署好了redis,并且能启动一个redis,实现数据的读写,为什么还要学习redis集群?
答:(1)单个redis存在不稳定性。当redis服务宕机了,就没有可用的服务了。
(2)单个redis的读写能力是有限的。
总结:redis集群是为了强化redis的读写能力。
2.1.2 如何学习redis集群
--说明:(1)redis集群中,每一个redis称之为一个节点。
(2)redis集群中,有两种类型的节点:主节点(master)、从节点(slave)。
(3)redis集群,是基于redis主从复制实现。
所以,学习redis集群,就是从学习redis主从复制模型开始的。
3 redis主从复制
3.1 概念
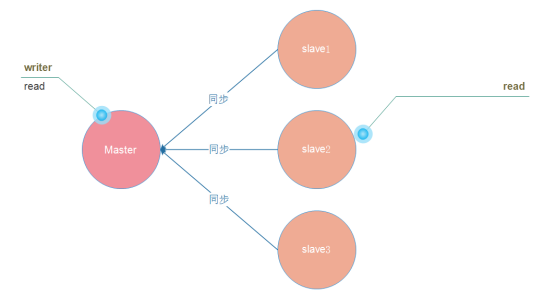
主从复制模型中,有多个redis节点。
其中,有且仅有一个为主节点Master。从节点Slave可以有多个。
只要网络连接正常,Master会一直将自己的数据更新同步给Slaves,保持主从同步。
3.2 特点
(1)主节点Master可读、可写.
(2)从节点Slave只读。(read-only)
因此,主从模型可以提高读的能力,在一定程度上缓解了写的能力。因为能写仍然只有Master节点一个,可以将读的操作全部移交到从节点上,变相提高了写能力。
3.3 基于配置实现
3.3.1 需求
|
主节点 |
6380 |
|
从节点(两个) |
6381、6382 |
3.3.2 配置步骤
(1)在/usr/local目录下,创建一个/redis/master-slave目录
|
[root@node0719 local]# mkdir -p redis/master-slave |
(2)在master-slave目录下,创建三个子目录6380、6381、6382
|
[root@node0719 master-slave]# mkdir 6380 6381 6382 |
(3)依次拷贝redis解压目录下的redis.conf配置文件,到这三个子目录中。
|
[root@node0719 master-slave]# cp /root/redis-3.2.9/redis.conf ./6380/ [root@node0719 master-slave]# cp /root/redis-3.2.9/redis.conf ./6381/ [root@node0719 master-slave]# cp /root/redis-3.2.9/redis.conf ./6382/ |
(4)进入6380目录,修改redis.conf,将port端口修改成6380即可。
|
[root@node0719 master-slave]# cd ./6380 [root@node0719 6380]# vim redis.conf
|

(5)进入6381目录,修改redis.conf,将port端口改成6381,同时指定开启主从复制。
|
[root@node0719 6380]# cd ../6381 [root@node0719 6381]# vim redis.conf
|


(6)进入6382目录,修改redis.conf,将port端口改成6382,同时指定开启主从复制。
|
[root@node0719 6380]# cd ../6382 [root@node0719 6381]# vim redis.conf
|


