第 11 篇:基于 drf-haystack 的文章搜索接口

在 django 博客教程中,我们使用了 django-haystack 和 Elasticsearch 进行文章内容的搜索。django-haystack 默认返回的搜索结果是一个类似于 django QuerySet 的对象,需要配合模板系统使用,因为未被序列化,所以无法直接用于 django-rest-framework 的接口。当然解决方案也很简单,编写相应的序列化器将返回结果序列化就可以了。
但是,通过之前的功能我们看到,使用 django-rest-framework 是一个近乎标准化但又枯燥无聊的过程:首先是编写序列化器用于序列化资源,然后是编写视图集,提供对资源各类操作的接口。既然是标准化的东西,肯定已经有人写好了相关的功能以供复用。此时就要发挥开源社区的力量,去 GitHub 使用关键词 rest haystack 搜索,果然搜到一个 drf-haystack 开源项目,专门用于解决 django-rest-framework 和 haystack 结合使用的问题。因此我们就不再重复造轮子,直接使用开源第三方库来实现我们的需求。
既然要使用第三方库,第一步当然是安装它,进入项目根目录,运行:
$ pipenv install drf-haystack
由于需要使用到搜索功能,因此需要启动 Elasticsearch 服务,最简单的方式就是使用项目中编排的 Elasticsearch 镜像启动容器。
项目根目录下运行如下命令启动全部项目所需的容器服务:
$ docker-compose -f local.yml up --build
启动完成后运行 docker ps 命令可以检查到如下 2 个运行的容器,说明启动成功:
hellodjango_rest_framework_tutorial_local
hellodjango_rest_framework_tutorial_elasticsearch_local
接着创建一些文章,以便用于搜索测试,可以自己在 admin 后台添加,当然最简单的方法是运行项目中的 fake.py 脚本,批量生成测试数据:
$ docker-compose -f local.yml run --rm hellodjango.rest.framework.tutorial.local python -m scripts.fake
测试文章生成后,还要运行下面的命令给文章的内容创建索引,这样搜索引擎才能根据索引搜索到相应的内容:
$ docker-compose -f local.yml run --rm hellodjango.rest.framework.tutorial.local python manage.py rebuild_index
# 输出如下
Your choices after this are to restore from backups or rebuild via the `rebuild_index` command.
Are you sure you wish to continue? [y/N] y
Removing all documents from your index because you said so.
All documents removed.
Indexing 201 文章
GET /hellodjango_blog_tutorial/_mapping [status:404 request:0.005s]
注意
如果生成索引时看到如下错误:
elasticsearch.exceptions.ConnectionError: ConnectionError(<urllib3.connection.HTTPConnection object at 0x7f25daa83c50>: Failed to establish a new connection:
