sklearn.metrics中的评估方法介绍(accuracy_score, recall_score, roc_curve, roc_auc_score, confusion_matrix)
1 accuracy_score:分类准确率分数是指所有分类正确的百分比。分类准确率这一衡量分类器的标准比较容易理解,但是它不能告诉你响应值的潜在分布,并且它也不能告诉你分类器犯错的类型。常常误导初学者:呵呵。
sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数
import numpy as np
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
accuracy_score(y_true, y_pred)
#0.5 输出结果
accuracy_score(y_true, y_pred, normalize=False)
#2 输出结果
2 recall_score :召回率 =提取出的正确信息条数 /样本中的信息条数。通俗地说,就是所有准确的条目有多少被检索出来了。
klearn.metrics.recall_score(y_true, y_pred, labels=None, pos_label=1,average='binary', sample_weight=None)
将一个二分类matrics拓展到多分类或多标签问题时,我们可以将数据看成多个二分类问题的集合,每个类都是一个二分类。接着,我们可以通过跨多个分类计算每个二分类metrics得分的均值,这在一些情况下很有用。你可以使用average参数来指定。
参数average : string, [None, ‘micro’, ‘macro’(default), ‘samples’, ‘weighted’]
将一个二分类matrics拓展到多分类或多标签问题时,我们可以将数据看成多个二分类问题的集合,每个类都是一个二分类。接着,我们可以通过跨多个分类计算每个二分类metrics得分的均值,这在一些情况下很有用。你可以使用average参数来指定。
macro:计算二分类metrics的均值,为每个类给出相同权重的分值。当小类很重要时会出问题,因为该macro-averging方法是对性能的平均。另一方面,该方法假设所有分类都是一样重要的,因此macro-averaging方法会对小类的性能影响很大。
weighted:对于不均衡数量的类来说,计算二分类metrics的平均,通过在每个类的score上进行加权实现。
micro:给出了每个样本类以及它对整个metrics的贡献的pair(sample-weight),而非对整个类的metrics求和,它会每个类的metrics上的权重及因子进行求和,来计算整个份额。Micro-averaging方法在多标签(multilabel)问题中设置,包含多分类,此时,大类将被忽略。
samples:应用在multilabel问题上。它不会计算每个类,相反,它会在评估数据中,通过计算真实类和预测类的差异的metrics,来求平均(sample_weight-weighted)
average:average=None将返回一个数组,它包含了每个类的得分
3 roc_curve
ROC曲线指受试者工作特征曲线/接收器操作特性(receiver operating characteristic,ROC)曲线,是反映灵敏性和特效性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性。ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真正例率(也就是灵敏度)(True Positive Rate,TPR)为纵坐标,假正例率(1-特效性)(False Positive Rate,FPR)为横坐标绘制的曲线。
ROC观察模型正确地识别正例的比例与模型错误地把负例数据识别成正例的比例之间的权衡。TPR的增加以FPR的增加为代价。ROC曲线下的面积是模型准确率的度量,AUC(Area under roccurve)。
纵坐标:真正率(True Positive Rate , TPR)或灵敏度(sensitivity)
TPR = TP /(TP + FN) (正样本预测结果数 / 正样本实际数)
横坐标:假正率(False Positive Rate , FPR)
FPR = FP /(FP + TN) (被预测为正的负样本结果数 /负样本实际数)
>>>import numpy as np
>>>from sklearn import metrics
>>>y = np.array([1, 1, 2, 2])
>>>scores = np.array([0.1, 0.4, 0.35, 0.8])
