基于scrapy框架输入关键字爬取有关贴吧帖子
基于scrapy框架输入关键字爬取有关贴吧帖子
站点分析
首先进入一个贴吧,要想达到输入关键词爬取爬取指定贴吧,必然需要利用搜索引擎
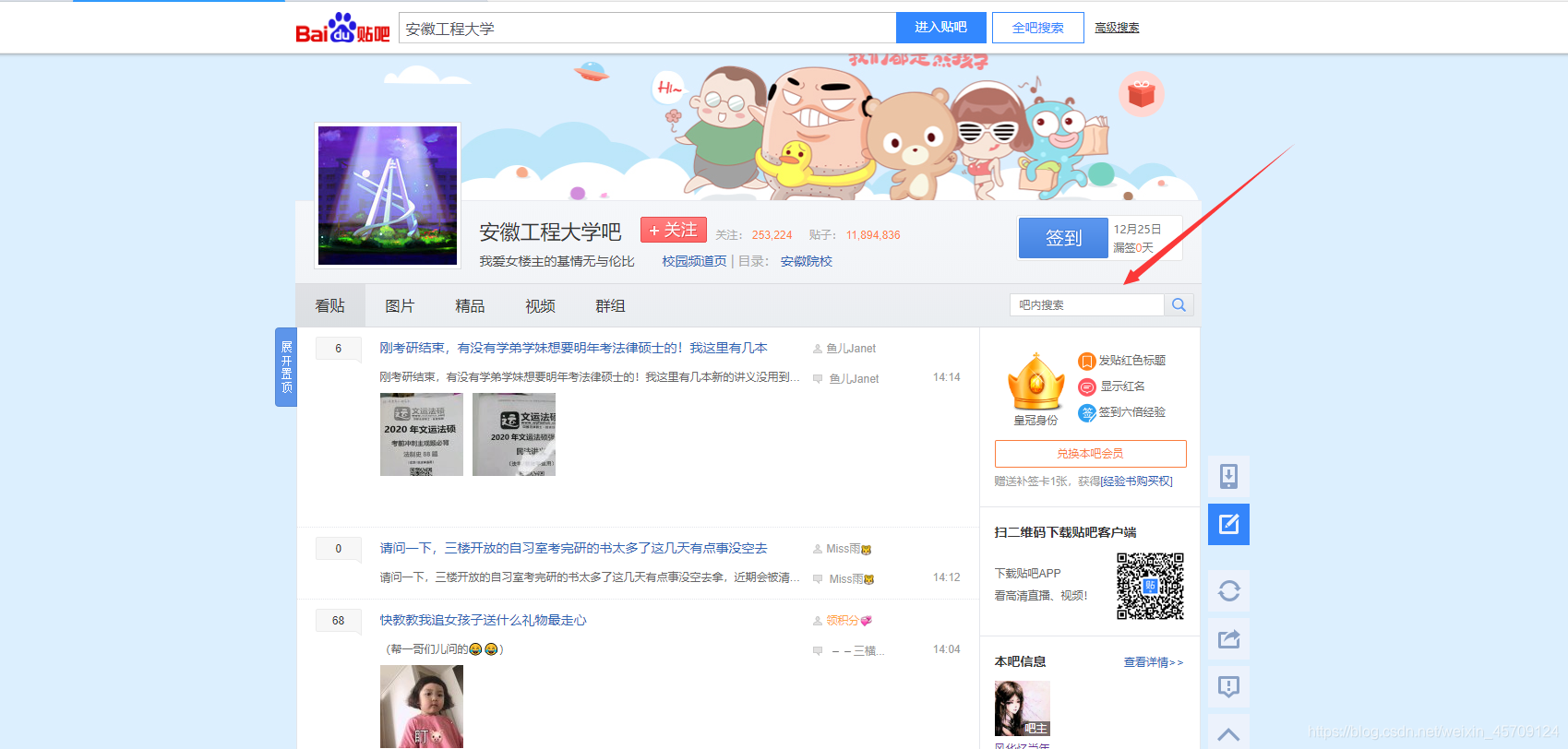
点进看到有四种搜索方式,分别试一次,观察url变化

我们得知:
搜索贴吧:http://tieba.baidu.com/f/search/fm?ie=UTF-8&qw=dfd
搜索帖子:http://tieba.baidu.com/f/search/res?ie=utf-8&qw=dfd
其中参数qw是搜索关键词,由此我们可以构建搜索贴吧的url
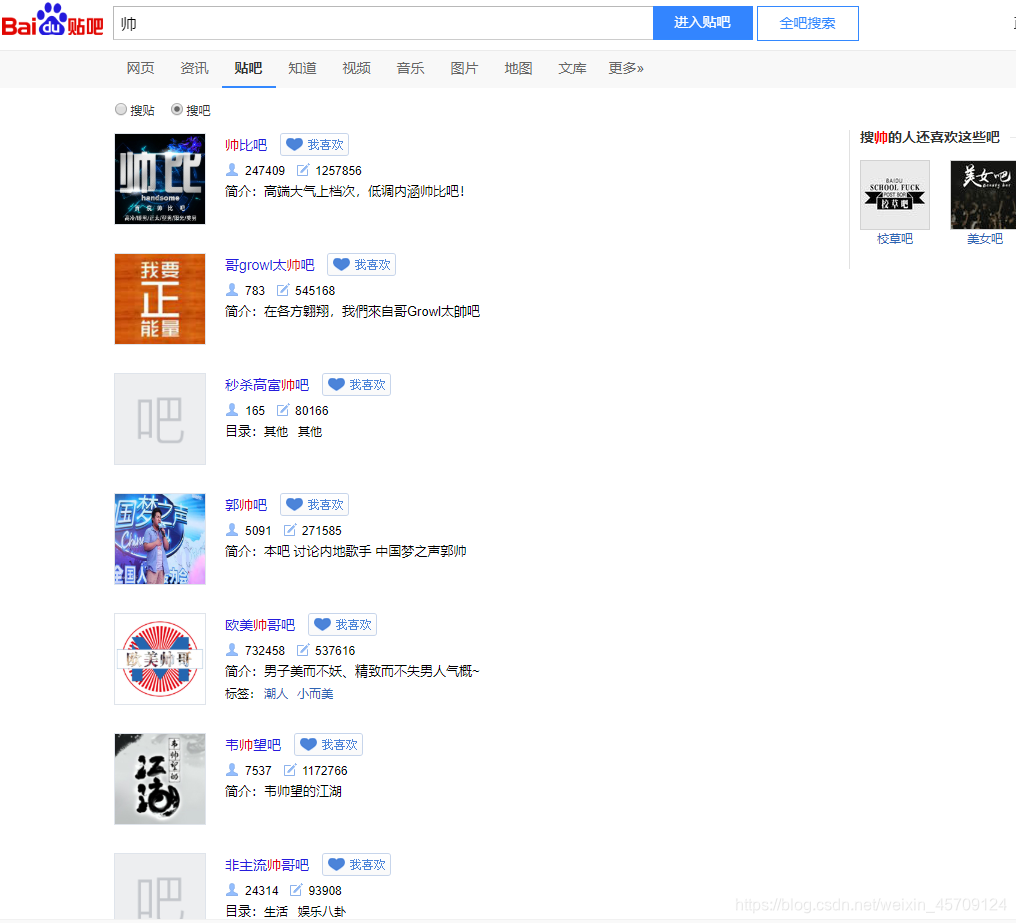
搜索得到的页面,可以得到我们需要的贴吧url
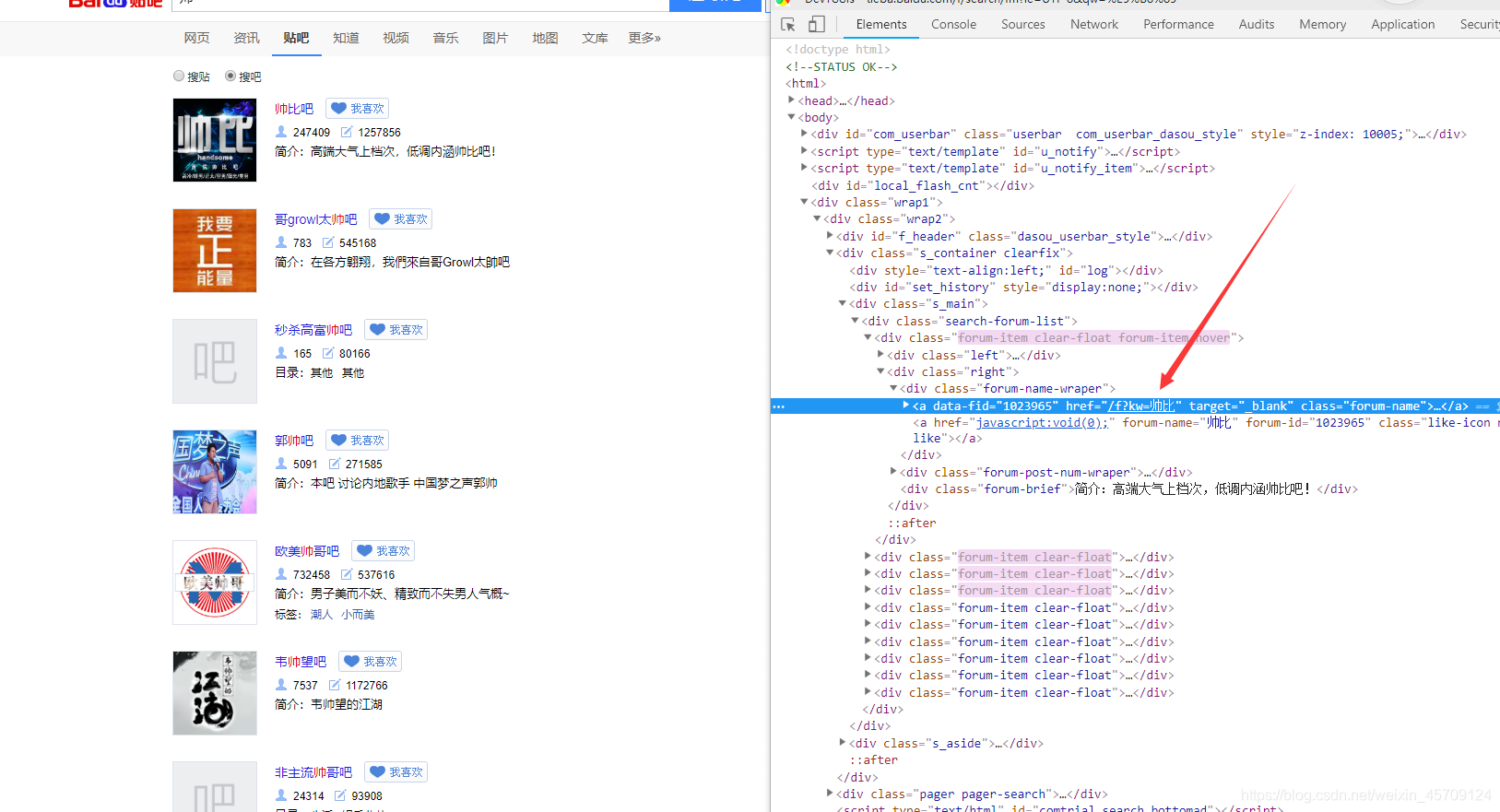
我们就可以轻而易举的得到我们搜索的相关贴吧
下面对贴吧主页进行分析
进入贴吧F12查看

显然我们知道#thread_list这个列表,观察看到这就是每个贴在,注意li标签里的data-field字段有我们需要的信息, 不过我们只需要得到帖子的url,之后对帖子进一步提取,其中data-tid就是贴子的id,通过这个我们可以定位唯一的帖子
如data-tid="6410699527", 则帖子的url为teiba.baidu.com/p/6410699527具体的探索过程就不一一阐述了。。。
对帖子分析

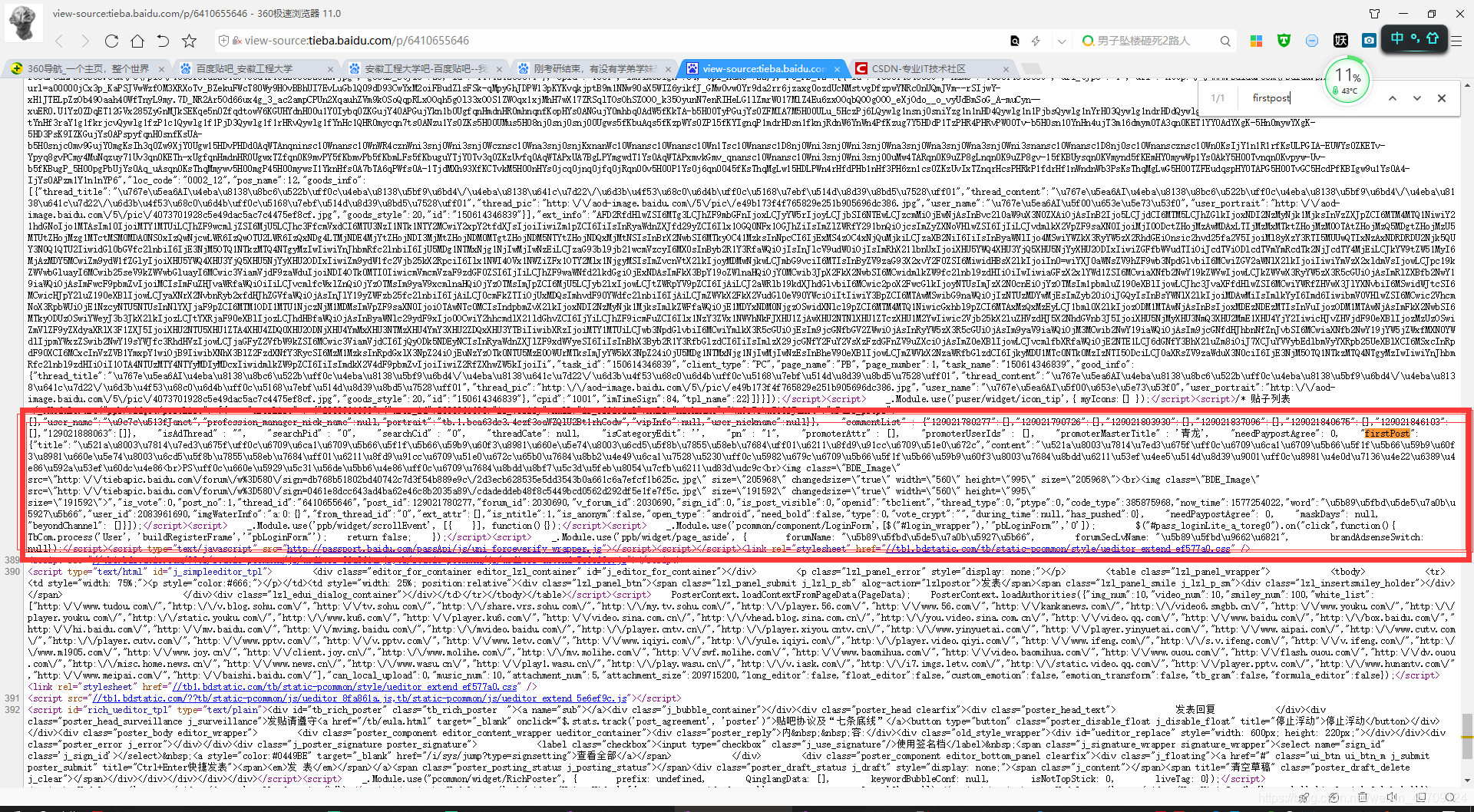
