使用docker构建hadoop集群
docker的使用越来越普遍了,大家不知道docker的还需要进一步学习一下。这次咱们使用docker去进行hadoop集群的构建。
使用docker构建的好处真的很多,一台电脑上可以学习安装很多想做的东西,可以说是一个docker可以虚拟你想使用的任何环境。大家知道安装hadoop需要很多机器和资源,但是现在一台电脑就可以搞定,是不是感觉技术很强大。
下面咱们这边构建hadoop文章的梗概如下:
1. 介绍下docker的安装配置及常用的命令。
2. 安装过程所需要的工具。
3. 开始安装步骤。
Docker在使用前需要提前安装,不同的电脑安装的方式不一样,大家可以到官网上按照步骤进行安装,我的电脑是MAC的,下载一个dmg文件安装即可。很多同学安装好了之后拉取进行很慢,这个和我之前遇到的问题非常类似,因为docker的镜像库是国外的,要从国外访问并且拉取需要经历非常长的网络环境,这个时候就需要一些本地化的东西了。也就是找一些国内的镜像站。
我本地的电脑配置了两个,一个是阿里云的镜像加速站和国内镜像加速站。大家不知道方法的可以搜索一下。
mac电脑可以点击docker图标,选择 Preferences -> Daemon -> Registory mirrors(这个是旧版本的配置方式)。新版本选择 Preferences -> Docker Engine, 里边有一个Json内容个,把自己的国内镜像加速配置成如下json。注意大家要用自己的镜像加速id, 下面{your Id}要填写你自己的申请的id。除了配置这个以外还配置了一个国内站
{
"debug": true,
"registry-mirrors": [
"http://{your Id}.mirror.aliyuncs.com",
"http://registry.docker-cn.com"
],
"experimental": false
}
配置的时候有个需要注意的地方,就是给到的地址是 https,我们需要改为“http”,否则会出现不能获取cert文件。这个错误比较不容易发现,在使用的时候如果配置不正确的话,那么下载镜像的时候还是很慢。
安装好和配置好镜像加速后,我们接下来看一些常用的Docker命令:
docker search ubuntu, 这个是从镜像仓库进行搜索一些镜像,这个例子是搜索ubuntu的镜像的。
docker pull ubuntu, 这个是从镜像仓库下载最新版本的ubuntu。当然也可以执行版本号,像ubuntu:16.04。
docker start/stop {image id}, 运行和停止一个指定的镜像。
docker ps, 这个是查看当前正在运行的镜像进程。在后边加一个 -a,可以显示所有镜像进程,包括正在运行的以及已经结束的进程的。
docker attach {image id},进入正在运行的镜像仓库,输入exit即可退出镜像并且结束镜像运行。如果想镜像继续运行的话,需要按快捷键 Ctrl + p + q 退出。
docker run ubuntu:16.04,即运行本地仓库的ubuntu,版本号为16.04。如果本地仓库没有的话,那么就需要从远程仓库先pull到本地,然后再进行启动。
docker commit -m "comment" {image id} ubuntu:hadoop, 将运行后的某个镜像id保存成一个版本。也就是在即在镜像里边所做的修改都会保存起来。每次run的时候都是将原来的镜像重新启动,修改或操作的内容都不会保存。
docker images, 查看拉取下来的镜像以及自己提交的镜像都在里边。
docker network create --driver=bridge haoop, 创建docker网络,用于在同一个网络中的机器可以访问,模式为桥接模式,名称为hadoop。
docker network ls,查看所创建的网路名称。
基本的常用命令大概就是这些,咱们一起看一下目前搭建hadoop所使用的工具有哪些。
vim,文本编辑工具。
open-jdk1.8, hadoop使用, 当然同学们也可以使用oracle的jdk1.8。
net-tools, 网络工具,用于机器之间的访问时用。
openssh-server, openssh-cient ssh的服务器和客户端,用于远程免密访问。
scala, 这个hadoop需要的。
基本工具就这些,接下来我们开始安装Hadoop集群。集群的结构为一台master, 两台slaver-slave1, slave2。
使用命令“docker pull ubuntu:16.04”,将下载16.04版本的操作系统。下载完成之后可以通过 docker images 查看下载的镜像。
接下载我们需要进入到ubuntu里边去,将ubuntu原有的源进行备份为sources_init.list,然后把apt的源改为阿里的源,这样下载和安装一些工具的话会比较快。
docker run ubuntu:16.04 /bin/bash
cp /etc/apt/sources.list /etc/apt/sources_init.list
echo "deb http://mirrors.aliyun.com/ubuntu/ xenial main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main deb http://mirrors.aliyun.com/ubuntu/ xenial universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe" > /etc/apt/sources.list
执行apt update,将系统更新一下。接下来安装open-jdk1.8和scala。安装完成后查看一下java和scala, 使用 java -version有输出说明成功。执行scala进入scala环境,输入“:q”或者按Ctrl+D即可退出scala环境。
apt update
apt install openjdk--jdk
apt install scala
接下来安装编辑工具vim和网络工具 net-tools。
apt install vim
apt install net-tools
安装ssh服务端和客户端,用于远程免密访问。Hadoop采用使用指定机器名后,然后由脚本进行免密访问后,直接执行相应的命令,比如启动服务等,是不是很方便?
