Python数据分析之双色球高频数据统计
Step1:基础数据准备(通过爬虫获取到),以下是从第一期03年双色球开奖号到今天的所有数据整理,截止目前一共2549期,balls.txt 文件内容如下 :
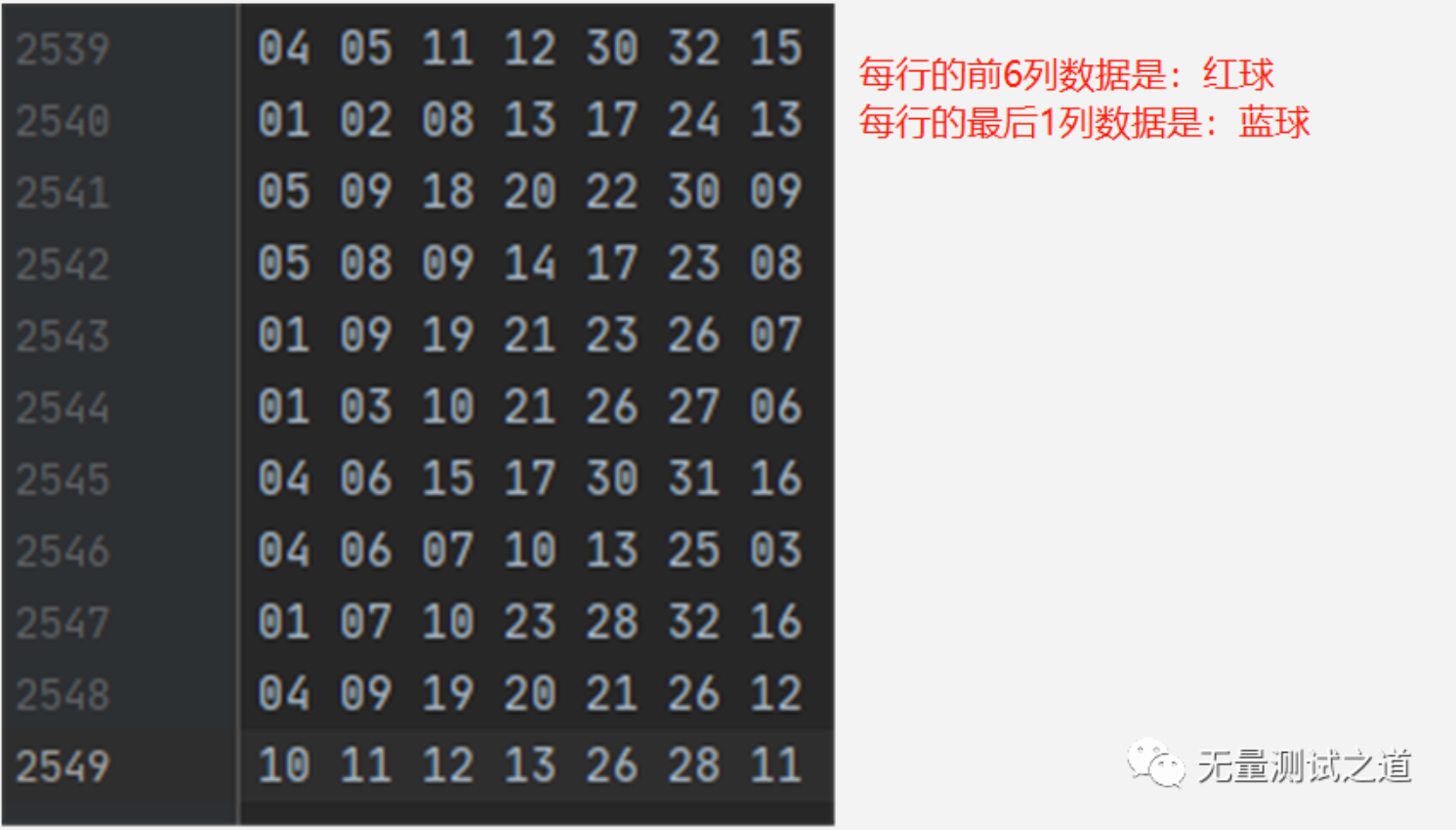
备注:想要现成数据的可以给我发邮件哟~
Step2: 分析数据特征和数据处理方式选择,直接上代码如下:
#导入Counter
from collections import Counter
def readfile():
red_lists=[]
blue_lists=[]
#打开文件并获取文件句柄
with open("./balls.txt", "r",encoding='utf-8') as fp:
#开始读取文件并返回一个list
list1=fp.readlines()
#遍历整个文件内容
for i in range(len(list1)):
#替换掉\n的字符再按空格分隔
list2=str(list1[i]).replace("\n","").split(" ")
for j in range(len(list2)):
if j==6:
#蓝球放入到blue_lists 列表中
blue_lists.append(list2[j])
else:
#红球放入到red_lists 列表中
red_lists.append(list2[j])
#Counter可以快速便捷的对某些对象做一些统计操作,这里是对列表里面的数据进行出现次数统计,返回一个tuple