直接源码省去很多字、、、的寻找过程,我们在源码找到了一段JavaScript代码,其中firstpost就是楼主发的帖子。。为什么不在HTML便签中提取?因为你试试就知道了,开始我就是在HTML便签中提取的,部分贴吧标题提取不出来。firstpost有着很详细的信息,标题,内容,时间
现在对贴吧的回复贴吧提取:
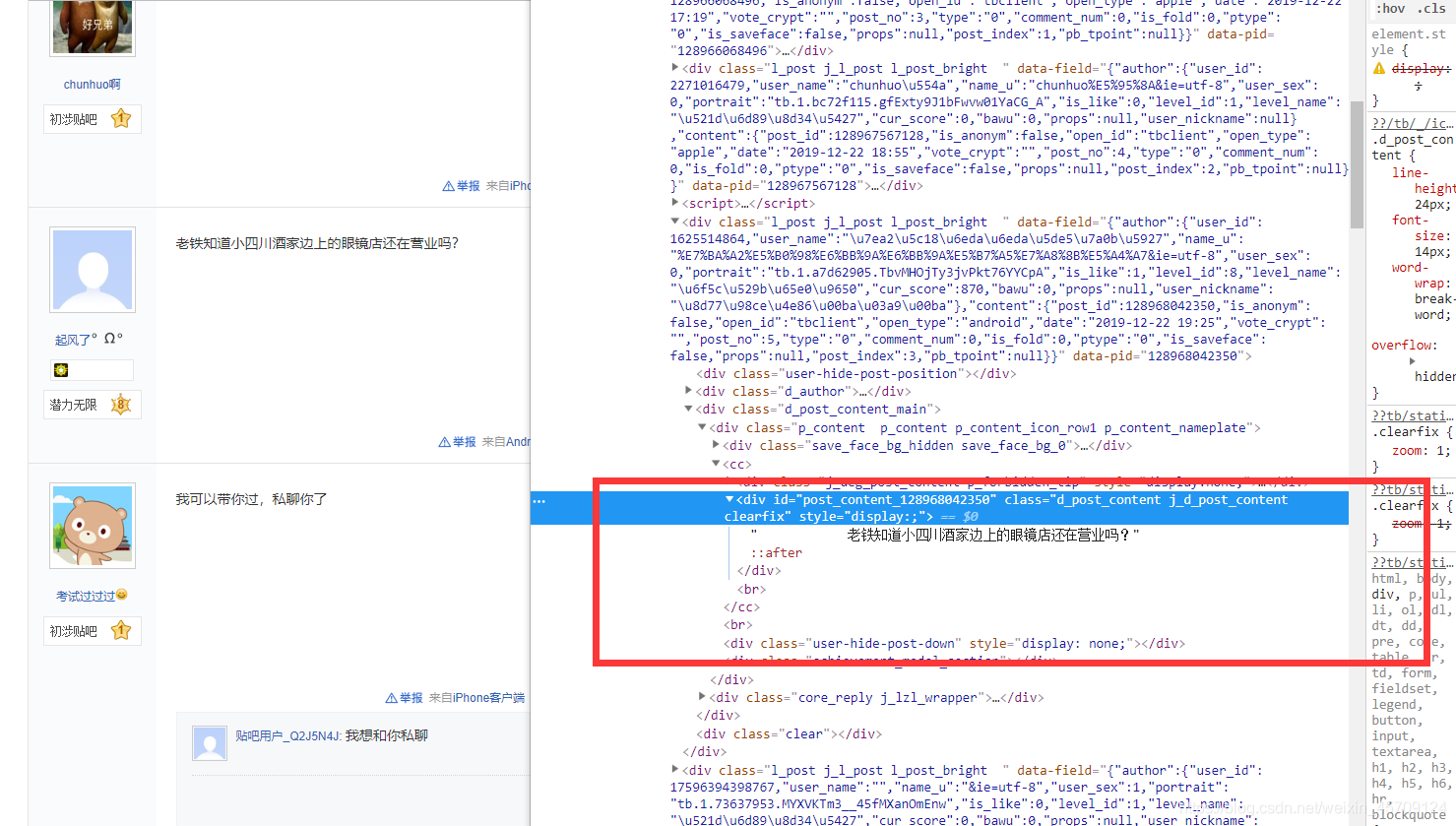
探索得知,很多带有表情的回复帖,内容很乱,打算正则提取。。。
一个小白的分析过程想的多,看的慢,难受!这里就不在阐述了,不然分析过程写不下
items.py编写
在这个模块里定义自己的字段,这里我们需要帖子的标题,内容,作者,时间,回复数,回复内容源码:# -*- coding: utf-8 -*-import scrapyclass postDataItem(scrapy.Item):tid = scrapy.Field()title = scrapy.Field()content = scrapy.Field()author_name = scrapy.Field()date = scrapy.Field()reply_content = scrapy.Field()reply_num = scrapy.Field()device = scrapy.Field()#这给字段读者不必关注,项目所需
pipelines.py的编写
没有;哈哈,还没想好用什么数据库
爬虫模块的编写
