TF Notes (5), GRU in Tensorflow
小筆記. Tensorflow 裡實作的 GRU 跟 Colah’s blog 描述的 GRU 有些不太一樣. 所以做了一下 TF 的 GRU 結構. 圖比較醜, 我盡力了… XD
TF 的 GRU 結構
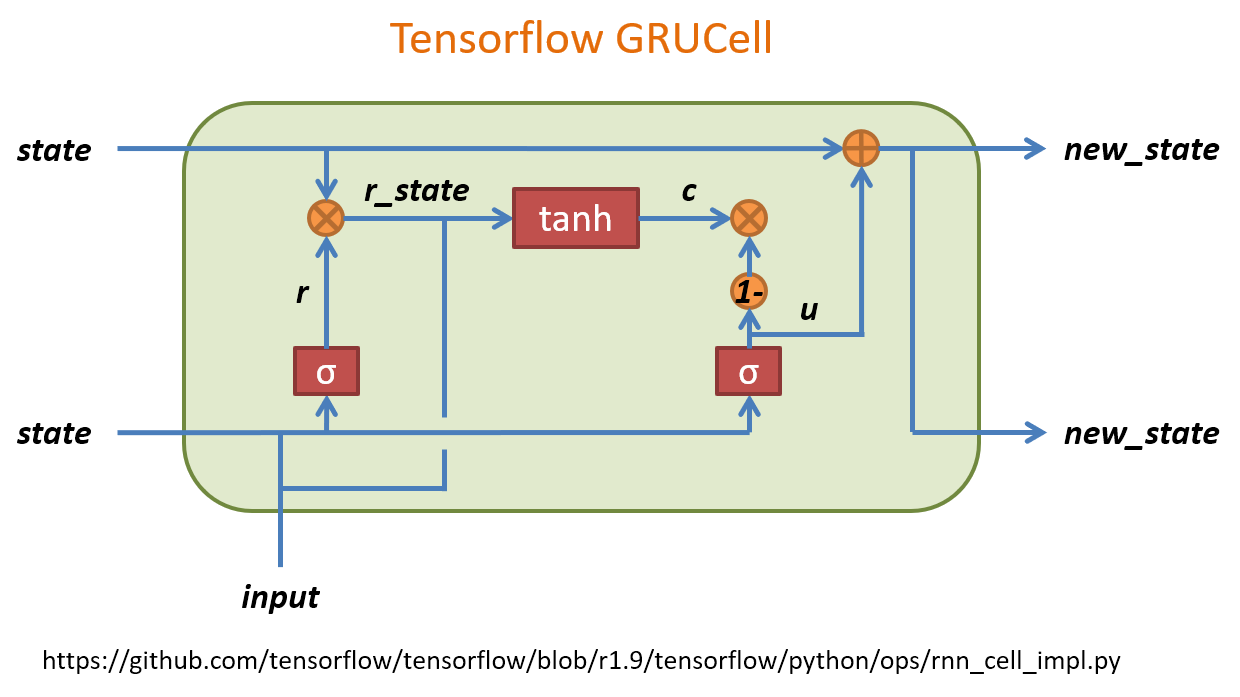
u 可以想成是原來 LSTM 的 forget gate, 而 c 表示要在 memory cell 中需要記住的內容. 這個要記住的內容簡單講是用一個 gate (r) 來控制之前的 state 有多少比例保留, concate input 後做 activation transform 後得到. 可以對照下面 tf source codes.
TF Source Codes
|
|
TF Notes (5), GRU in Tensorflow的更多相关文章
- 启动Tensorboard时发生错误:class BeholderHook(tf.estimator.SessionRunHook): AttributeError: module 'tensorflow.python.estimator.estimator_lib' has no attribute 'SessionRunHook'
报错:class BeholderHook(tf.estimator.SessionRunHook):AttributeError: module 'tensorflow.python.estimat ...
- 三步理解--门控循环单元(GRU),TensorFlow实现
1. 什么是GRU 在循环神经⽹络中的梯度计算⽅法中,我们发现,当时间步数较⼤或者时间步较小时,循环神经⽹络的梯度较容易出现衰减或爆炸.虽然裁剪梯度可以应对梯度爆炸,但⽆法解决梯度衰减的问题.通常由于 ...
- 第二十一节,使用TensorFlow实现LSTM和GRU网络
本节主要介绍在TensorFlow中实现LSTM以及GRU网络. 一 LSTM网络 Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息 ...
