【转】MySQL的Replace into 与Insert into on duplicate key update真正的不同之处
1 Replace into ... 1.1 录入原始数据 mysql> use test; Database changed mysql>
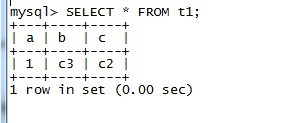
mysql> CREATE TABLE t1 SELECT 1 AS a, 'c3' AS b, 'c2' AS c; ALTER TABLE t1 CHANGE a a INT PRIMARY KEY AUTO_INCREMENT ; Query OK, 1 row affected (0.03 sec) Records: 1 Duplicates: 0 Warnings: 0
mysql> INSERT INTO t1 SELECT 2,'2', '3'; Query OK, 1 row affected (0.01 sec) Records: 1 Duplicates: 0 Warnings: 0 mysql> insert into t1(b,c) select 'r2','r3'; Query OK, 1 row affected (0.08 sec) Records: 1 Duplicates: 0 Warnings: 0
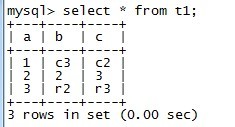
1.2 开始replace操作 mysql> REPLACE INTO t1(a,b) VALUES(2,'a') ; Query OK, 2 rows affected (0.06 sec)
【】看到这里,replace,看到这里,a=2的记录中c字段是空串了, 所以当与key冲突时,replace覆盖相关字段,其它字段填充默认值,可以理解为删除重复key的记录,新插入一条记录,一个delete原有记录再insert的操作。
1.3 但是不知道对主键的auto_increment有无影响,接下来测试一下:
mysql> insert into t1(b,c) select 'r4','r5';
Query OK, 1 row affected (0.05 sec)
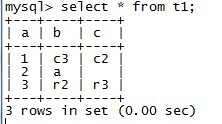
Records: 1 Duplicates: 0 Warnings: 0 mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r2 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec)
【】从这里可以看出,新的自增不是从4开始,而是从5开始,就表示一个repalce操作,主键中的auto_increment会累加1. 所以总结如下: Replace:
当没有key时,replace相当于普通的insert. 当有key时,可以理解为删除重复key的记录,在保持key不变的情况下,delete原有记录,再insert新的记录,新纪录的值只会录入replace语句中字段的值,其余没有在replace语句中的字段,会自动填充默认值。
2.1 ok,再来看Insert into ..... on duplicate key update,
mysql> insert into t1(a,b) select '3','r5' on duplicate key update b='r5';
Query OK, 2 rows affected, 1 warning (0.19 sec)
Records: 1 Duplicates: 1 Warnings: 1 mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec)
【】a=5时候,原来的c值还在,这表示当key有时,只执行后面的udate操作语句.
2.2 再检查auto_increment情况。
mysql> insert into t1(a,b) select '3','r5' on duplicate key update b='r5';
Query OK, 2 rows affected, 1 warning (0.19 sec)
Records: 1 Duplicates: 1 Warnings: 1 mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
+---+----+----+
4 rows in set (0.00 sec) mysql> insert into t1(b,c) select 'r6','r7';
Query OK, 1 row affected (0.19 sec)
Records: 1 Duplicates: 0 Warnings: 0 mysql> select * from t1;
+---+----+----+
| a | b | c |
+---+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | r5 | r3 |
| 5 | r4 | r5 |
| 7 | r6 | r7 |
+---+----+----+
5 rows in set (0.00 sec)
【】从这里可以看出,新的自增不是从6开始,而是从7开始,就表示一个Insert .. on deplicate udate操作,主键中的auto_increment也跟replace一样累加1.
2.3 再看下当没有key的时候,insert .. on deplicate update的情况
mysql> insert into t1(a,b,c) select '33','r5','c3' on duplicate key update b='r5';
Query OK, 1 row affected, 1 warning (0.23 sec)
Records: 1 Duplicates: 0 Warnings: 1 mysql> select * from t1;
+----+----+----+
| a | b | c |
+----+----+----+
| 1 | c3 | c2 |
| 2 | a | |
| 3 | b5 | r3 |
| 5 | r4 | r5 |
| 7 | r6 | r7 |
| 9 | s6 | s7 |
| 33 | r5 | c3 |
+----+----+----+
7 rows in set (0.00 sec)
看a=33的记录,ok,全部录入了。
3 总结从上面的测试结果看出,相同之处: (1),没有key的时候,replace与insert .. on deplicate udpate相同。 (2),有key的时候,都保留主键值,并且auto_increment自动+1 不同之处:有key的时候,replace是delete老记录,而录入新的记录,所以原有的所有记录会被清除,这个时候,如果replace语句的字段不全的话,有些原有的比如例子中c字段的值会被自动填充为默认值。 而insert .. deplicate update则只执行update标记之后的sql,从表象上来看相当于一个简单的update语句。 但是实际上,根据我推测,如果是简单的update语句,auto_increment不会+1,应该也是先delete,再insert的操作,只是在insert的过程中保留除update后面字段以外的所有字段的值。
所以两者的区别只有一个,insert .. on deplicate udpate保留了所有字段的旧值,再覆盖然后一起insert进去,而replace没有保留旧值,直接删除再insert新值。 从底层执行效率上来讲,replace要比insert .. on deplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。
【转】MySQL的Replace into 与Insert into on duplicate key update真正的不同之处的更多相关文章
- mysql 中 replace into 与 insert into on duplicate key update 的使用和不同点
replace into和insert into on duplicate key update都是为了解决我们平时的一个问题 就是如果数据库中存在了该条记录,就更新记录中的数据,没有,则添加记录. ...