# -*- coding: utf-8 -*-import scrapyfrom urllib.parse import urlencodefrom scrapy.http import Requestimport reimport timefrom ..items import postDataItemclass BtspiderSpider(scrapy.Spider):name = 'btSpider'allowed_domains = ['tieba.baidu.com']base_url = 'http://tieba.baidu.com'def start_requests(self):"""开始搜索相关学校贴吧"""search_base_url = 'http://tieba.baidu.com/f/search/fm?ie=UTF-8&'arg1 = urlencode({'qw':self.school}) #通过命令行传递属性search_url = search_base_url + arg1yield Request(url=search_url, callback=self.get_search_page_urls, dont_filter=True) #搜索的url送到调度器, 注意:这个url不参与去重下面用到def get_search_page_urls(self, response):"""获得搜索结果所有页面,发送每页的url到调度器"""pager_search = response.xpath("//div[@class='pager pager-search']/a/@href").extract()[:-2]pager_search = [(self.base_url + pager) for pager in pager_search ]pager_search.append(response.url)for pager_url in pager_search:yield Request(url=pager_url, callback=self.get_forum_urls)def get_forum_urls(self, response):"""获得所有相关贴吧的url送到调度器"""forum_lists = response.xpath('//div[@class="search-forum-list"]/div[@class="forum-item clear-float"]')for forum in forum_lists:forum_url = self.base_url + forum.xpath('./div[@class="left"]/a/@href').extract_first()yield Request(url=forum_url, callback=self.get_post_urls)def get_post_urls(self, response):"""获得所有帖子的url"""postList = response.xpath("//li[@class=' j_thread_list clearfix']")for post in postList:data_tid = post.xpath("./@data-tid").extract_first()post_url = self.base_url + '/p/' + data_tidyield Request(url=post_url, callback=self.get_post_data)#实现翻页操作url_list = response.xpath("//div[@id='frs_list_pager']/a")[:-2]for url in url_list:if int(re.findall('.*pn=(\d*)', url.xpath('./@href').extract_first())[0]) <= 20000:yield response.follow(url=url, callback=self.get_post_urls)else:break
def get_post_data(self, response):post_data_item = postDataItem()# 提取帖子idtid = re.compile("https?://tieba.baidu.com/p/(\d*).*").findall(response.url)[0]post_data_item['tid'] = tid# 提取帖子内容的正则表达式,来源为页面底部JavaScript代码rpost = '"firstPost": {"title":"(?P<title>.*)","content":"(?P<content>.*)","is_vote".*"now_time":(?P<date>\d*)'post = re.search(rpost, response.text)# 将字符串Unicode编码转换为中文dirty_title = post.group('title').encode('utf-8').decode("unicode_escape")dirty_content = post.group('content').encode('utf-8').decode("unicode_escape")# 找到所有标签替换为空post_data_item['title'] = re.sub('<.*?>', '', dirty_title)post_data_item['content'] = re.sub('<.*?>', '', dirty_content)# 时间戳转换为字符串时间post_data_item['date'] = time.strftime("%Y-%m-%d %X", time.localtime(int(post.group('date'))))# 提取作者的xpath表达式xauthor = "//div[contains(@class, 'louzhubiaoshi')]/@author"post_data_item['author_name'] = response.xpath(xauthor).extract_first()# 提取楼层回复内容的xpath表达式,是所有的内容# 这是经过清洗的数据用它来做分析xreply_content = "//div[contains(@class, 