[Errno -2] Name does not resolve) caused by: NewConnectionError(<urllib3.connection.HTTPConnection object at 0x7f25daa83c50>: Failed to establish a new connection: [Errno -2] Name does not resolve)这是由于项目配置中 Elasticsearch 服务的 URL 配置出错导致,解决方法是进入 settings/local.py 配置文件中,将搜索设置改为下面的内容:
HAYSTACK_CONNECTIONS['default']['URL'] = 'http://elasticsearch.local:9200/'
因为这个 URL 地址需和容器编排文件 local.yml 中指定的容器服务名一致 Docker 才能正确解析。
现在万事具备了,数据库中已经有了文章,搜索服务已经有了文章的索引,只需要等待客户端来进行查询,然后返回结果。所以接下来就进入到 django-rest-framework 标准开发流程:定义序列化器 -> 编写视图 -> 配置路由,这样一个标准的搜索接口就开发出来了。
先来定义序列化器,粗略过一遍 drf-haystack 官方文档,依葫芦画瓢创建文章(Post) 的 Serializer
blog/serializers.py
from drf_haystack.serializers import HaystackSerializerMixin
class PostHaystackSerializer(HaystackSerializerMixin, PostListSerializer):
class Meta(PostListSerializer.Meta):
search_fields = ["text"]
根据官方文档的介绍,为了复用已经定义好用于序列化文章列表的序列化器,我们直接继承了 PostListSerializer,同时我们还混入了 HaystackSerializerMixin,这是 drf-haystack 的混入类,提供搜索结果序列化相关的功能。
另外内部类 Meta 同样继承 PostListSerializer.Meta,这样就无需重复定义序列化字段列表 fields。关键的地方在这个 search_fields,这个列表声明用于搜索的字段(通常都定义为索引字段),我们在上一部教程设置 django-haystack 时,文章的索引字段设置的名字叫 text,如果对这一块有疑惑,可以简单回顾一下 Django Haystack 全文检索与关键词高亮 中的内容。
然后编写视图集,需继承 HaystackViewSet:
blog/views.py
from drf_haystack.viewsets import HaystackViewSet
from .serializers import PostHaystackSerializer
class PostSearchView(HaystackViewSet):
index_models = [Post]
serializer_class = PostHaystackSerializer
这个视图集非常简单,只需要通过类属性 index_models 声明需要搜索的模型,以及搜索结果的序列化器就行了,剩余的功能均由 HaystackViewSet 内部替我们实现了。
最后是在路由器中注册视图集,自动生成 URL 模式:
blogproject/urls.py
router = routers.DefaultRouter()
router.register(r"search", blog.views.PostSearchView, basename="search")
搞定了!一套标准化的 django-restful-framework 开发流程,不过大量工作已由 drf-haystack 在背后替我们完成,我们只写了非常少量的代码即实现了一套搜索接口。