- Replace into 与Insert into on duplicate key update的区别
前提条件:除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用这2条语句没有意义.该语句会与INSERT相同 1. Replace into (1) 添加相同的主键 操作前 ...
- MySql中4种批量更新的方法update table2,table1,批量更新用insert into ...on duplicate key update, 慎用replace into.
mysql 批量更新记录 MySql中4种批量更新的方法最近在完成MySql项目集成的情况下,需要增加批量更新的功能,根据网上的资料整理了一下,很好用,都测试过,可以直接使用. mysql 批量更新共 ...
- insert into on duplicate key update
问题 有一个表,建表语句如下: CREATE TABLE `tbl_host` ( `id` bigint(64) NOT NULL AUTO_INCREMENT, `ip` varchar(255) ...
- SQL语句实现不存在即插入,存在则increase某字段的功能insert into … on duplicate key update
前提条件:必须是唯一主键: CREATE UNIQUE INDEX idx_vote_object ON test_customers_vote (`vote_object`, `vote_objec ...
- insert into ... on duplicate key update 与 replace 区别
on duplicate key update:针对主健与唯一健,当插入值中的主健值与表中的主健值,若相同的主健值,就更新on duplicate key update 后面的指定的字段值,若没有相同 ...
- (转载)[MySQL技巧]INSERT INTO… ON DUPLICATE KEY UPDATE
(转载)http://blog.zol.com.cn/2299/article_2298921.html MySQL 自4.1版以后开始支持INSERT … ON DUPLICATE KEY UPDA ...
- INSERT 中ON DUPLICATE KEY UPDATE的使用
如果您指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则执行旧行UPDATE.例如,如果列a被定义为UNIQUE,并 ...
- mysql 插入更新在一条sql ON DUPLICATE KEY UPDATE
有时候需要进行数据操作的,如果有数据则更新数据, 没有数据则插入. 以往的做法是先查询,再根据查询结果进行判断,执行插入或更新操作 其实 有一种 ON DUPLICATE KEY UPDATE 语法, ...
随机推荐
- jquery 之 Deferred 使用与实现
观察者模式是开发中经常使用的模式,这个模式由两个主要部分组成:主题和观察者.通过观察者模式,实现主题和观察者的解耦. 主题负责发布内容,而观察者则接收主题发布的内容.通常情况下,观察者都是多个,所以, ...
- Struts2学习笔记 - Action篇<配置文件中使用通配符>
有三种方法可以使一个Action处理多个请求 动态方法调用DMI 定义逻辑Acton 在配置文件中使用通配符 这里就说一下在配置文件中使用通配符,这里的关键就是struts.xml配置文件,在最简单的 ...
- bower一个强大的前端依赖包管理工具
在介绍之前,你必须的知道bower是基于nodejs开发的,所以你首先必须得有个nodejs环境,至于这么安装nodejs网上一大堆教程,对了使用bower还需要安装git,这里就不多说了. #### ...
- 【转】SQL 操作类
using System; using System.Collections.Generic; using System.Text; using System.Data; using System.D ...
- Aspect Oriented Programming
AOP(Aspect Oriented Programming),面向切面编程(也叫面向方面)是目前软件开发中的一个热点.利用AOP可以对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度 ...
- MYSQL线程池总结(一)
线程池是Mysql5.6的一个核心功能,对于服务器应用而言,无论是web应用服务还是DB服务,高并发请求始终是一个绕不开的话题.当有大量请求并发访问时,一定伴随着资源的不断创建和释放,导致资源利用率低 ...
- 检查点(Checkpoint)过程如何处理未提交的事务
每次我讲解SQL Server之前,我都会先简单谈下当我们执行查询时,在SQL Server内部发生了什么.执行一个SELECT语句非常简单,但是执行DML语句更加复杂,因为SQL Server要修改 ...
- UWP开发入门(二十一)——保持Ui线程处于响应状态
GUI的程序有时候会因为等待一个耗时操作完成,导致界面卡死.本篇我们就UWP开发中可能遇到的情况,来讨论如何优化处理. 假设当前存在点击按钮跳转页面的操作,通过按钮打开的新页面,在初始化过程中存在一些 ...
- VS2012连接到OSC@Git
osc终于全面开放git库了,这是我一直期待的事,也是促使我从CSDN转回OSC社区的重要原因之一.而这次我来教大家如何用osc@git来进行简单的版本控制.对于git,我自身也是近几周才开始学习,有 ...
- Entity Framework想说爱你不容易,这么多的报错,这么多的限制,该如何解决?
首先看一下采用MODEL FIRST的方式设计的实体模型对象关系图: 注意:EntityOne中有导航属性:EntityTwo 在如下代码中的几种情况进行新增操作,均会报错,新增都不会成功: stat ...