keras-深度学习处理文本数据
深度学习用于自然语言处理是将模式识别应用于单词、句子和段落,这与计算机视觉是将模式识别应用于像素大致相同。深度学习模型不会接收原始文本作为输入,它只能处理数值张量,因此我们必须将文本向量化(vectorize)。下图是主要流程。

one-hot编码是将每个单词与一个唯一的整数索引相关联,然后将这个整数索引 i 转换为长度为N的二进制向量(N是此表大小),这个向量只有第 i 个元素是1,其余都为0。
词嵌入是低维的浮点数向量,是从数据中学习得到的。
one-hot:高维度、稀疏
词嵌入:低维度、密集
这里我们重点介绍词嵌入!编译环境keras、jupyter Notebook
利用Embedding层学习词嵌入
应用场景:IMDB电影评论情感预测任务
1、准备数据(keras内置)
2、将电影评论限制为前10 000个最常见的单词
3、评论长度限制20个单词
4、将输入的整数序列(二维整数张量)转换为嵌入序列(三维浮点数张量),将这个张量展平为二维,最后在上面训练一个Dense层用于分类
# 将一个Embedding层实例化
from keras.layers import Embedding # (最大单词索引+1, 嵌入的维度)
enmbedding_layer = Embedding(1000, 64)
加载数据、准备用于Embedding层
from keras.datasets import imdb
from keras import preprocessing max_features = 10000
maxlen = 20 # 将数据加载为整数列表
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words = max_features) x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=maxlen)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=maxlen)
在IMDB数据上使用Embedding层和分类器
from keras.models import Sequential
from keras.layers import Flatten, Dense model = Sequential() model.add(Embedding(10000, 8, input_length=maxlen)) # 将三维的嵌入张量展平成(samples, maxlen * 8)
model.add(Flatten()) # 在上面添加分类器
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
model.summary() history = model.fit(x_train, y_train, epochs=10,
batch_size = 32,
validation_split=0.2)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 20, 8) 80000
_________________________________________________________________
flatten_1 (Flatten) (None, 160) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 161
=================================================================
Total params: 80,161
Trainable params: 80,161
Non-trainable params: 0
_________________________________________________________________
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
20000/20000 [==============================] - 10s 517us/step - loss: 0.6759 - acc: 0.6050 - val_loss: 0.6398 - val_acc: 0.6814
......
Epoch 10/10
20000/20000 [==============================] - 3s 127us/step - loss: 0.2839 - acc: 0.8860 - val_loss: 0.5303 - val_acc: 0.7466
得到验证精度约为75%,我们仅仅将嵌入序列展开并在上面训练一个Dense层,会导致模型对输入序列中的每个单词处理,而没有考虑单词之间的关系和句子结构。更好的做法是在嵌入序列上添加循环层或一维卷积层,将整个序列作为整体来学习特征。
如果可用的训练数据很少,无法用数据学习到合适的词嵌入,那怎么办? ===> 使用预训练的词嵌入
使用预训练的词嵌入
这次,我们不使用keras内置的已经预先分词的IMDB数据,而是从头开始下载。
1. 下载IMDB数据的原始文本
地址:https://mng.bz/0tIo下载原始IMDB数据集并解压
import os imdb_dir = 'F:/keras-dataset/aclImdb'
train_dir = os.path.join(imdb_dir, 'train') labels = []
texts = [] for label_type in ['neg', 'pos']:
dir_name = os.path.join(train_dir, label_type)
for fname in os.listdir(dir_name):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname), errors='ignore')
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1)
2. 对IMDB原始数据的文本进行分词
预训练的词嵌入对训练数据很少的问题特别有用,因此我们只采取200个样本进行训练
# 对数据进行分词
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
import numpy as np # 在100个单词后截断评论
maxlen = 100 # 在200个样本上进行训练
training_samples = 200 # 在10000个样本上进行验证
validation_samples = 10000 # 只考虑数据集中前10000个最常见的单词
max_words = 10000 tokenizer = Tokenizer(num_words=max_words)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts) word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index)) data = pad_sequences(sequences, maxlen=maxlen) labels = np.asarray(labels)
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape) # 将数据划分为训练集和验证集,但首先要打乱数据
# 因为一开始数据中的样本是排好序的(所有负面评论在前,正面评论在后)
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
x_train = data[:training_samples]
y_train = labels[:training_samples]
x_val = data[training_samples: training_samples + validation_samples]
y_val = labels[training_samples: training_samples + validation_samples]
Found 88583 unique tokens.