来看看搜索效果。我们启动 Docker 容器,在浏览器输入如下格式的 URL:
http://127.0.0.1:8000/api/search/?text=key-word
将 key-word 替换为需要搜索的关键字,例如将其替换为 markdown,测试集数据中得到的搜索结果如下:
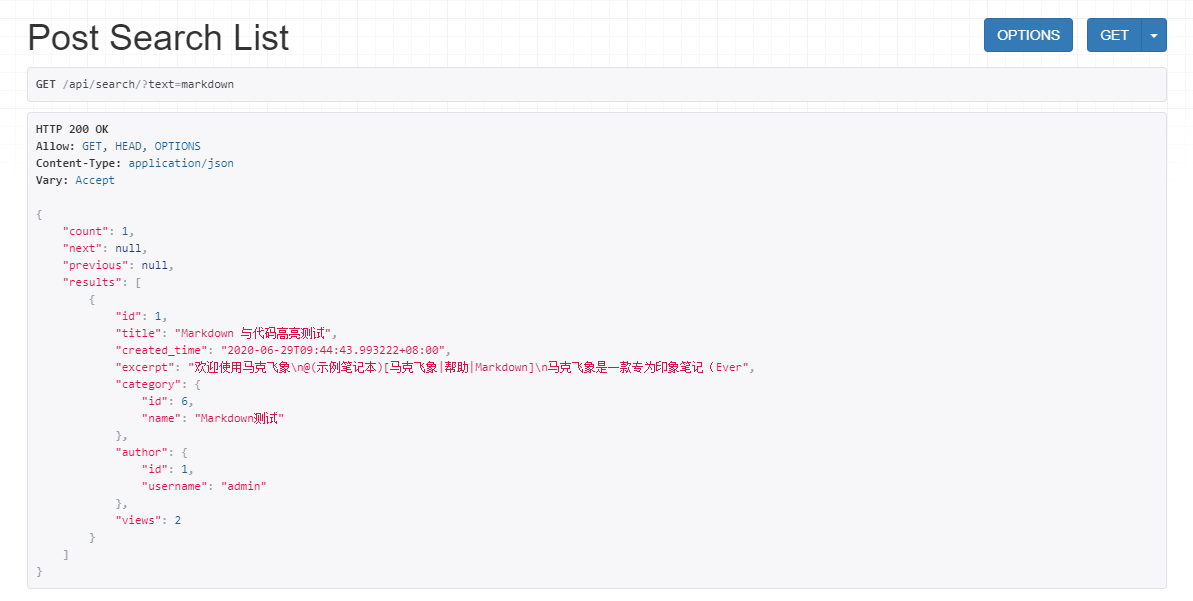
搜索结果符合预期,但略微有一点不太好的地方,就是没有高亮的标题和摘要,我们希望将来显示的结果应该是下面这样的,因此返回的数据必须支持这样的显示:

关键词高亮的实现原理其实非常简单,通过解析整段文本,将搜索关键词替换为由 HTML 标签包裹的富文本,并给这个包裹标签设置 CSS 样式,让其显示不同的字体颜色就可以了。
了解其原理后当然就是实现其功能,不过 django-haystack 已经为我们造好了轮子,而且在上一部教程的 Django Haystack 全文检索与关键词高亮,我们还对默认的高亮辅助类进行了改造,优化了文章标题被从关键字位置截断的问题,因此我们使用改造后的辅助类来对需要高亮的结果进行处理。
需要高亮的其实是 2 个字段,一个是 title、一个是 body。而 body 我们不需要完整的内容,只需要摘出其中一部分作为搜索结果的摘要即可。这两个功能,辅助类均已经为我们提供了,我们只需要调用所需的方法就行。
注意到这里我们需要对 title、body 两个字段进行高亮处理,其基本逻辑其实就是接收 title、body 的值作为输入,高亮处理后再输出。回顾一下序列化器的序列化字段,其实也是接收某个字段的值作为输入,对其进行处理,将其转化为可序列化的结果后输出,和我们需要的逻辑很像。但是,django-rest-framework 并没有提供这些比较个性化需求的序列化字段,因此接下来我们接触 drf 的一点高级用法——自定义序列化字段。
自定义序列化字段其实非常的简单,基本流程分两步走:
- 从 drf 官方提供的序列化字段中找一个数据类型最为接近的作为父类。
- 重写
to_representation方法,加入自己的序列化逻辑。
以我们的需求为例。因为 title、body 均为字符型,因此选择父类序列化字段为 CharField,定义一个 HighlightedCharField 字段如下:
from .utils import Highlighter
class HighlightedCharField(CharField):
def to_representation(self, value):
value = super().to_representation(value)
request = self.context["request"]
query = request.query_params["text"]
highlighter = Highlighter(query)
return highlighter.highlight(value)
django-rest-framework 通过调用序列化字段的 to_representation 方法对输入的值进行序列化,这个方法接收的第一个参数就是需要序列化的值。在我们自定义的逻辑中,首先调用父类 CharField 的 to_representation 方法,父类序列化的逻辑是将任何输入的值都转为字符串;接着我们从 context 属性中取得 request 对象,这个对象就是视图中的 HTTP 请求对象,但是因为 django 中 request 对象无法像 flask 那样从全局获取,因此 drf 在视图中将其保存在了序列化器和序列化字段的 context 属性中以便在视图外访问;获取 request 对象的目的是希望获取查询的关键字,query_params 属性是一个类字典对象,用于记录来自 URL 的查询参数,例如我们之前测试查询功能时调用的 URL 为 /api/search/?text=markdown,所以 query_params 保存了 URL 中的查询参数,将其封装为一个类字段对象 {"text": "markdown"},这里 text 的值就是查询的关键字,我们将它传给 Highlighter 辅助类,然后调用 highlight 方法将需要序列化的值进行进一步的高亮处理。