3.3.3 测试
(1)打开三个xshell窗口,在每一个窗口中,启动一个redis节点。查看日志输出。(不要改成后台模式启动,看不到日志,不直观)
|
[root@node0719 master-slave]# cd 6380 && redis-server ./redis.conf |
|
[root@node0719 master-slave]# cd 6381 && redis-server ./redis.conf |
|
[root@node0719 master-slave]# cd 6382 && redis-server ./redis.conf |
(2)另外再打开三个xshell窗口,在每一个窗口中,登陆一个redis节点
|
[root@node0719 ~]# redis-cli -p 6380 |
|
[root@node0719 ~]# redis-cli -p 6381 |
|
[root@node0719 ~]# redis-cli -p 6382 |
(3)在主节点6380上,进行读写操作,操作成功
|
[root@node0719 ~]# redis-cli -p 6380 127.0.0.1:6380> set user:name zs OK 127.0.0.1:6380> get user:name "zs" 127.0.0.1:6380> |
(4)在从节点6381上
读操作执行成功,并且成功从6380上同步了数据
|
[root@node0719 ~]# redis-cli -p 6381 127.0.0.1:6381> get user:name "zs" |
写操作执行失败。(从节点,只能读,不能写)
|
127.0.0.1:6381> set user:age 18 (error) READONLY You can't write against a read only slave. |
4 Sentinel哨兵模式
4.1 主从模式的缺陷
当主节点宕机了,整个集群就没有可写的节点了。
由于从节点上备份了主节点的所有数据,那在主节点宕机的情况下,如果能够将从节点变成一个主节点,是不是就可以解决这个问题了呢?
答:是的,这个就是Sentinel哨兵的作用。
4.2 哨兵的任务
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务:
监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常。
提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
自动故障迁移(Automatic failover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
4.2.1 监控(Monitoring)
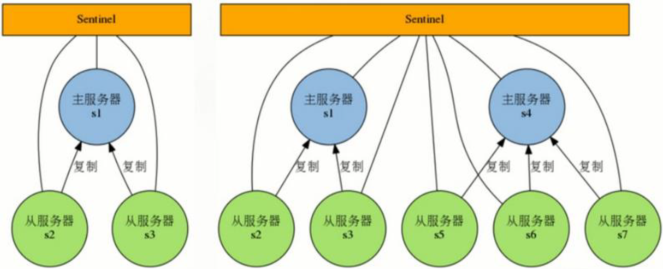
(1)Sentinel可以监控任意多个Master和该Master下的Slaves。(即多个主从模式)
(2)同一个哨兵下的、不同主从模型,彼此之间相互独立。
(3)Sentinel会不断检查Master和Slaves是否正常。
4.2.2 自动故障切换(Automatic failover)
4.2.2.1 Sentinel网络
监控同一个Master的Sentinel会自动连接,组成一个分布式的Sentinel网络,互相通信并交换彼此关于被监视服务器的信息。下图中,三个监控s1的Sentinel,自动组成Sentinel网络结构。
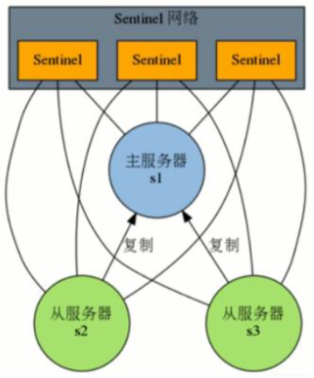
疑问:为什么要使用sentinel网络呢?
答:当只有一个sentinel的时候,如果这个sentinel挂掉了,那么就无法实现自动故障切换了。
在sentinel网络中,只要还有一个sentinel活着,就可以实现故障切换。
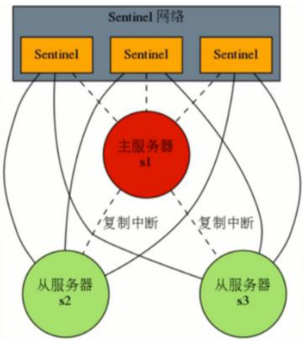
4.2.2.2 故障切换的过程
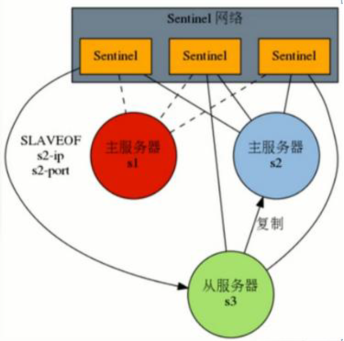
(1)投票(半数原则)
当任何一个Sentinel发现被监控的Master下线时,会通知其它的Sentinel开会,投票确定该Master是否下线(半数以上,所以sentinel通常配奇数个)。
(2)选举
当Sentinel确定Master下线后,会在所有的Slaves中,选举一个新的节点,升级成Master节点。
其它Slaves节点,转为该节点的从节点。
|
(1)投票 (2)选举 |
(3)原Master重新上线
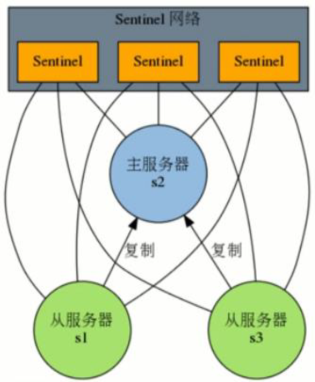
当原Master节点重新上线后,自动转为当前Master节点的从节点。
|
(3)原master重新上线 |
4.3 哨兵模式部署
4.3.1 需求
前提:已经存在一个正在运行的主从模式。
另外,配置三个Sentinel实例,监控同一个Master节点。
4.3.2 配置Sentinel
(1)在/usr/local目录下,创建/redis/sentinels/目录
|
[root@node0719 local]# mkdir -p redis/sentinels |
(2)在/sentinels目录下,以次创建s1、s2、s3三个子目录中
|
[root@node0719 sentinels]# mkdir s1 s2 s3 |
(3)依次拷贝redis解压目录下的sentinel.conf文件,到这三个子目录中
|
[root@node0719 sentinels]# cp /root/redis-3.2.9/sentinel.conf ./s1/ [root@node0719 sentinels]# cp /root/redis-3.2.9/sentinel.conf ./s2/ [root@node0719 sentinels]# cp /root/redis-3.2.9/sentinel.conf ./s3/ |
(4)依次修改s1、s2、s3子目录中的sentinel.conf文件,修改端口,并指定要监控的主节点。(从节点不需要指定,sentinel会自动识别)
S1哨兵配置如下:
|
|