apt install openssh-server
apt install openssh-client
进入当前用户目录,然后生成免密登录的key。生成key的时候直接按回车即可。
cd ~
ssh-keygen -t rsa -P ""
这个时候会直接生成一个.ssh文件夹,通过ls -al进行查看。将生成的公钥key追加到授权的key列表。启动ssh服务,然后进行本机测试,如果能成功登陆,说明已经成功了
cat .ssh/id_rsa.put >> .ssh/authorized_keys
service ssh start
ssh 127.0.0.1
为了保证系统启动的时候也启动ssh服务,我们将启动命令 “service ssh start” 放到bashrc文件末尾中。
vim ~/.bashrc
接下来我们开始下载hadoop,将文件进行解压放到/usr/local/, 改名为hadoop。
wget https://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz
tar -zxvf hadoop-3.2..tar.gz -C /usr/local
cd /usr/local
mv hadoop-3.2. hadoop
通过命令“update-alternatives --config java” 查看一下java的安装路径。配置一下本地的JAVA和Hadoop环境。通过使用命令“vim /etc/profile”,然后放好内容保存后,执行“source /etc/profile”,让配置的变量内容立即成生效。
#java
export JAVA_HOME=/usr/lib/jvm/java--openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
修改hadoop的环境变量,“vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh”,加入如下变量后保存。配置JAVA环境变量,各节点的用户。
export JAVA_HOME=/usr/lib/jvm/java--openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
修改hadoop下的环境/usr/local/hadoop/conf下的core-site.xml。加入如下内容。fs.default.name 为默认的master节点。hadoop.tmp.dir为hadoop默认的文件路径。如果本机没有的话需要自己通过 mkdir 命令进行创建。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
</property>
</configuration>
修改同目录conf下的hdfs-site.xml。dfs.replication即从节点的数量,2个从节点。dfs.namenode.name.dir为namenode的元数据存放的路径,dfs.namenode.data.dir是数据锁存放的路径。