'd_post_content')]/text()"all_content = response.xpath(xreply_content).extract()all_content_dirty = ''.join(all_content)post_data_item['reply_content'] = ''.join(re.findall(r'[\u4e00-\u9fa5]', all_content_dirty))# 提取帖子回复数量的xpath表达式xreply_num = "//span[@class='red']/text()"post_data_item['reply_num'] = response.xpath(xreply_num).extract_first()for key, value in post_data_item.items():print(key, value)
运行结果
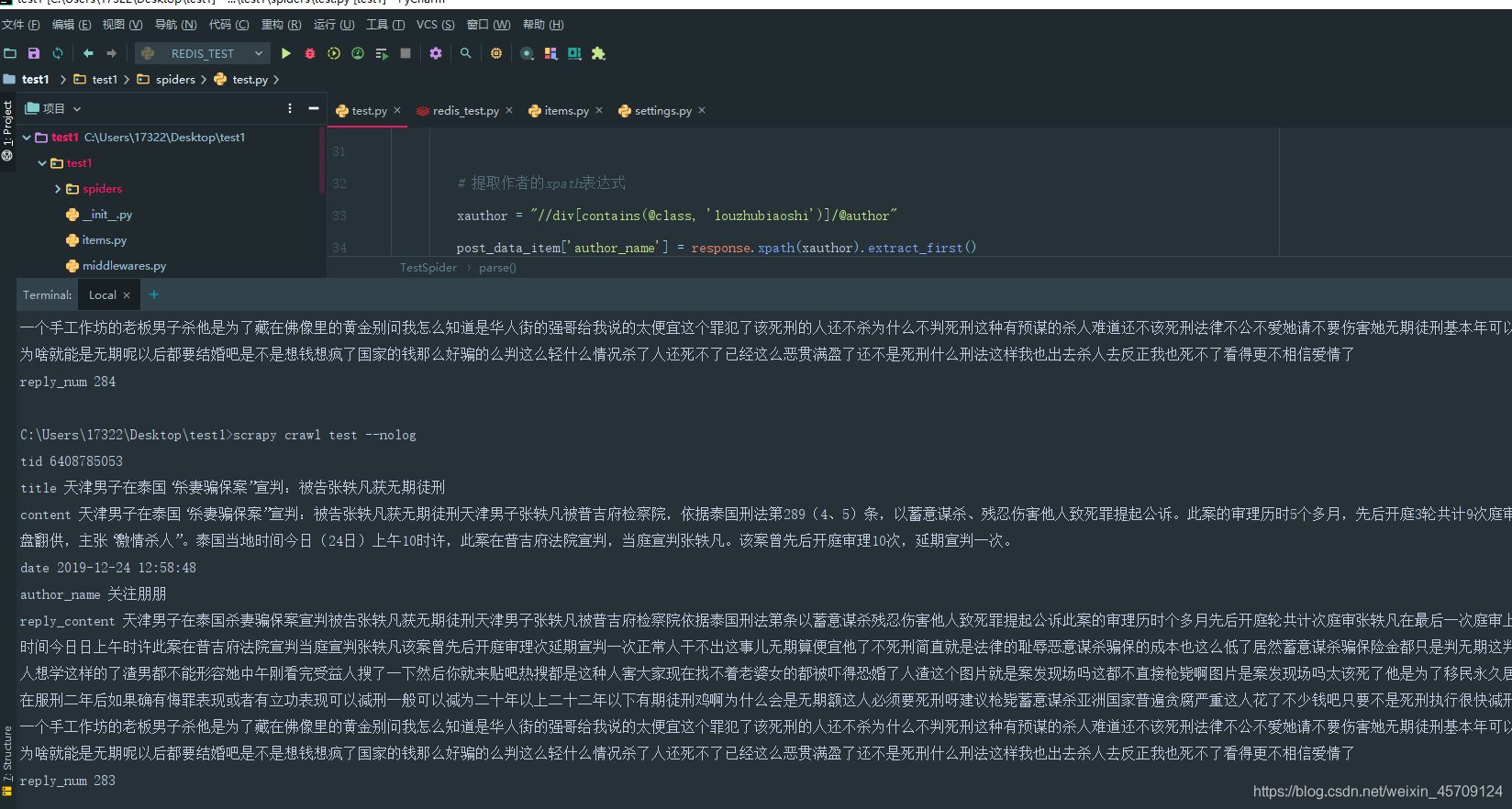
注意这是,我爬虫的精简版,只专注于一个帖子爬取
基于scrapy框架输入关键字爬取有关贴吧帖子的更多相关文章
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- scrapy框架综合运用 爬取天气预报 + 定时任务
爬取目标网站: http://www.weather.com.cn/ 具体区域天气地址: http://www.weather.com.cn/weather1d/101280601.shtm(深圳) ...