序列化字段定义好后,我们就可以在序列化器中用它了:
class PostHaystackSerializer(HaystackSerializerMixin, PostListSerializer):
title = HighlightedCharField()
summary = HighlightedCharField(source="body")
class Meta(PostListSerializer.Meta):
search_fields = ["text"]
fields = [
"id",
"title",
"summary",
"created_time",
"excerpt",
"category",
"author",
"views",
]
title 字段原本使用默认的 CharField 进行序列化,这里我们重新指定为自定义的 HighlightedCharField,这样序列化后的值就是高亮的格式。
summary 是我们新增的字段,注意我们序列化的对象是文章 Post,但这个对象是没有 summary 这个属性的,但是 summary 其实是对属性 body 序列化后的结果,因此我们通过指定序列化化字段的 source 参数,指定值的来源。
最后别忘了在 fields 中申明全部序列化的字段,主要是把新增的 summary 加进去。
来看看改进后的搜索效果:
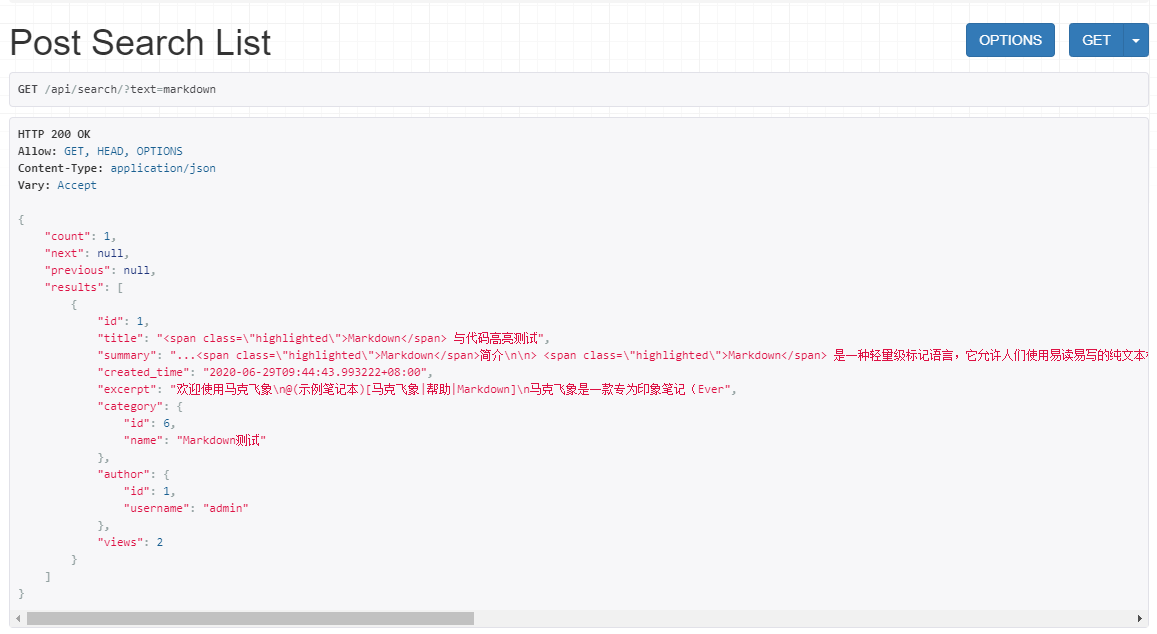
注意观察返回的 title 和 summary,我们搜索的关键词是 markdown,可以看到所有 markdown 关键字都被包裹了一个 span 标签,并且设置了 class 属性为 highlighted,只要设置好 css 样式,页面所有的 markdown 关键词就会显示不同的颜色,从而实现搜索关键词高亮的效果了。
当然,我们现在并没有实际用到这个特性,下一部教程我们将使用 Vue 来开发博客,到时候调用搜索接口拿到搜索结果后就会实际用到了。

关注公众号加入交流群
第 11 篇:基于 drf-haystack 的文章搜索接口的更多相关文章
- iOS冰与火之歌(番外篇) - 基于PEGASUS(Trident三叉戟)的OS X 10.11.6本地提权
iOS冰与火之歌(番外篇) 基于PEGASUS(Trident三叉戟)的OS X 10.11.6本地提权 蒸米@阿里移动安全 0x00 序 这段时间最火的漏洞当属阿联酋的人权活动人士被apt攻击所使用 ...
- 回顾2017系列篇(一):最佳的11篇UI/UX设计文章
2017已经接近尾声,在这一年中,设计领域发生了诸多变化.也是时候对2017年做一个总结,本文主要是从2017设计文章入手,列出了个人认为2017设计行业里最重要的UI/UX文章的前11名,供大家参考 ...
- 【文智背后的奥秘】系列篇——基于CRF的人名识别
版权声明:本文由文智原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/133 来源:腾云阁 https://www.qclou ...
- SpringMVC(12)完结篇 基于Hibernate+Spring+Spring MVC+Bootstrap的管理系统实现
到这里已经写到第12篇了,前11篇基本上把Spring MVC主要的内容都讲了,现在就直接上一个项目吧,希望能对有需要的朋友有一些帮助. 一.首先看一下项目结构: InfrastructureProj ...
- 前两篇转载别人的精彩文章,自己也总结一下python split的用法吧!