S2哨兵配置如下:
|
|


S3哨兵配置如下:
|
|


(5)再打开三个xshell窗口,在每一个窗口中,启动一个哨兵实例,并观察日志输出
|
[root@node0719 sentinels]# redis-sentinel ./s1/sentinel.conf |
|
[root@node0719 sentinels]# redis-sentinel ./s2/sentinel.conf |
|
[root@node0719 sentinels]# redis-sentinel ./s3/sentinel.conf |
核心日志输出:
|
|

4.3.3 测试
(1)先关闭6380节点。发现,确实重新指定了一个主节点
|
|

(2)再次上线6380节点。发现,6380节点成为了新的主节点的从节点。
|
|

4.4 结论
Sentinel哨兵模式,确实能实现自动故障切换。提供稳定的服务。
4.5 注意事项
如果哨兵和redis节点不在同一台服务器上,注意IP绑定的问题。
(1)主从模型,所有的节点,使用ip绑定
|
|

(2)所有的哨兵,也都使用ip去绑定主机
|
|

(3)所有的哨兵,都是通过主节点的ip,去监控主从模型
|
|

5 Redis-cluster集群
5.1 哨兵模式的缺陷
在哨兵模式中,仍然只有一个Master节点。当并发写请求较大时,哨兵模式并不能缓解写压力。
我们知道只有主节点才具有写能力,那如果在一个集群中,能够配置多个主节点,是不是就可以缓解写压力了呢?
答:是的。这个就是redis-cluster集群模式。
5.2 Redis-cluster集群概念
(1)由多个Redis服务器组成的分布式网络服务集群;
(2)集群之中有多个Master主节点,每一个主节点都可读可写;
(3)节点之间会互相通信,两两相连;
(4)Redis集群无中心节点。
|
|

5.3 集群节点复制
|
|
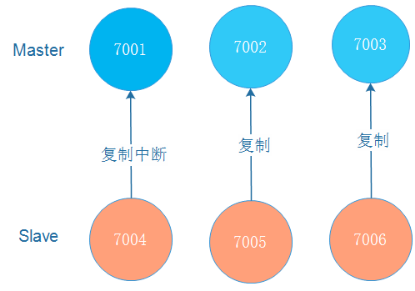
在Redis-Cluster集群中,可以给每一个主节点添加从节点,主节点和从节点直接遵循主从模型的特性。
当用户需要处理更多读请求的时候,添加从节点可以扩展系统的读性能。
5.4 故障转移
Redis集群的主节点内置了类似Redis Sentinel的节点故障检测和自动故障转移功能,当集群中的某个主节点下线时,集群中的其他在线主节点会注意到这一点,并对已下线的主节点进行故障转移。
|
|