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/root/hadoop/hdfs/data</value>
</property>
</configuration>
修改同目录conf下的mapred-site.xml。指定mapreduce执行框架设置为yarn。mapreduce.application.classpath 设置mapreduce的应用执行类路径。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
修改yarn.xml。yarn.resourcemanager.hostname为yarn资源管理的主机名为master机器。 yarn.nodemanager.aux-services说明当前yarn采用mapreduce洗牌的方式进行处理。
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
修改conf/workers, 即告诉Hadoop worker的机器为哪些。删除localhost,加入如下内容。
slave1
slave2
进入Hadoop的bin路径下将namenode进行格式化。这样hadoop才可以使用,否则无法使用。
./bin/hadoop namenode -format
Hadoop的基本配置文件和内容已经配置好,下一步我们退出镜像,Ctrl+c 或者输入exit即可退出。我们通过docker ps -a 查看这个进行的container id。接下来保存为 ubuntu:hadoop镜像。
docker commit -m "hadoop install" {CONTAINER ID} ubuntu:hadoop
我们创建一个hadoop机器环境内所需要的网络环境。同一个网络环境下可以直接进行访问。创建好了了之后通过第二个命令进行查看创建了哪些网络环境。
docker network create --driver=bridge hadoop
docker network ls
接下来我们开三个Terminal窗口,每个窗口分别执行一条命令。-h 指定主机名,有了主机名可以直接通过主机名访问机器。 --name指定容器名。如果我们一会儿退出了之后,我们可以通过“docker restart master”进行master的启动。-p为将容器里边的端口暴露为外边使用的端口。因为master可以通过如下两个界面进行访问,所以暴露出来两个端口。
docker run -it --network hadoop -h "master" --name "master" -p : -p : ubuntu:hadoop /bin/bash
docker run -it --network hadoop -h "slave1" --name "slave1" ubuntu:hadoop /bin/bash
docker run -it --network hadoop -h "slave2" --name "slave2" ubuntu:hadoop /bin/bash