- Tensorflow滑动平均模型tf.train.ExponentialMovingAverage解析
觉得有用的话,欢迎一起讨论相互学习~Follow Me 移动平均法相关知识 移动平均法又称滑动平均法.滑动平均模型法(Moving average,MA) 什么是移动平均法 移动平均法是用一组最近的实 ...
- Tensorflow常用的函数:tf.cast
1.tf.cast(x,dtype,name) 此函数的目的是为了将x数据,准换为dtype所表示的类型,例如tf.float32,tf.bool,tf.uint8等 example: import ...
- TensorFlow tf.app&tf.app.flags用法介绍
TensorFlow tf.app&tf.app.flags用法介绍 TensorFlow tf.app argparse tf.app.flags 下面介绍 tf.app.flags.FL ...
- 11 tensorflow在tf.while_loop循环(非一般循环)中使用操纵变量该怎么做
代码(操纵全局变量) xiaojie=1 i=tf.constant(0,dtype=tf.int32) batch_len=tf.constant(10,dtype=tf.int32) loop_c ...
- Tensorflow函数——tf.placeholder()函数
tf.placeholder()函数 Tensorflow中的palceholder,中文翻译为占位符,什么意思呢? 在Tensoflow2.0以前,还是静态图的设计思想,整个设计理念是计算流图,在编 ...
- tensorflow 笔记13:了解机器翻译,google NMT,Attention
一.关于Attention,关于NMT 未完待续... 以google 的 nmt 代码引入 探讨下端到端: 项目地址:https://github.com/tensorflow/nmt 机器翻译算是 ...
随机推荐
- 9.windows-oracle实战第九课--plsql
一.oracle的pl/sql的概念 pl/sql是oracle在标准的sql语言上的扩展,不仅允许嵌入sql,还允许定义变量和常量,允许使用条件语句和循环语句,允许使用例外处理各种错误,这样使得它的 ...
- C#匿名委托,匿名函数,lambda表达式
一.类型.变量.实例之间的关系. 类型>变量>实例 类型可以创建变量,实体类可以创建实例,实例可以存储在变量里. 二.委托使用过程: 1.定义委托(写好签名): 2.创建委托变量: 3.给 ...
- 发布订阅--DBMS "无法作为数据库主体执行,因为主体“dbo”不存在、无法模拟这种..........”
解决方案: 新附加的数据库需要设置所有者才能建立数据库关系图.供参考的操作步骤如下: 选择“AdventureWorks2012LT”,右键,选择“属性”,选择“文件”页,点击“所有者”右侧按钮,点击 ...
- MySQL5.7源码安装
一.获取MySQL5.7.20源码安装包,并上传至服务器 MySQL官网下载地址:https://dev.mysql.com/downloads/mysql/ 下载版本:mysql-boost-5 ...
- 计量经济与时间序列_ADF单位根检验步骤
1 ADF检验也叫扩展的迪克富勒检验,主要作用是检测序列的平稳性,也是最常用检测序列平稳性的检验方法. 2 何为:平稳性?单位根?(略),见这部分随便的其他内容有讲解.是建模对数据的先决条件. 3 A ...
- tap点击一次,内部程序执行两次,多次
调试过程发现,使用 $(document).on('tap', '.children2', function () { //内部程序 }) 点击children2的时候,程序在里面执行了两次.百度得到 ...
- D - Project Presentation(DFS序+倍增LCA)
You are given a tree that represents a hierarchy in a company, where the parent of node u is their d ...
- 关于Java杂项知识总结
JVM内存结构 JVM在运行时把从操作系统申请到的内存分为若干区域,主要有栈.堆和方法区,方便Java程序使用 堆内存 使用new关键字创建出来的对象都存储在堆内存中 方法区 被加载的类的信息存储在方 ...
- python3下scrapy爬虫(第十二卷:解决scrapy数据存储大量数据时阻塞问题)
之前我们使用scrapy爬取数据,用的存储方式是直接引入PYMYSQL,或者MYSQLDB,案例中数据量并不大,这种数据存储方式属于同步过程,也就是上一条语句执行完才能执行下一条语句,当数据量变大时, ...
- [LC] 1099. Two Sum Less Than K
Given an array A of integers and integer K, return the maximum S such that there exists i < j wit ...