集群进行故障转移的方法和Redis Sentinel进行故障转移的方法基本一样,不同的是,在集群里面,故障转移是由集群中其他在线的主节点负责进行的,所以集群不必另外使用Redis Sentinel。
5.5 集群分片策略
Redis-cluster分片策略,是用来解决key存储位置的。
集群将整个数据库分为16384个槽位slot,所有key-value数据都存储在这些slot中的某一个上。一个slot槽位可以存放多个数据,key的槽位计算公式为:slot_number=crc16(key)%16384,其中crc16为16位的循环冗余校验和函数。
集群中的每个主节点都可以处理0个至16383个槽,当16384个槽都有某个节点在负责处理时,集群进入上线状态,并开始处理客户端发送的数据命令请求。
|
|

5.6 集群redirect转向
由于Redis集群无中心节点,请求会随机发给任意主节点;
主节点只会处理自己负责槽位的命令请求,其它槽位的命令请求,该主节点会返回客户端一个转向错误;
客户端根据错误中包含的地址和端口重新向正确的负责的主节点发起命令请求。
|
|

5.7 集群搭建
5.7.1 准备工作
(1)安装ruby环境
redis集群管理工具redis-trib.rb依赖ruby环境,首先需要安装ruby环境:
|
yum -y install ruby yum -y install rubygems |
(2)安装ruby和redis的接口程序
拷贝redis-3.0.0.gem至/usr/local下,执行安装:
|
gem install /usr/local/redis-3.0.0.gem |
5.7.2 集群规划
(1)Redis集群最少需要6个节点,可以分布在一台或者多台主机上。
本教案在一台主机上创建伪分布式集群,不同的端口表示不同的redis节点,如下:
主节点:192.168.56.3:7001 192.168.56.3:7002 192.168.56.3:7003
从节点:192.168.56.3:7004 192.168.56.3:7005 192.168.56.3:7006
(2)在/usr/local/redis下创建redis-cluster目录,其下创建7001、7002。。7006目录,如下:
|
|
(3)将redis解压路径下的配置文件redis.conf,依次拷贝到每个700X目录内,并修改每个700X目录下的redis.conf配置文件:
|
必选配置: port 700X bind 192.168.23.3 cluster-enabled yes 建议配置: daemonized yes logfile /usr/local/redis/redis-cluster/700X/node.log |
5.7.3 启动每个结点redis服务
依次以700X下的redis.conf,启动redis节点。(必须指定redis.conf文件)
|
redis-server /usr/local/redis/redis-cluster/700X/redis.conf |
5.7.4 执行创建集群命令
进入到redis源码存放目录redis/redis-4.10.3/src下,执行redis-trib.rb,此脚本是ruby脚本,它依赖ruby环境。
|
./redis-trib.rb create --replicas 1 192.168.159.10:7001 192.168.159.10:7002 192.168.159.10:7003 192.168.159.10:7004 192.168.159.10:7005 192.168.159.10:7006 |
创建过程如下:
|
|

5.7.5 查询集群信息
集群创建成功登陆任意redis结点查询集群中的节点情况。
./redis-cli -c -h 192.168.56.3 -p 7001
|
|

说明:./redis-cli -c -h 192.168.56.3 -p 7001 ,其中:
|
-c表示以集群方式连接redis, -h指定ip地址, -p指定端口号
cluster nodes 查询集群结点信息; cluster info 查询集群状态信。 |
5.8 集群管理
5.8.1 添加主节点
5.8.1.1 节点规划
集群创建成功后可以向集群中添加节点,下面是添加一个master主节点
添加7007节点,参考集群结点规划章节添加一个“7007”目录作为新节点。
添加节点,执行下边命令:
./redis-trib.rb add-node 192.168.23.3:7007 192.168.23.3:7001
|
|
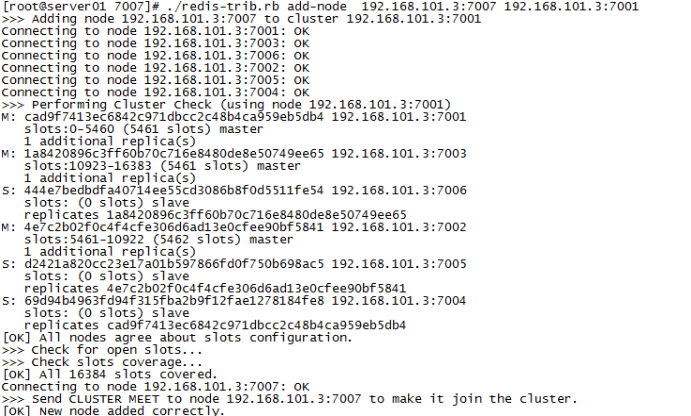
查看集群结点发现7007已添加到集群中:
|
|