如果我们采用docker start master -d,这种守护进行启动的,那么我们需要通过docker attach {image id}进入机器。我们在master的机器上启动所有节点。我们不需要用再去slave1和slave2执行此命令,因为我们刚才的免密ssh已经在脚本里边操作好了。
cd /usr/local/hadoop/sbin/
./start-all.sh
如果一切启动都正常的话,我们访问本地 localhost:9870 和 localhost:8088 。
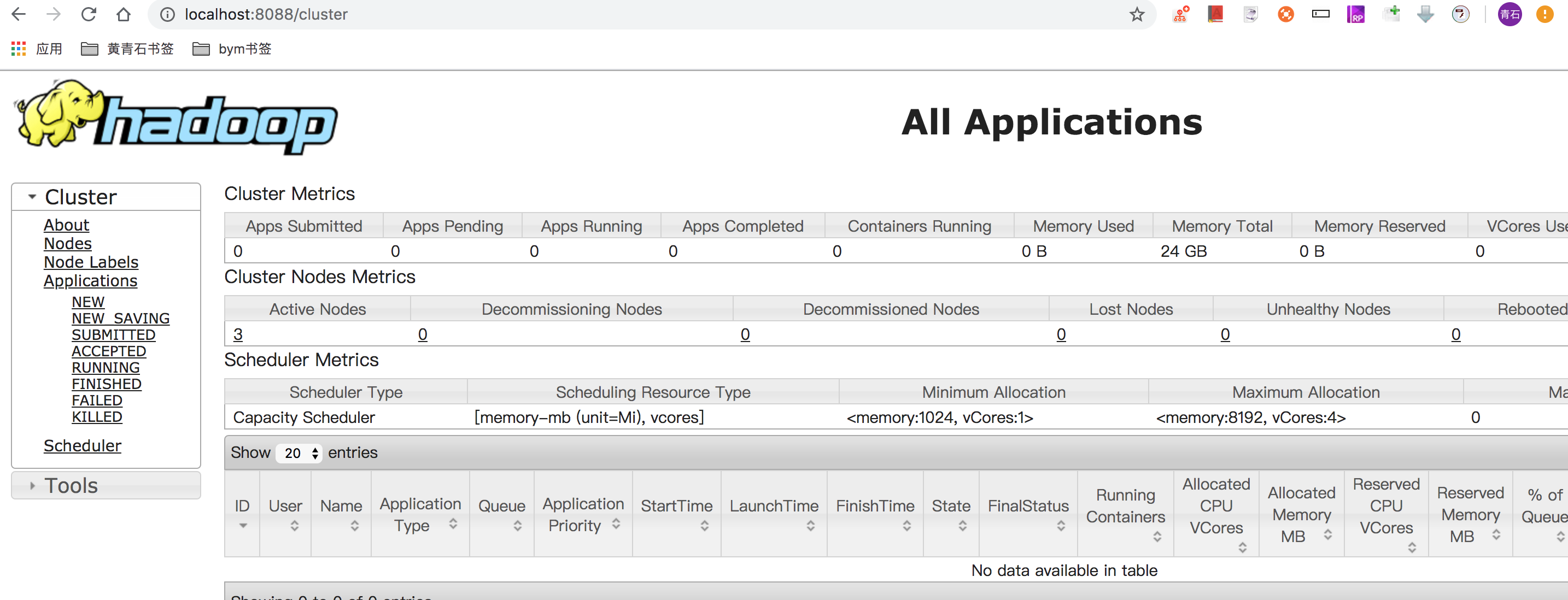
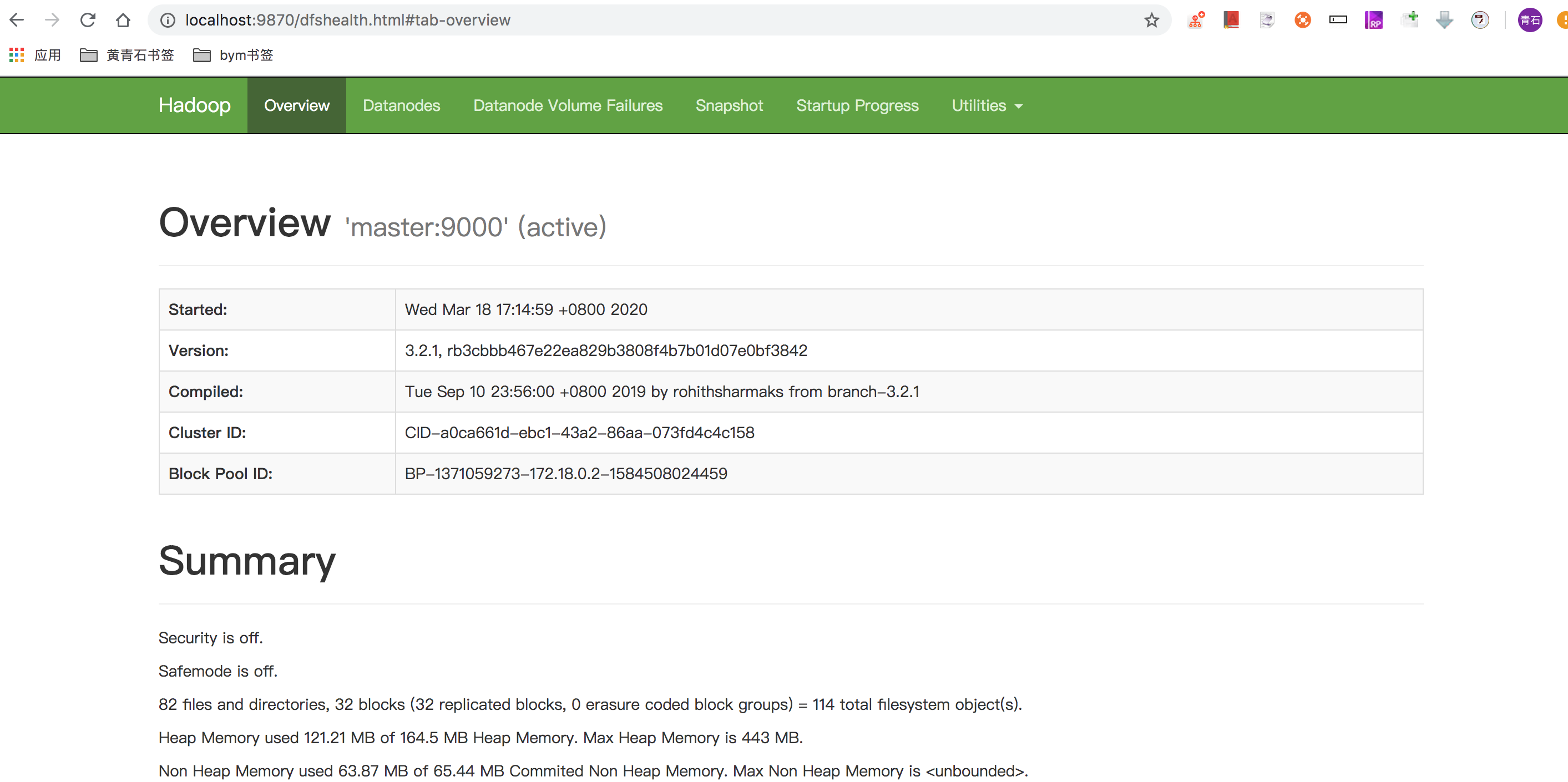
这说明就成功了。接下来咱们使用内置的wordcount程序执行以下,然后查看一下结果。
我们进入hadoop的bin目录下,将上级的README.txt写入到file.txt文件里边。在HDFS创建一个input目录,将文件上传到input目录里边,然后看一下input目录里边是否有文件。然后就可以使用内容的wordcount进行调用。将结果集放到/output里边。
cat ../README.txt > ../file.txt
./hadoop fs -mkdir /input
./hadoop fs -put ../file.txt /input
./hadoop fs -ls /input
./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2..jar wordcount /input /output
等执行完了也就出现了 map 100% reduce 100%。这个时候说明执行成功了,也就是讲文件的单词进行统计了。查看一下output文件目录“./hadoop fs -ls /output”,里边有两个文件,_SUCCESS说明成功了,里边的part-r-0000是结果集,通过命令“./hadoo fs -cat /output/part-r-0000”就可以查看结果集了。
Found items
-rw-r--r-- root supergroup -- : /output/_SUCCESS
-rw-r--r-- root supergroup -- : /output/part-r-
好了,完整的搭建过程就完成了。
使用docker构建hadoop集群的更多相关文章
- Docker部署Hadoop集群
Docker部署Hadoop集群 2016-09-27 杜亦舒 前几天写了文章"Hadoop 集群搭建"之后,一个朋友留言说希望介绍下如何使用Docker部署,这个建议很好,Doc ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- docker安装hadoop集群
docker安装hadoop集群?图啥呢?不图啥,就是图好玩.本篇博客主要是来教大家如何搭建一个docker的hadoop集群.不要问 为什么我要做这么无聊的事情,答案你也许知道,因为没有女票.... ...