- Scrapy 框架 使用 selenium 爬取动态加载内容
使用 selenium 爬取动态加载内容 开启中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMidd ...
- Scrapy框架——使用CrawlSpider爬取数据
引言 本篇介绍Crawlspider,相比于Spider,Crawlspider更适用于批量爬取网页 Crawlspider Crawlspider适用于对网站爬取批量网页,相对比Spider类,Cr ...
- 信息技术手册可视化进度报告 基于BeautifulSoup框架的python3爬取数据并连接保存到MySQL数据库
老师给我们提供了一个word文档,里面是一份信息行业热词解释手册,要求我们把里面的文字存进数据库里面,然后在前台展示出来. 首先面临的问题是怎么把数据导进MySQL数据库,大家都有自己的方法,我采用了 ...
- scrapy框架基于CrawlSpider的全站数据爬取
引入 提问:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法 ...
- Python爬虫:通过关键字爬取百度图片
使用工具:Python2.7 点我下载 scrapy框架 sublime text3 一.搭建python(Windows版本) 1.安装python2.7 ---然后在cmd当中输入python,界 ...
- 基于scrapy框架的爬虫
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. scrapy 框架 高性能的网络请求 高性能的数据解析 高性能的 ...
- 基于Scrapy框架的Python新闻爬虫
概述 该项目是基于Scrapy框架的Python新闻爬虫,能够爬取网易,搜狐,凤凰和澎湃网站上的新闻,将标题,内容,评论,时间等内容整理并保存到本地 详细 代码下载:http://www.demoda ...
随机推荐
- Bootstrap 基本配置与应用
配置使用 下载文件引用 下载方式:Bootstrap官网 https://www.bootcss.com/ 引用 例: <head> <meta charset="utf- ...
- 切比雪夫低副瓣阵列设计 MATLAB
相控阵天线中,直线阵列作为重要的一种,有着极为广泛的应用.切比雪夫低副瓣阵列设计是一种典型的设计方法. 切比雪夫方法主要是实现低副瓣.窄波束: 其产生的核心如下: 我的理解:因为能量守恒,所有副瓣都一 ...
- IO多路复用(IO Multiplexing)
什么是IO多路复用 为什么要有IO多路复用 作者总结 遵循学习新知识的三部曲:是什么?为什么?怎么用? 作者前言:IO多路复用本质上是网络通信过程中的一个技术名词. 什么是IO多路复用 一个用机场管理 ...
- c++实现单纯形法现行规划问题的求解
在本程序中默认该现行规划问题有最优解 针对此问题: #include<iostream> using namespace std; int check(float *sigema, int ...
- python之面向对象的成员,方法,属性,异常处理
一.类的私有成员 1. 类中的私有成员是什么? 私有:只有满足一部分条件的才能使用 私有类的属性 私有对象的属性 私有方法 正常状态 class B: school_name = '老男孩教育' de ...
- OpenCV-Python OpenCV中的K-Means聚类 | 五十八
目标 了解如何在OpenCV中使用cv.kmeans()函数进行数据聚类 理解参数 输入参数 sample:它应该是np.float32数据类型,并且每个功能都应该放在单个列中. nclusters( ...
- OpenCV-Python 特征匹配 | 四十四
目标 在本章中, 我们将看到如何将一个图像中的特征与其他图像进行匹配. 我们将在OpenCV中使用Brute-Force匹配器和FLANN匹配器 Brute-Force匹配器的基础 蛮力匹配器很简单. ...
- Windows下命令行MySQL安装
通过zip压缩包文件直接安装 1.下载链接 https://dev.mysql.com/downloads/mysql/ 下载好后解压移动文件夹 2.配环境变量 path路径追加 3.创建初始化文件 ...
- VS2015 远程调试:Remote Debugger
一.关于Remote Debugger 使用VS远程调试器Remote Debugger,我们可以调试部署在不同机器上的应用程序,如桌面应用程序和Asp.Net应用程序. 二.Remote Debug ...
- Ubuntu文件(文件夹)创建(删除)
创建 创建文件: touch a.txt创建文件夹: mkdir NewFolderName 删除 删除文件: rm a.txt删除文件夹: rmdir FolderName删除带有文件的文件夹: r ...