Shape of data tensor: (25000, 100)
Shape of label tensor: (25000,)
3. 下载GloVe词嵌入
地址:https://nlp.stanford.edu/projects/glove/ 文件名是glove.6B.zip,里面包含400 000个单词的100维向量。解压文件
对解压文件进行解析,构建一个单词映射为向量表示的索引
# 解析GloVe词嵌入文件
glove_dir = 'F:/keras-dataset' embeddings_index = {} f = open(os.path.join(glove_dir, 'glove.6B.100d.txt'), errors='ignore')
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close() print('Found %s word vectors.' % len(embeddings_index)) # 创建一个可以加载到Embedding层中的嵌入矩阵
# 对于单词索引中索引为i的单词,这个矩阵的元素i就是这个单词对应的 embedding_dim 为向量
embedding_dim = 100
embedding_matrics = np.zeros((max_words, embedding_dim))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if i < max_words:
if embedding_vector is not None:
embedding_matrics[i] = embedding_vector
Found 399913 word vectors.
4. 定义模型
# 模型定义
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, 100, 100) 1000000
_________________________________________________________________
flatten_2 (Flatten) (None, 10000) 0
_________________________________________________________________
dense_2 (Dense) (None, 32) 320032
_________________________________________________________________
dense_3 (Dense) (None, 1) 33
=================================================================
Total params: 1,320,065
Trainable params: 1,320,065
Non-trainable params: 0
6. 在模型中加载GloVe嵌入
Embedding层只有一个权重矩阵,是一个二维的浮点数矩阵,其中每个元素i是索引i相关联的词向量,将准备好的GloVe矩阵加载到Embedding层中,即模型的第一层
# 将预训练的词嵌入加载到Embedding层
model.layers[0].set_weights([embedding_matrics]) # 冻结Embedding层
model.layers[0].trainable = False
7. 训练和评估模型
# 训练模型与评估模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_data=(x_val, y_val)) model.save_weights('pre_trained_glove_model.h5')
Train on 200 samples, validate on 10000 samples
Epoch 1/10
200/200 [==============================] - 1s 4ms/step - loss: 0.9840 - acc: 0.5300 - val_loss: 0.6942 - val_acc: 0.4980
........
Epoch 10/10
200/200 [==============================] - 0s 2ms/step - loss: 0.0598 - acc: 1.0000 - val_loss: 0.8704 - val_acc: 0.5339
8. 绘制结果
# 绘制图像
import matplotlib.pyplot as plt acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend() plt.figure() plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend() plt.show()
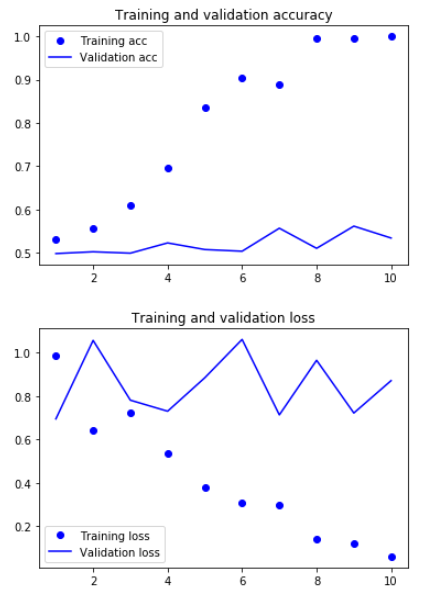
模型很快就开始过拟合,因为训练样本很少,效果不是很好。验证集的精度56%
9. 对测试集数据进行分词,并对数据进行评估模型
# 对测试集数据进行分词
test_dir = os.path.join(imdb_dir, 'test') labels = []
texts = [] for label_type in ['neg', 'pos']:
dir_name = os.path.join(test_dir, label_type)
for fname in sorted(os.listdir(dir_name)):
if fname[-4:] == '.txt':
f = open(os.path.join(dir_name, fname), errors='ignore')
texts.append(f.read())
f.close()
if label_type == 'neg':
labels.append(0)
else:
labels.append(1) sequences = tokenizer.texts_to_sequences(texts)
x_test = pad_sequences(sequences, maxlen=maxlen)
y_test = np.asarray(labels) # 在测试集上评估模型
model.load_weights('pre_trained_glove_model.h5')
model.evaluate(x_test, y_test)
25000/25000 [==============================] - 1s 50us/step
[0.8740278043365478, 0.53072]
测试精度达到53%,效果还可以,因为我们只使用了很少的训练样本
在不使用预训练词嵌入的情况下,训练相同的模型
# 在不使用预训练词嵌入的情况下,训练相同的模型
from keras.models import Sequential
from keras.layers import Embedding, Flatten, Dense model = Sequential()
model.add(Embedding(max_words, embedding_dim, input_length=maxlen))
model.add(Flatten())
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.summary() model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(x_train, y_train,
epochs=10,
batch_size=32,
validation_data=(x_val, y_val))
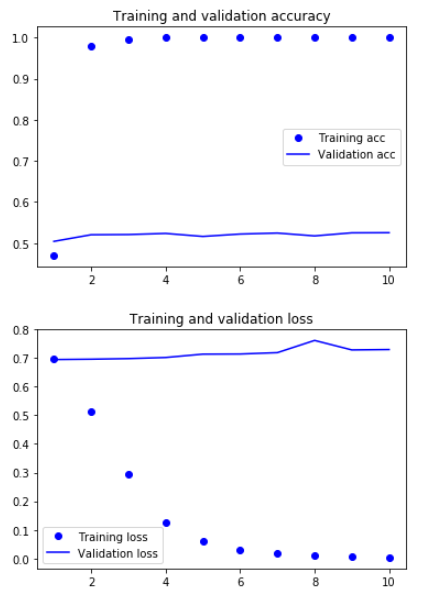
验证集的精度大概52%
keras-深度学习处理文本数据的更多相关文章
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- AI:深度学习用于文本处理
同本文一起发布的另外一篇文章中,提到了 BlueDot 公司,这个公司致力于利用人工智能保护全球人民免受传染病的侵害,在本次疫情还没有引起强烈关注时,就提前一周发出预警,一周的时间,多么宝贵! 他们的 ...