red_count=Counter(red_lists)
blue_count=Counter(blue_lists)
#most_common可以用来统计列表或字符串中最常出现的元素并做排序,并返回一个list
k = red_count.most_common(len(red_count))
#输出出现频率最高的六个红球
print("the red ball:",k[:6])
l = blue_count.most_common(len(blue_count))
#输出出现频率最高的六个蓝球
print("the blue ball:",l[:6])
if __name__=="__main__":
readfile()
Step3:执行结果如下:

Step4:执行结果验证:
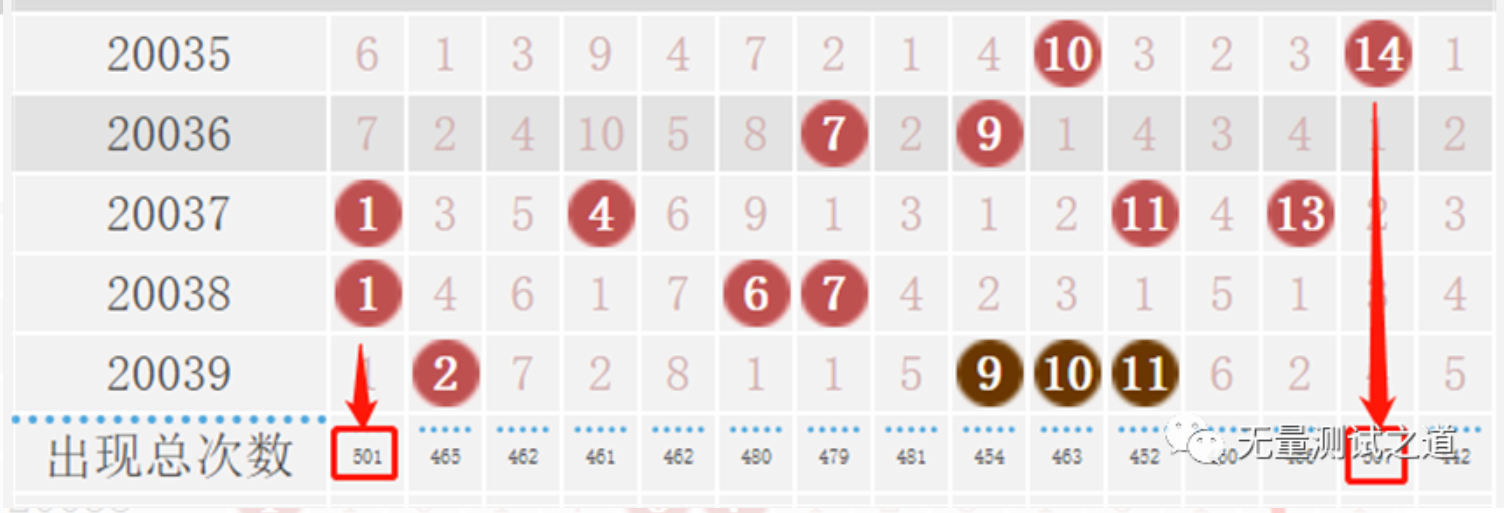
从官网获取的数据进行对比,一致性校验通过。
总结:python在数据处理方面有着非常强大的优势,其实早先用过Panda库也可以非常出色的完成双色球的数据统计,大家有兴趣的可以实验一下。
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,一起共同成长吧。
Python数据分析之双色球高频数据统计的更多相关文章
- Python数据分析:大众点评数据进行选址
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:砂糖侠 如果你处于想学Python或者正在学习Python,Pyth ...