前言:前两篇转载别人的精彩文章,自己也总结一下吧! 最近又开始用起py,是为什么呢? 自己要做一个文本相似度匹配程序,大致思路就是两个文档,一个是试题,一个是材料,我将试题按每题分割出来,再将每题的内 ...
- Asp.Net Core 2.0 项目实战(11) 基于OnActionExecuting全局过滤器,页面操作权限过滤控制到按钮级
1.权限管理 权限管理的基本定义:百度百科. 基于<Asp.Net Core 2.0 项目实战(10) 基于cookie登录授权认证并实现前台会员.后台管理员同时登录>我们做过了登录认证, ...
- 主题:实战WebService II: SOAP篇(基于php)
概述(SOAP和XML-PRC比较) 在Web服务发展的初期,XML格式化消息的第一个主要用途是,应用于XML-RPC协议,其中RPC代表远程过程调用.在XML远程过程调用 (XML-RPC)中,客户 ...
- 几篇关于RGBD语义分割文章的总结
最近在调研3D算法方面的工作,整理了几篇多视角学习的文章.还没调研完,先写个大概. 基于RGBD的语义分割的工作重点主要集中在如何将RGB信息和Depth信息融合,主要分为三类:省略. 目录 ...
- 第三篇 基于.net搭建热插拔式web框架(重造Controller)
由于.net MVC 的controller 依赖于HttpContext,而我们在上一篇中的沙箱模式已经把一次http请求转换为反射调用,并且http上下文不支持跨域,所以我们要重造一个contro ...
随机推荐
- Java实现蓝桥杯调和级数
1/1 + 1/2 + 1/3 + 1/4 + - 在数学上称为调和级数. 它是发散的,也就是说,只要加上足够多的项,就可以得到任意大的数字. 但是,它发散的很慢: 前1项和达到 1.0 前4项和才超 ...
- java实现杨辉三角系数
** 杨辉三角系数** (a+b)的n次幂的展开式中各项的系数很有规律,对于n=2,3,4时分别是:1 2 1, 1 3 3 1,1 4 6 4 1.这些系数构成了著名的杨辉三角形: 1 1 1 1 ...
- 【CSS】滚动条样式
/*定义滚动条宽高及背景,宽高分别对应横竖滚动条的尺寸*/ .scrollbar::-webkit-scrollbar{ width: 16px; height: 16px; background-c ...
- Mybatis连接池及事务
一:Mybatis连接池 我们在学习WEB技术的时候肯定接触过许多连接池,比如C3P0.dbcp.druid,但是我们今天说的mybatis中也有连接池技术,可是它采用的是自己内部实现了一个连接池技术 ...
- Java培训Day01——制作疫情地图(一)
一.前言 此次培训,是为期三天的网上培训.最终的目的是制作出疫情地图.首先我们来看看主要的讲课内容大纲. Day1 |-Java语法学习(个人感觉讲得还可以,主要围绕本次培训作出的讲解,没有像网上的基 ...
- MAC/VMware配置双机调试简述
Configuration 注:建议提前备份所有修改内容,可能会导致无法开机. 我的测试环境: server: windows 10 + windbg client: windows 7 Server ...
- Pytest单元测试框架——Pytest+Allure+Jenkins的应用
一.简介 pytest+allure+jenkins进行接口测试.生成测试报告.结合jenkins进行集成. pytest是python的一种单元测试框架,与python自带的unittest测试框架 ...
- 【loj - 3056】 「HNOI2019」多边形
目录 description solution accepted code details description 小 R 与小 W 在玩游戏. 他们有一个边数为 \(n\) 的凸多边形,其顶点沿逆时 ...
- 【精讲版】上位机C#/.NET与西门子PLC通信
618来啦 亲们,腾讯课堂101机构打榜了,快来助力<新阁教育>,<免费赠送课程>! 1.手机QQ(微信请也来一遍)扫下方二维码↓,找到<新阁教育> 2.点击“支持 ...
- ASP.NET处理管道初谈
客户端往发送的请求到达服务端到服务端响应回客户端的这段时间内,实际上服务器内并不只是简单地对请求进行处理,然后把处理结果响应回去,而是经过一系列多达19个事件之后才能产生最后地处理结果. 因此:其处理 ...