编程作业2.1:Logistic regression
题目
在这部分的练习中,你将建立一个逻辑回归模型来预测一个学生是否能进入大学。假设你是一所大学的行政管理人员,你想根据两门考试的结果,来决定每个申请人是否被录取。你有以前申请人的历史数据,可以将其用作逻辑回归训练集。对于每一个训练样本,你有申请人两次测评的分数以及录取的结果。为了完成这个预测任务,我们准备构建一个可以基于两次测试评分来评估录取可能性的分类模型。
编程实现
1.Visualizing the data
在开始实现任何学习算法之前,如果可能的话,最好将数据可视化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('D:\BaiduNetdiskDownload\data_sets\ex2data1.txt', names=['exam1', 'exam2', 'admitted'])
data.head()
# 把数据分成 positive 和 negetive 两类
positive = data[data.admitted.isin(['1'])] # admitted=1 为 positive 类
negetive = data[data.admitted.isin(['0'])] # admitted=0 为 negetive 类
fig, ax = plt.subplots(figsize=(8,7))
ax.scatter(positive['exam1'], positive['exam2'], c='b', label='Admitted')
ax.scatter(negetive['exam1'], negetive['exam2'], s=50, c='r', marker='x', label='Not Admitted') # s 设置点的大小;marker 设置画图的形状
#设置图例在右上角
# ax.legend(loc=1)
# 设置图例显示在图的上方
box = ax.get_position()
ax.set_position([box.x0, box.y0, box.width , box.height* 0.8])
ax.legend(loc='center left', bbox_to_anchor=(0.2, 1.12),ncol=3)
# 设置横纵坐标名
ax.set_xlabel('Exam 1 Score')
ax.set_ylabel('Exam 2 Score')
plt.show()
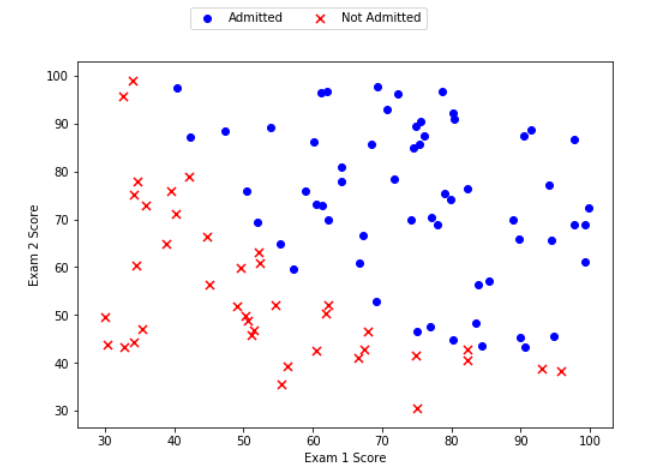
可以看到在两类间,有一个清晰的决策边界。现在我们需要实现逻辑回归,那样就可以训练一个模型来预测结果。
2.Sigmoid function
首先来回顾下 logistic 回归的假设函数:
\]
令 \(\theta^T x = z\),其中,\(g(z)\) 被称为 Sigmoid function (S型函数)或 Logistic function:
\]
def sigmoid(z):
return 1 / (1 + np.exp(- z))
x1 = np.arange(-10, 10, 0.1)
plt.plot(x1, sigmoid(x1), c='r')
plt.show()
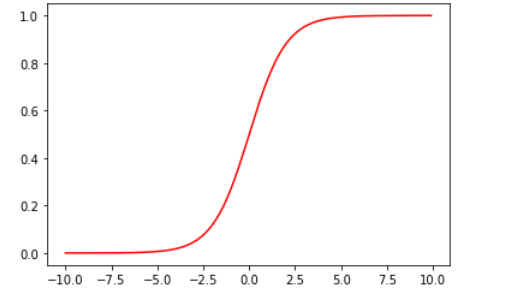
3.Cost function
逻辑回归的代价函数如下:
\]
\]
# 定义代价函数(能够返回代价函数值)
def cost(theta, X, y):
first = (-y) * np.log(sigmoid(X @ theta)) # 注意这里的 theta 是列向量
second = (1 - y)*np.log(1 - sigmoid(X @ theta))
return np.mean(first - second)
# add a ones column - this makes the matrix multiplication work out easier
if 'Ones' not in data.columns:
data.insert(0, 'Ones', 1)
# set X (training data) and y (target variable)
# 用.iloc来取列
X = data.iloc[:, :-1].values # Convert the frame to its Numpy-array representation.