5.8.1.2 hash槽重新分配
添加完新的主节点后,需要对主节点进行hash槽分配,这样该主节才可以存储数据。
redis集群有16384个槽,被所有的主节点共同分配,通过查看集群结点可以看到槽占用情况。
|
|

给刚添加的7007结点分配槽:
第一步:连接上集群
|
./redis-trib.rb reshard 192.168.23.3:7001(连接集群中任意一个可用节点都行) |
第二步:输入要分配的槽数量
|
|
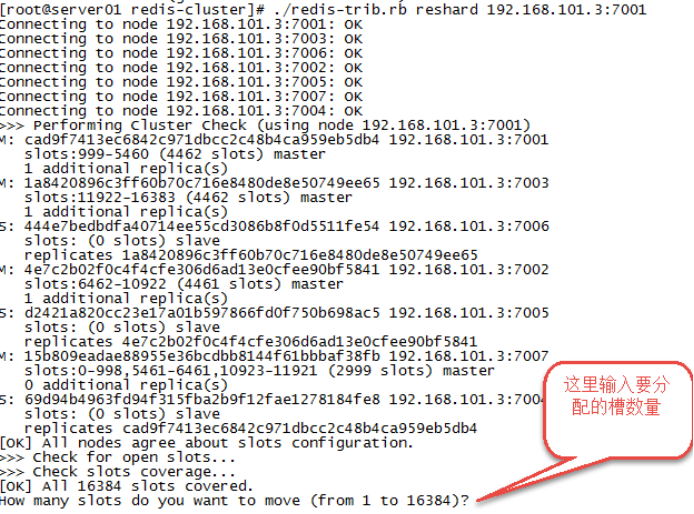
输入 500表示要分配500个槽
第三步:输入接收槽的结点id
|
|
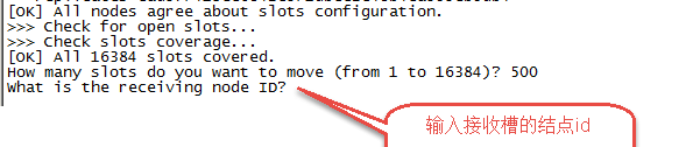
这里准备给7007分配槽,通过cluster nodes查看7007结点id为79bbb30bba66b4997b9360dd09849c67d2d02bb9
输入:79bbb30bba66b4997b9360dd09849c67d2d02bb9
第四步:输入源结点id
|
|
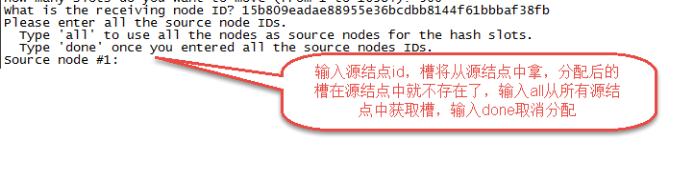
这里输入all,表示从其它主节点中分配。
第五步:输入yes开始移动槽到目标结点id
|
|

5.8.2 添加从节点
集群创建成功后可以向集群中添加节点,下面是添加一个slave从节点。
添加7008从结点,将7008作为7007的从结点。
新增从节点命令格式:
|
./redis-trib.rb add-node --slave --master-id masterID newNodIP:port MasterIP:port
masterID 主节点id,从cluster nodes信息中查看 newNodIP:port 新增节点的ip:端口 MasterIP:port 主节点的ip:端口 |
执行如下命令:
|
./redis-trib.rb add-node --slave --master-id 909c349f5f2d4db015101fb7c4e3c227a74ad382 192.168.4.253:7008 192.168.4.253:7007 |
79bbb30bba66b4997b9360dd09849c67d2d02bb9 是7007结点的id,可通过cluster nodes查看。
|
|