>>>fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
>>>fpr
array([0. , 0.5, 0.5, 1. ])
>>>tpr
array([0.5, 0.5, 1. , 1. ])
>>>thresholds
array([0.8 , 0.4 , 0.35, 0.1 ])
>>>from sklearn.metrics import auc
>>>metrics.auc(fpr, tpr)
0.75
4 Auc :计算AUC值,其中x,y分别为数组形式,根据(xi,yi)在坐标上的点,生成的曲线,然后计算AUC值;
sklearn.metrics.auc(x, y, reorder=False)
5 roc_auc_score :
直接根据真实值(必须是二值)、预测值(可以是0/1,也可以是proba值)计算出auc值,中间过程的roc计算省略。
形式:
sklearn.metrics.roc_auc_score(y_true, y_score, average='macro', sample_weight=None)
average : string, [None, ‘micro’, ‘macro’(default), ‘samples’, ‘weighted’]
>>>import numpy as np
>>>from sklearn.metrics import roc_auc_score
>>>y_true = np.array([0, 0, 1, 1])
>>>y_scores = np.array([0.1, 0.4, 0.35, 0.8])
>>>roc_auc_score(y_true, y_scores)
0.75
6 confusion_matrix
假设有一个用来对猫(cats)、狗(dogs)、兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结。假设总共有 27 只动物:8只猫, 6条狗, 13只兔子。结果
的混淆
矩阵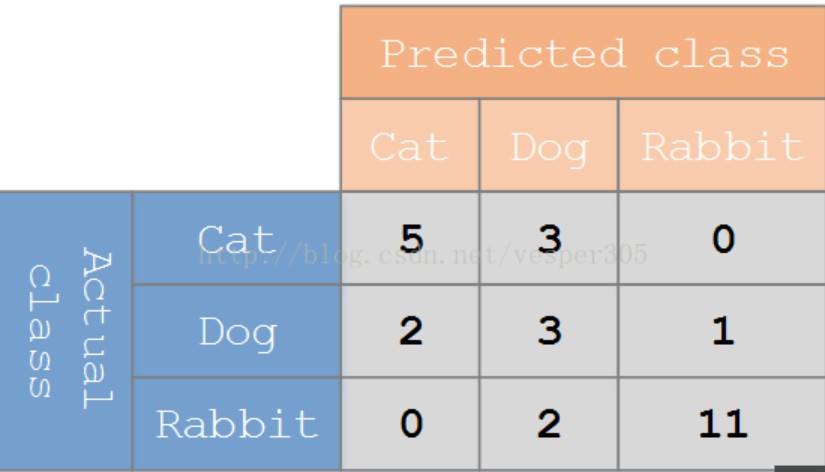
sklearn.metrics.confusion_matrix(y_true, y_pred, labels=None, sample_weight=None)
返回一个混淆矩阵;
labels:混淆矩阵的索引(如上面猫狗兔的示例),如果没有赋值,则按照y_true, y_pred中出现过的值排序。
>>>from sklearn.metrics import confusion_matrix
>>>y_true = [2, 0, 2, 2, 0, 1]
>>>y_pred = [0, 0, 2, 2, 0, 2]
>>>confusion_matrix(y_true, y_pred)
array([[2,0, 0],
[0, 0, 1],
[1, 0, 2]])
>>>y_true = ["cat", "ant", "cat", "cat","ant", "bird"]
>>>y_pred = ["ant", "ant", "cat", "cat","ant", "cat"]
>>>confusion_matrix(y_true, y_pred, labels=["ant", "bird","cat"])
array([[2,0, 0],
[0, 0, 1],
[1, 0, 2]])
其实翻译一下就是,给你一群人,比如100个,你用模型挑出来20个认为这20个可能患前列腺癌症,但是,过了几天,经过专业医生诊断,确诊,你这20个病人里面只有18个是真正预测对了,那你的准确率就是18/20=90%,但是发现你还漏了5个,你的召回率就是18/(18+5)=78%,而你的目的肯定是漏掉的越少越好,所以你要关注召回率,提高78%,越高越好,同时你的准确率也要看,比如你把100个人都预测为前列腺癌症,召回率肯定是23/23=100%,但是你的准确率就是23/100=23%,
sklearn.metrics中的评估方法介绍(accuracy_score, recall_score, roc_curve, roc_auc_score, confusion_matrix)的更多相关文章
- sklearn.metrics中的评估方法
https://www.cnblogs.com/mindy-snail/p/12445973.html 1.confusion_matrix 利用混淆矩阵进行评估 混淆矩阵说白了就是一张表格- 所有正 ...
- Python Sklearn.metrics 简介及应用示例
Python Sklearn.metrics 简介及应用示例 利用Python进行各种机器学习算法的实现时,经常会用到sklearn(scikit-learn)这个模块/库. 无论利用机器学习算法进行 ...