y = data.iloc[:, -1].values # Return is NOT a Numpy-matrix, rather, a Numpy-array.
theta = np.zeros(X.shape[1]) # X.shape[1]获取X的列数,这里theta是列向量
检查矩阵的维度:
X.shape, theta.shape, y.shape
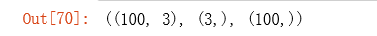
计算代价函数的初始值:
cost(theta, X, y)

接下来,我们需要一个函数来计算我们的训练数据、标签和一些参数thate的梯度。
4.Gradient
计算梯度值:
\]
转化为向量化计算:
\]
在此题中 ,\(X\) 是100*3的矩阵, \(X^T\) 就是3*100的矩阵。\(\theta\) 是3*1的矩阵,则最后求得的梯度值是一个3*1的矩阵。
# 定义计算梯度值(导数值)
def gradient(theta, X, y):
return (X.T @ (sigmoid(X @ theta) - y))/len(X)
# the gradient of the cost is a vector of the same length as θ where the jth element (for j = 0, 1, . . . , n)
计算梯度值的初始数据:
gradient(theta, X, y)
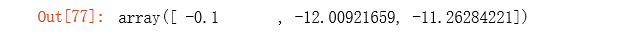
注意,我们还没有在执行梯度下降算法,这里仅仅在计算梯度值。
5.Learning θ parameters
- 在视频中,一个称为“fminunc”的Octave函数是用来优化函数来计算成本和梯度参数。
- 由于我们使用Python,我们可以用SciPy的“optimize”命名空间来做同样的事情。
这里我们使用的是高级优化算法,运行速度通常远远超过梯度下降。方便快捷。
只需传入cost函数,已经所求的变量theta,和梯度。注意:cost函数定义变量时变量theta要放在第一个,若cost函数只返回cost,则设置fprime=gradient。
import scipy.optimize as opt
# 这里使用fimin_tnc方法来拟合
result = opt.fmin_tnc(func=cost, x0=theta, fprime=gradient, args=(X, y))
result
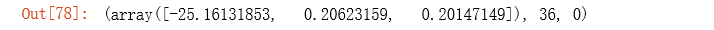
计算优化算法之后的代价值函数值:
cost(result[0], X, y)
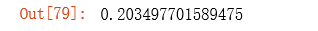
6.Evaluating logistic regression
- 学习好了参数\(θ\)后,我们来用这个模型预测某个学生是否能被录取。
- 接下来,我们需要编写一个函数,用我们所学的参数\(\theta\)来为数据集\(X\)输出预测。然后,我们可以使用这个函数来给我们的分类器的训练精度打分。
- 逻辑回归模型的假设函数:
\]
- 当\({h}_{\theta }\)大于等于0.5时,预测 y=1
- 当\({h}_{\theta }\)小于0.5时,预测 y=0
def predict(theta, X):
probability = sigmoid(X @ theta)
return [1 if x >= 0.5 else 0 for x in probability] # return a list
final_theta = result[0]
predictions = predict(final_theta, X)
correct = [1 if a==b else 0 for (a, b) in zip(predictions, y)]
accuracy = sum(correct) / len(X)
accuracy

可以看到预测精度达到了89%。
7.Decision boundary(决策边界)
决策边界:
\]
此题中决策边界为:
\]
x1 = np.arange(130, step=0.1)
x2 = -(final_theta[0] + x1*final_theta[1]) / final_theta[2]
fig, ax = plt.subplots(figsize=(8,5))
ax.scatter(positive['exam1'], positive['exam2'], c='b', label='Admitted')
ax.scatter(negetive['exam1'], negetive['exam2'], s=50, c='r', marker='x', label='Not Admitted')
ax.plot(x1, x2)
ax.set_xlim(0, 130)
ax.set_ylim(0, 130)
ax.set_xlabel('x1')
ax.set_ylabel('x2')
ax.set_title('Decision Boundary')
plt.show()

总结
逻辑回归的实现需要自己编写计算cost和gradient的函数,然后通过高级的优化算法就可以得到theta的最优解,不需要自己手动编写梯度下降函数。高级的优化算法不需要手动选择学习率α,收敛的速度远远快于梯度下降,但是要比梯度下降复杂。线性回归可以使用高级优化算法吗?明天试一下。
编程作业2.1:Logistic regression的更多相关文章
- Stanford coursera Andrew Ng 机器学习课程编程作业(Exercise 2)及总结
Exercise 1:Linear Regression---实现一个线性回归 关于如何实现一个线性回归,请参考:http://www.cnblogs.com/hapjin/p/6079012.htm ...