注意:
如果原来该结点在集群中的配置信息已经生成cluster-config-file指定的配置文件中(如果cluster-config-file没有指定则默认为nodes.conf),这时可能会报错:
|
[ERR] Node XXXXXX is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0 |
解决方法:
删除生成的配置文件nodes.conf,删除后再执行./redis-trib.rb add-node指令。
查看集群中的结点,刚添加的7008为7007的从节点:
|
|

5.8.3 删除结点:
删除节点命令格式:
|
./redis-trib.rb del-node nodeIP:port nodeID nodeIP:port 待删除节点的ip:端口 nodeID 待删除节点的id,从cluster node中查看 |
注意,删除已经占有hash槽的结点会失败,报错如下:
|
[ERR] Node 127.0.0.1:7005 is not empty! Reshard data away and try again. |
需要将该结点占用的hash槽分配出去(参考hash槽重新分配章节)。
6 java程序连接redis集群
6.1 连接步骤
6.1.1 第一步:创建项目,导入jar包
|
|
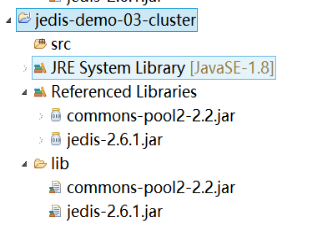
6.1.2 第二步:创建redis集群的客户端
|
package cn.gzsxt.jedis.test; import java.util.HashSet; import java.util.Set; import redis.clients.jedis.HostAndPort; import redis.clients.jedis.JedisCluster; public class TestJedisCluster { public static void main(String[] args) { //1、创建jedidsCluster客户端 //创建一个set集合,用来封装所有redis节点的信息 Set<HostAndPort> nodes = new HashSet<>(); nodes.add(new HostAndPort("192.168.23.12", 7001)); nodes.add(new HostAndPort("192.168.23.12", 7002)); nodes.add(new HostAndPort("192.168.23.12", 7003)); nodes.add(new HostAndPort("192.168.23.12", 7004)); nodes.add(new HostAndPort("192.168.23.12", 7005)); nodes.add(new HostAndPort("192.168.23.12", 7006)); nodes.add(new HostAndPort("192.168.23.12", 7007)); nodes.add(new HostAndPort("192.168.23.12", 7008)); JedisCluster cluster = new JedisCluster(nodes); String name = cluster.get("user:id:1:name"); cluster.set("user:id:1:address", "广东省广州市广州尚学堂"); String address = cluster.get("user:id:1:address"); System.out.println("name:"+name); System.out.println("address:"+address); if(null!=cluster){ cluster.close(); } } } |
6.2 注意事项:
连接Redis集群时,需要修改防火墙,开方每一个redis节点的端口。
说明:如果要开发一个范围的端口,可以使用冒号来分割,即: 7001:7008,表示开发7001-7008之间所有的端口
|
|