- 【AI in 美团】深度学习在文本领域的应用
背景 近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点.而深度学习技术突飞猛进的发展离不开海量数据的积累.计算能力的提升和算法模型的改进. ...
- 解析基于keras深度学习框架下yolov3的算法
一.前言 由于前一段时间以及实现了基于keras深度学习框架下yolov3的算法,本来想趁着余热将自己的心得体会进行总结,但由于前几天有点事就没有完成计划,现在趁午休时间整理一下. 二.Keras框架 ...
- 2.keras实现-->深度学习用于文本和序列
1.将文本数据预处理为有用的数据表示 将文本分割成单词(token),并将每一个单词转换为一个向量 将文本分割成单字符(token),并将每一个字符转换为一个向量 提取单词或字符的n-gram(tok ...
- Keras深度学习框架安装及快速入门
1.下载安装Keras 如果你是安装的Anaconda组合套件,可以直接在Prompt上执行安装命令:pip install keras 注意:最下面为Successfully...表示安装成功! 2 ...
- win7上安装theano keras深度学习框架
近期在学习深度学习,需要在本机上安装keras框架,好上手.上网查了一些资料,弄了几天今天终于完全搞好了.本次是使用GPU进行加速,使用cpu处理的请查看之前的随笔keras在win7下环境搭建 本机 ...
- TensorFlow深度学习笔记 文本与序列的深度模型
Deep Models for Text and Sequence 转载请注明作者:梦里风林 Github工程地址:https://github.com/ahangchen/GDLnotes 欢迎st ...
- Keras深度学习框架之损失函数
一.损失函数的使用 损失函数[也称目标函数或优化评分函数]是编译模型时所需的两个参数之一. model.compile(loss='mean_squared_error', optimizer='sg ...
随机推荐
- javascript 入门(1)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <meta lang ...
- python3中的nonlocal 与 global
nonlocal 与 global nonlocal翻译是非本地,global翻译是全局,它们都是python3的新特性.如果以类C语言的思维去看这2个关键字,很可能觉得它们差不多.但实际上它们很不一 ...
- 【FreeMarker】【程序开发】数据模型,对象包装
[FreeMarker][程序开发]数据模型,对象包装 分类: Java.FreeMarker2014-10-25 18:49 413人阅读 评论(0) 收藏 举报 FreeMarker 目录(? ...
- 如何利用 githob 上传自己的网站
如何搭建自己的网页是每个学前端伙伴不可缺少的一个过程,特意去看过很多如何搭建的教程,但都看不懂觉得很麻烦, 在慢慢的学习中接触到githob,发现了一个大宝藏(如果一个code都不认识githob 那 ...
- 1、2、2、3、4、5这六个数字,用java写一个main函数,打印出所有不同的排列, 如:512234、212345等. 要求:”4”不能在第三位,”3”与”5”不能相连。
private static String[] mustExistNumber = new String[] { "1", "2", "2" ...
- VulnHub靶场学习_HA: InfinityStones
HA-InfinityStones Vulnhub靶场 下载地址:https://www.vulnhub.com/entry/ha-infinity-stones,366/ 背景: 灭霸认为,如果他杀 ...
- Java 基础增强
jdk与jre 要想深入了解Java必须对JDK的组成, 本文对JDK6里的目录做了基本的介绍,主要还是讲解 了下JDK里的各种可执行程序或工具的用途 Java(TM) 有两个平台 JRE 运行平台, ...
- 区块链 Hyperledger Fabric v1.0.0 环境搭建
前言:最近项目涉及到超级账本,在有些理论知识的基础上,需要整一套环境来. 这是一个特别要注意的事情,笔者之前按照网络上推荐,大部分都是推荐ubuntu系统的,于是下载Ubuntu系统(16.04.5和 ...
- 移动硬盘临时文件太多怎么办,python黑科技帮你解决
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 星安果 PS:如果想了解更多关于python的应用,可以私信我,或者 ...
- B - How Many Equations Can You Find dfs
Now give you an string which only contains 0, 1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9.You are asked to add the sig ...