- sklearn.metrics.roc_curve
官方网址:http://scikit-learn.org/stable/modules/classes.html#module-sklearn.metrics 首先认识单词:metrics: ['mɛ ...
- Sklearn库例子1:Sklearn库中AdaBoost和Decision Tree运行结果的比较
DisCrete Versus Real AdaBoost 关于Discrete 和Real AdaBoost 可以参考博客:http://www.cnblogs.com/jcchen1987/p/4 ...
- JAVA Metrics 度量工具使用介绍1
Java Metric使用介绍1 Metrics是一个给JAVA提供度量工具的包,在JAVA代码中嵌入Metrics代码,可以方便的对业务代码的各个指标进行监控,同一时候,Metrics可以非常好的跟 ...
- 2.sklearn库中的标准数据集与基本功能
sklearn库中的标准数据集与基本功能 下面我们详细介绍几个有代表性的数据集: 当然同学们也可以用sklearn机器学习函数来挖掘这些数据,看看可不可以捕捉到一些有趣的想象或者是发现: 波士顿房价数 ...
- [sklearn]性能度量之AUC值(from sklearn.metrics import roc_auc_curve)
原创博文,转载请注明出处! 1.AUC AUC(Area Under ROC Curve),即ROC曲线下面积. 2.AUC意义 若学习器A的ROC曲线被学习器B的ROC曲线包围,则学习器B的性能优于 ...
- sklearn.metrics.roc_curve使用说明
roc曲线是机器学习中十分重要的一种学习器评估准则,在sklearn中有完整的实现,api函数为sklearn.metrics.roc_curve(params)函数. 官方接口说明:http://s ...
- AutoMapper之ABP项目中的使用介绍
最近在研究ABP项目,昨天写了Castle Windsor常用介绍以及其在ABP项目的应用介绍 欢迎各位拍砖,有关ABP的介绍请看阳光铭睿 博客 AutoMapper只要用来数据转换,在园里已经有很多 ...
随机推荐
- 云时代架构阅读笔记九——web应用存在的问题及解决办法
web应用通常存在的10大安全问题 1.SQL注入 拼接的SQL字符串改变了设计者原来的意图,执行了如泄露.改变数据等操作,甚至控制数据库服务器, SQL Injection与Command Inje ...
- 七十一、SAP中内表的修改,改一行数据,或一行的某个字段
一.SAP中内表的修改,只能通过工作区来修改,代码如下 二.效果如下
- ServletContext 详解
ServletContext——它是一个全局的储存信息的空间,服务器开始,其就存在,服务器关闭,其才释放.request,一个用户可有多个:session,一个用户一个:而servletContext ...
- .NET via C#笔记17——委托
一.委托的内部实现 C#中的委托是一种类型安全的回调函数,假设有这样一个委托: internal delegate void Feedback(int value); 编译器会生成一个类: inter ...
- 【转载】RobotFramework的Setup或Teardowm中执行多个关键字
有时候需要在setup和teardowm中执行多个关键字 以前的做法就是重新封装一个keyword,然后调用,It’s OK 这里介绍另外一个方法,使用Run Keywords来实现 用法其实非常的简 ...
- NSPredicate实现数据筛选
一:基本语法 1.什么是NSPredicate apple官方文档这样写的: The NSPredicate class is used to define logical conditions us ...
- java菜鸟第一天
- 字符输出、if判断
1.这里学习交互性输入 #input 接受的所有数据都是字符串,即使你输入的是数字,但依然会被当成字符串来处理 #type 用来查看变量存入到内存时的属性 #int 将变量强制转化为整型 #str ...
- 从零开始Windows环境下安装python+tensorflow
从零开始Windows环境下安装python+tensorflow 2017年07月12日 02:30:47 qq_16257817 阅读数:29173 标签: windowspython机器学习te ...
- java百货中心供应链管理系统 源码
开发环境: Windows操作系统开发工具:MyEclipse/Eclipse + JDK+ Tomcat + MySQL 数据库 百货中心供应链管理系统主要用于实现了企业管理数据统计等.本系统结构如 ...