- Python 数据分析 - 索引和选择数据
loc,iloc,ix三者间的区别和联系 loc .loc is primarily label based, but may also be used with a boolean array. 就 ...
- python数据分析之csv/txt数据的导入和保存
约定: import numpy as np import pandas as pd 1 2 3 一.CSV数据的导入和保存 csv数据一般格式为逗号分隔,可在excel中打开展示. 示例 data1 ...
- Python数据分析之文本处理词频统计
1.项目背景: 原本计划着爬某房产网站的数据做点分析, 结果数据太烂了,链家网的数据干净点, 但都是新开楼盘,没有时间维度,分析意义不大. 学习的步伐不能ting,自然语言处理还的go on 2.分析 ...
- python数据分析第二版:数据加载,存储和格式
一:读取数据的函数 1.读取csv文件 import numpy as np import pandas as pd data = pd.read_csv("C:\\Users\\Admin ...
- Python数据分析之全球人口数据
这篇文章用pandas对全球的人口数据做个简单分析.我收集全球各国1960-2019年人口数据,包含男女和不同年龄段,共6个文件. pop_total.csv: 各国每年总人口 pop_female. ...
- Python 数据分析—第七章 数据归整:清理、转换、合并、重塑
一.数据库风格的Dataframe合并 import pandas as pd import numpy as np df1 = pd.DataFrame({'1key':['b','b','a',' ...
- 【python数据分析实战】电影票房数据分析(二)数据可视化
目录 图1 每年的月票房走势图 图2 年票房总值.上映影片总数及观影人次 图3 单片总票房及日均票房 图4 单片票房及上映月份关系图 在上一部分<[python数据分析实战]电影票房数据分析(一 ...
- 小白学 Python 数据分析(5):Pandas (四)基础操作(1)查看数据
在家为国家做贡献太无聊,不如跟我一起学点 Python 人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Panda ...
随机推荐
- LUNIX命令集
Linux 是一套免费使用和自由传播的类 Unix 操作系统,是一个基于 POSIX 和 UNIX 的多用户.多任务.支持多线程和多 CPU 的操作系统. Linux 能运行主要的 UNIX 工具软件 ...
- 二、YARN
一.YARN 介绍 yarn 是下一代 MapReduce,即 MRv2,是在第一代 MapReduce 基础上演变而来的,主要是为了解决原始 Hadoop 扩展性较差,不支持多计算框架而提出的,通俗 ...
- 判断对象oStringObject是否为String
1.操作符 (1)typeof操作符 格式:result=typeof variable 返回值: undefined 值未定义 boolean 布尔值 string 字符串 number 数值 ob ...
- lonic常用组件之五------按钮
一.Ionic常用组件之五------按钮 <ion-button color="主题色" size="small/large" expand=& ...
- 苏浪浪 201771010120 面向对象程序设计(Java)第13周
/实验十三 图形界面事件处理技术 1.实验目的与要求 (1) 掌握事件处理的基本原理,理解其用途: (2) 掌握AWT事件模型的工作机制: (3) 掌握事件处理的基本编程模型: (4) 了解GUI界 ...
- Gym101635C Macarons
题目链接:http://codeforces.com/gym/101635/attachments 题目大意: 给出一个 \(N \times M\) 的网格图,请你用 \(1 \times 1\) ...
- Robot Framework(2)- 快速安装
如果你还想从头学起Robot Framework,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1770899.html 安装RF cmd ...
- Spring的bean创建方式ref使用方法
java public class UserServiceImp implements UserService{ private UserDao userDao =null; public void ...
- Istio DestinationRule 目标规则
概念及示例 与VirtualService一样,DestinationRule也是 Istio 流量路由功能的关键部分.您可以将虚拟服务视为将流量如何路由到给定目标地址,然后使用目标规则来配置该目标的 ...
- 使用websocket开发智能聊天机器人
前面我们学习了异步web框架(sanic)和http异步调用库httpx,今天我们学习websocket技术. websocket简介 我们知道HTTP协议是:请求->响应,如果没有响应就一直等 ...