python爬虫(二) urlparse和urlsplit函数
urlparse和urlsplit函数:
urlparse:
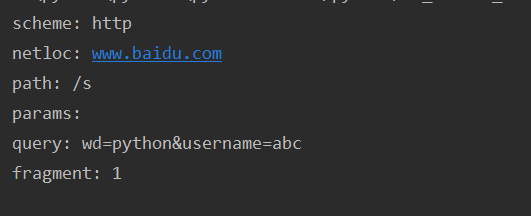
url='http://www.baidu.com/s?wd=python&username=abc#1' result=parse.urlparse(url) print(result)

输入的结果为解析之后的各部分
输出对应的参数:
url='http://www.baidu.com/s?wd=python&username=abc#1' result=parse.urlparse(url) # print(result)
print('scheme:',result.scheme)
print('netloc:',result.netloc)
print('path:',result.path)
print('params:',result.params)
print('query:',result.query)
print('fragment:',result.fragment)
结果就是输入的网址各个部分
urlsplit:
url='http://www.baidu.com/s?wd=python&username=abc#1'
result=parse.urlsplit(url)
print(result)

这个里面没有params这个参数
因为在urlparse中,

在这个网址问好前面加一个分号,分号和问好中间加一个hello

urlparse这个函数的params这个参数就是为了获得分号和问号中间的值
在平时使用中两个函数是一样的。
python爬虫(二) urlparse和urlsplit函数的更多相关文章
- Python爬虫二
常见的反爬手段和解决思路 1)明确反反爬的主要思路 反反爬的主要思路就是尽可能的去模拟浏览器,浏览器在如何操作,代码中就如何去实现;浏览器先请求了地址url1,保留了cookie在本地,之后请求地址u ...
- Python 爬虫二 requests模块
requests模块 Requests模块 get方法请求 整体演示一下: import requests response = requests.get("https://www.baid ...
- Python爬虫(二十一)_Selenium与PhantomJS
本章将介绍使用Selenium和PhantomJS两种工具用来加载动态数据,更多内容请参考:Python学习指南 Selenium Selenium是一个Web的自动化测试工具,最初是为网站自动化测试 ...
- Python爬虫(二十三)_selenium案例:动态模拟页面点击
本篇主要介绍使用selenium模拟点击下一页,更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import unittest from selenium impor ...
- python爬虫(二)--了解deque
队列-deque 有了上面一节的基础.当然你须要全然掌握上一节的全部方法,由于上一节的方法.在以下的教程中 会重复的用到. 假设你没有记住,请你返回上一节. http://blog.csdn.net/ ...
- python爬虫(二)_HTTP的请求和响应
HTTP和HTTPS HTTP(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收HTML页面的方法 HTTPS(HyperText Transfer Prot ...
- Python爬虫(二十四)_selenium案例:执行javascript脚本
本章叫介绍如何使用selenium在浏览器中使用js脚本,更多内容请参考:Python学习指南 隐藏百度图片 #-*- coding:utf-8 -*- #本篇将模拟执行javascript语句 fr ...
- Python爬虫(二十二)_selenium案例:模拟登陆豆瓣
本篇博客主要用于介绍如何使用selenium+phantomJS模拟登陆豆瓣,没有考虑验证码的问题,更多内容,请参考:Python学习指南 #-*- coding:utf-8 -*- from sel ...
- Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据.更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import t ...
随机推荐
- 那些年做过的ctf之加密篇(加强版)
MarkdownPad Document *:first-child { margin-top: 0 !important; } body>*:last-child { margin-botto ...
- Codeforces Round #577 (Div. 2) 题解
比赛链接:https://codeforc.es/contest/1201 A. Important Exam 题意:有\(n\)个人,每个人给出\(m\)个答案,每个答案都有一个分值\(a_i\), ...
- ENS中文文档系列之三 [ ENS常见问题 ]
原文地址:https://ensuser.com/docs/frequently-asked-questions.html更多最新信息,请前往 ENS 中文服务站点:ENSUser 关于 ENS 注册 ...
- itest(爱测试) 4.3.0 发布,开源BUG 跟踪管理 & 敏捷测试管理软件
itest 简介:查看简介 test 开源敏捷测试管理,testOps 践行者.可按测试包分配测试用例执行,也可建测试迭代(含任务,测试包,BUG)来组织测试工作,也有测试环境管理,还有很常用的测试度 ...
- Typora自动生成标题编号
1.要实现的效果 按照markdown语法输入 # 一级标题后,自动生成前面的编号 2.配置方法 2.1.进入目录 2.2.创建文件 2.3.编辑文件 base.user.css /** initi ...
- 关于iOS appIcon launchImage 尺寸
https://developer.apple.com/library/ios/documentation/UserExperience/Conceptual/MobileHIG/IconMatrix ...
- app内嵌 h5页面 再滑动的时候 触发击穿底下的一些touchstart事件
我们的目的是再滑动的时候 不要触发到touchstart事件. // 再滑动的时候无法点开视频 var is_scroll_start,is_scroll_end; $(window).on({ 't ...
- mysql-8.0.18-winx64 环境变量的配置
1. 鼠标右击 此电脑 -->属性 如图:进行步骤 1->2->3 接下来就可以使用命令mysql -u root -p登录mysql了 启动mysql的命令为net ...
- C语言:将字符串中的字符逆序输出,但不改变字符串中的内容。-在main函数中将多次调用fun函数,每调用一次,输出链表尾部结点中的数据,并释放该结点,使链表缩短。
//将字符串中的字符逆序输出,但不改变字符串中的内容. #include <stdio.h> /************found************/ void fun (char ...
- 计算机二级-C语言-程序填空题-190117记录-对文件的处理,复制两个文件,往新文件中写入数据。
//给定程序的功能是,调用函数fun将指定源文件中的内容赋值到指定目标文件中,复制成功时函数返回1,失败时返回0,把复制的内容输出到终端屏幕.主函数中源文件名放在变量sfname中,目标文件名放在变量 ...