- 构建hadoop集群时遇到的问题
在构建hadoop集群时,出现过主节点中的namenode或datanode启动不成功的问题.在日志文件中往往会显示namenode和datanode中clusterID不相同的问题,这个问题往往都是 ...
- 大数据开发学习之构建Hadoop集群-(0)
有多种方式来获取hadoop集群,包括从其他人获取或是自行搭建专属集群,抑或是从Cloudera Manager 或apach ambari等管理工具来构建hadoop集群等,但是由自己搭建则可以了解 ...
- 使用docker部署hadoop集群
最近要在公司里搭建一个hadoop测试集群,于是采用docker来快速部署hadoop集群. 0. 写在前面 网上也已经有很多教程了,但是其中都有不少坑,在此记录一下自己安装的过程. 目标:使用doc ...
- docker搭建Hadoop集群
一个分布式系统基础架构,由Apache基金会所开发. 用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储. 首先搭建Docker环境,Docker版本大于1.3. ...
- 使用Docker构建redis集群--最靠谱的版本
1集群结构说明 集群中有三个主节点,三个从节点,一共六个结点.因此要构建六个redis的docker容器.在宿主机中将这六个独立的redis结点关联成一个redis集群.需要用到官方提供的ruby脚本 ...
- Docker 构建 RabbitMQ 集群
刚开始,关于RabbitMQ集群的搭建,我找到了这篇文章:Docker 安装 RabbitMQ 集群 从而找到了第三方的RabbitMQ集群容器 rabbitmq-server 但是这个容器只有3.6 ...
随机推荐
- (转)假如没有OI By Vani
假如没有OI ...
- 最优化算法——常见优化算法分类及总结
之前做特征选择,实现过基于群智能算法进行最优化的搜索,看过一些群智能优化算法的论文,在此做一下总结. 在生活或者工作中存在各种各样的最优化问题,比如每个企业和个人都要考虑的一个问题"在一定成 ...
- tfjs-node初体验:训练模型的存储
JS,一门从浏览器兴起,却不止于浏览器的脚本,个人一直认为其是最有潜力的脚本语言.不只是因为ES6优雅的语法,更重要的是其易上手,跨平台的优点. Node将JS从browser带去了client是革命 ...
- 如何手动添加jar包到本地maven仓库
环境 win10 idea工具 1.确认已经安装好 mvn环境 MAVEN_HOME D:\Tool\apache-maven-3.5.2 Path %MAVEN_HOME%\bin 2 ...
- 吴裕雄--天生自然 R语言开发学习:基本统计分析(续三)
#---------------------------------------------------------------------# # R in Action (2nd ed): Chap ...
- 跟随大神实现简单的Vue框架
自己用vue也不久了,学习之初就看过vue实现的原理,当时看也是迷迷糊糊,能说出来最基本的,但是感觉还是理解的不深入,最近找到了之前收藏的文章,跟着大神一步步敲了一下简易的实现,算是又加深了理解. 原 ...
- 2018年宜賓美酒文化節浮空投影舞美特效 / 2018 Yibing Wine Festival Visual Effect Projection
客户 Client:五粮液集团 硬件 Hardware:PC,巴可投影机30,000流明*2 Barco projector 30,000 lumen*2 软件 Software:Resolume, ...
- Leetcode刷题记录 剑指offer
面试题3:数组中重复数字 # 使用set,时间复杂度O(n),空间复杂度O(n)class Solution(object): def findRepeatNumber(self, nums): &q ...
- Oil Deposits(油田)(DFS)
题目: The GeoSurvComp geologic survey company is responsible for detecting underground oil deposits. G ...
- 初学Qt——程序打包(环境vs2012+qt5.1.0)
说来可笑,网上那么多的教程,偏偏结尾的时候就没有一个能详细的讲下关于程序的发布.开发Qt是这样,刚开始做web也是这样,因为是自学的,所以都没人可以教下,结果到了项目完成的最后总是要花费成吨的时间去查 ...