- Andrew Ng机器学习编程作业:Logistic Regression
编程作业文件: machine-learning-ex2 1. Logistic Regression (逻辑回归) 有之前学生的数据,建立逻辑回归模型预测,根据两次考试结果预测一个学生是否有资格被大 ...
- ufldl学习笔记与编程作业:Logistic Regression(逻辑回归)
ufldl学习笔记与编程作业:Logistic Regression(逻辑回归) ufldl出了新教程,感觉比之前的好,从基础讲起.系统清晰,又有编程实践. 在deep learning高质量群里面听 ...
- 编程作业2.2:Regularized Logistic regression
题目 在本部分的练习中,您将使用正则化的Logistic回归模型来预测一个制造工厂的微芯片是否通过质量保证(QA),在QA过程中,每个芯片都会经过各种测试来保证它可以正常运行.假设你是这个工厂的产品经 ...
- week3编程作业: Logistic Regression中一些难点的解读
%% ============ Part : Compute Cost and Gradient ============ % In this part of the exercise, you wi ...
- ufldl学习笔记和编程作业:Softmax Regression(softmax回报)
ufldl学习笔记与编程作业:Softmax Regression(softmax回归) ufldl出了新教程.感觉比之前的好,从基础讲起.系统清晰,又有编程实践. 在deep learning高质量 ...
- ufldl学习笔记与编程作业:Softmax Regression(vectorization加速)
ufldl学习笔记与编程作业:Softmax Regression(vectorization加速) ufldl出了新教程,感觉比之前的好.从基础讲起.系统清晰,又有编程实践. 在deep learn ...
- Andrew Ng机器学习编程作业: Linear Regression
编程作业有两个文件 1.machine-learning-live-scripts(此为脚本文件方便作业) 2.machine-learning-ex1(此为作业文件) 将这两个文件解压拖入matla ...
- ufldl学习笔记与编程作业:Linear Regression(线性回归)
ufldl学习笔记与编程作业:Linear Regression(线性回归) ufldl出了新教程,感觉比之前的好.从基础讲起.系统清晰,又有编程实践. 在deep learning高质量群里面听一些 ...
随机推荐
- 【转】R函数-diag()函数
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/lili_wuwu/article/det ...
- spring boot集成mybatis(1)
Spring Boot 集成教程 Spring Boot 介绍 Spring Boot 开发环境搭建(Eclipse) Spring Boot Hello World (restful接口)例子 sp ...
- JSP标签 <fmt:formatDate>格式化日期
<fmt:formatDate>标签用于使用不同的方式格式化日期. <%@ page language="java" contentType="text ...
- 业务全都在yun上能放心吗?
导读 组织将其业务在云上进行“全押”,这与扑克游戏中的这个激动人心时刻有着同样的吸引力.这种举动感觉很大胆,但却向外界传达了自己的信心,表明将会果断行动赢得比赛. 大多数银行对处理零售银行业务方式需要 ...
- (递归)P1192 台阶问题
题解: 这其实是变相的斐波那契,观察下列等式: //k=2 : 1 2 3 5 8 13 21 34...... //k=3 : 1 2 4 7 13 24 44 81... //k=4 : 1 2 ...
- Java底层魔术类Unsafe用法简述
1 引子 Java中没有指针,不能直接对内存地址的变量进行控制,但Java提供了一个特殊的类Unsafe工具类来间接实现.Unsafe主要提供一些用于执行低级别.不安全操作的方法,如直接访问系统内存资 ...
- @Autowired注解与@Resource注解的区别(详细)
相信对现在Java码农来说,@Autowired跟@Resource并不陌生,二者都可以自动注入,但是两者的区别很多时候并没有被注意到. 一.注解的出处 @Autowired是Spring提供的注解, ...
- 从结构和数字看OO——面向对象设计与构造第一章总结
不知不觉中,我已经接触OO五周了,顺利地完成了第一章节的学习,回顾三次编程作业,惊喜于自身在设计思路和编程习惯已有了一定的改变,下面我将从度量分析.自身Bug.互测和设计模式四个方向对自己第一章的学习 ...
- 设置MySQL客户端连接使用的字符集
设置MySQL客户端连接使用的字符集 时间:2014-03-05 来源:服务器之家 投稿:root 考虑什么是一个"连接":它是连接服务器时所作的事情.客户端发送SQL ...
- VUE- iView组件框架的使用
VUE- iView组件框架的使用 1. 下载iView 工程. 引用:https://www.iviewui.com/