6.3 测试
|
|

访问Redis-cluster集群成功!!!
redis(2)的更多相关文章
- redis(二)高级用法
redis(二)高级用法 事务 redis的事务是一组命令的集合.事务同命令一样都是redis的最小执行单元,一个事务中的命令要么执行要么都不执行. 首先需要multi命令来开始事务,用exec命令来 ...
- redis(一) 安装以及基本数据类型操作
redis(一) 安装以及基本数据类型操作 redis安装和使用 redis安装 wget http://download.redis.io/redis-stable.tar.gz tar zxvf ...
- 深入学习Redis(1):Redis内存模型
前言 Redis是目前最火爆的内存数据库之一,通过在内存中读写数据,大大提高了读写速度,可以说Redis是实现网站高并发不可或缺的一部分. 我们使用Redis时,会接触Redis的5种对象类型(字符串 ...
- 深入学习Redis(5):集群
前言 在前面的文章中,已经介绍了Redis的几种高可用技术:持久化.主从复制和哨兵,但这些方案仍有不足,其中最主要的问题是存储能力受单机限制,以及无法实现写操作的负载均衡. Redis集群解决了上述问 ...
- 深入学习Redis(4):哨兵
前言 在 深入学习Redis(3):主从复制 中曾提到,Redis主从复制的作用有数据热备.负载均衡.故障恢复等:但主从复制存在的一个问题是故障恢复无法自动化.本文将要介绍的哨兵,它基于Redis主从 ...
- 深入学习Redis(3):主从复制
前言 在前面的两篇文章中,分别介绍了Redis的内存模型和Redis的持久化. 在Redis的持久化中曾提到,Redis高可用的方案包括持久化.主从复制(及读写分离).哨兵和集群.其中持久化侧重解决的 ...
- 深入学习Redis(2):持久化
前言 在上一篇文章中,介绍了Redis的内存模型,从这篇文章开始,将依次介绍Redis高可用相关的知识——持久化.复制(及读写分离).哨兵.以及集群. 本文将先说明上述几种技术分别解决了Redis高可 ...
- .Net使用Redis详解之ServiceStack.Redis(七) 转载https://www.cnblogs.com/knowledgesea/p/5032101.html
.Net使用Redis详解之ServiceStack.Redis(七) 序言 本篇从.Net如何接入Reis开始,直至.Net对Redis的各种操作,为了方便学习与做为文档的查看,我做一遍注释展现 ...
- 细说Redis(二)之 Redis的持久化
前言 在上一篇文章[细说Redis(一)之 Redis的数据结构与应用场景]中,主要介绍了Reids的数据结构. 对于redis的执行命令,这里不做介绍,因为网上搜索一堆,无必要再做介绍. AOF&a ...
- 构建高性能数据库缓存之redis(二)
一.概述 在构建高性能数据库缓存之redis(一)这篇文档中,阐述了Redis数据库(key/value)的特点.功能以及简单的配置过程,相信阅读过这篇文档的朋友,对Redis数据库会有一点的了解,此 ...
随机推荐
- M3U8地址在谷歌浏览器中播放
该案例git码云地址:https://gitee.com/kawhileonardfans/hls-player-example 1.下载插件 插件地址:https://files.cnblogs.c ...
- redis3.2.2 集群
http://blog.csdn.net/imxiangzi/article/details/52431729 http://www.2cto.com/kf/201701/586689.html me ...
- 三、ReactJS、jsx、 Component 特性
reactjs特性: 基于组件(Component)化思考 用 JSX 进行声明式(Declarative)UI 设计 使用 Virtual DOM Component PropType 错误校对机制 ...
- 前端第一篇---前端基础之HTML内容
前端基础之HTML内容 阅读目录(Content) 一.HTML初识 1.web服务本质 2.HTML是什么 3.HTML不是什么 二.HTML文档结构 三.HTML标签格式 四.HTML注释 五.H ...
- POJ 3627:Bookshelf
Bookshelf Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 7758 Accepted: 3906 Descrip ...
- TX2开发板Ubuntu16.04安装中文输入法
打开终端输入安装输入法: sudo apt-get install fcitx fcitx-googlepinyin fcitx-module-cloudpinyin fcitx-sunpinyin ...
- springboot + shiro+登录 微信登录 次数验证资料
分享一个朋友的人工智能教程.零基础!通俗易懂!风趣幽默!大家可以看看是否对自己有帮助,点击查看教程. 1.https://blog.csdn.net/xtiawxf/article/details/5 ...
- 百度地图API提供Geocoder类进行地址解析
根据地址描述获得坐标百度地图API提供Geocoder类进行地址解析,您可以通过Geocoder.getPoint()方法来将一段地址描述转换为一个坐标. // 创建地址解析器实例var myGeo ...
- springboot (2.0以上)连接mysql配置
pom <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java&l ...
- Swift—UITextField的基本用法
https://www.jianshu.com/p/63bdeca39ddf 1.文本输入框的创建##### let textField = UITextField(frame: CGRect(x:1 ...