Python基础篇【第6篇】: Python模块subprocess
subprocess
Python中可以执行shell命令的相关模块和函数有:
- os.system
- os.spawn*
- os.popen* --废弃
- popen2.* --废弃
- commands.* --废弃,3.x中被移除
import commands
result = commands.getoutput('cmd')
result = commands.getstatus('cmd')
result = commands.getstatusoutput('cmd')
随着Python版本的更新,过多的模块引起代码的复杂与冗余,因此Python新引入了一个模块subprocess,将以上几个模块中的功能集中到它当中,以后我们只需import这一个即可。
subprocess的目的就是启动一个新的进程并且与之通信。
1. call
父进程等待子进程执行命令,返回子进程执行命令的状态码,如果出现错误,不进行报错
【这里说的返回执行命令的状态码的意思是:如果我们通过一个变量 res = subprocess.call(['dir',shell=True]) 获取的执行结果,我们能获取到的是子进程执行命令执行结果的状态码,即res=0/1 执行成功或者不成功,并不代表说看不到执行结果,在Python的console界面中我们是能够看到命令结果的,只是获取不到。想获取执行的返回结果,请看check_output。】
【不进行报错解释:如果我们执行的命令在执行时,操作系统不识别,系统会返回一个错误,如:abc命令不存在,这个结果会在console界面中显示出来,但是我们的Python解释器不会提示任何信息,如果想让Python解释器也进行报错,请看check_call】
#!/usr/bin/env python
# -*- coding:utf-8 -*- import subprocess print "################## subprocess.call ###############"
print u"call方法调用系统命令进行执行,如果出错不报错"
subprocess.call(['dir'],shell=True)
注:shell默认为False,在Linux下,shell=False时, Popen调用os.execvp()执行args指定的程序;shell=True时,如果args是字符串,Popen直接调用系统的Shell来执行args指定的程序,如果args是一个序列,则args的第一项是定义程序命令字符串,其它项是调用系统Shell时的附加参数。
在Windows下,不论shell的值如何,Popen调用CreateProcess()执行args指定的外部程序。如果args是一个序列,则先用list2cmdline()转化为字符串,但需要注意的是,并不是MS Windows下所有的程序都可以用list2cmdline来转化为命令行字符串。在windows下,调用脚本时要写上shell=True。
返回结果:
###### subprocess.call #######
call方法调用系统命令进行执行,如果出错不报错 D:\Program\Python 的目录 2016/01/27 11:51 1,069 subprocessDemo.py
1 个文件 1,228 字节
2. check_call
父进程等待子进程执行命令,返回执行命令的状态码,如果出现错误,进行报错【如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含有returncode属性,可用try…except…来检查】
#!/usr/bin/env python
# -*- coding:utf-8 -*- import subprocess print "2. ################## subprocess.check_call ##########"
print u"check_call与call命令相同,区别是如果出错会报错"
subprocess.check_call(['dir'],shell=True)
subprocess.check_call(['abc'],shell=True)
print u"call方法与check_call方法都知识执行并打印命令到输出终端,但是获取不到,如果想获取到结果使用check_output"
返回结果
2. ################## subprocess.check_call ##########
check_call与call命令相同,区别是如果出错会报错
驱动器 D 中的卷没有标签。
卷的序列号是 C6A1-5AD3 D:\Program\Python 的目录 2016/01/27 13:05 <DIR> .
2016/01/27 13:05 <DIR> ..
2016/01/27 10:44 <DIR> .idea
2016/01/27 11:23 159 log_analyse.py
2016/01/27 13:05 1,329 subprocessDemo.py
2 个文件 1,488 字节
3 个目录 26,335,281,152 可用字节
'abc' 不是内部或外部命令,也不是可运行的程序或批处理文件。 这里是系统执行命令返回的系统报错
Traceback (most recent call last): 这里是Python解释器返回的报错
File "D:/Program/Python/subprocessDemo.py", line 19, in <module>
subprocess.check_call(['abc'],shell=True)
File "C:\Python27\lib\subprocess.py", line 540, in check_call
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command '['abc']' returned non-zero exit status 1
3. check_output
父进程等待子进程执行命令,返回子进程向标准输出发送输出运行结果,检查退出信息,如果returncode不为0,则举出错误subprocess.CalledProcessError,该对象包含有returncode属性和output属性,output属性为标准输出的输出结果,可用try…except…来检查。
#!/usr/bin/env python
# -*- coding:utf-8 -*- import subprocess print "3. ################## subprocess.check_output ##############"
res1 = subprocess.call(['dir'],shell=True)
res2 = subprocess.check_call(['dir'],shell=True)
res3 = subprocess.check_output(['dir'],shell=True)
print u"call结果:",res1
print u"check_call结果:",res2
print u"check_output结果:\n",res3
返回结果:
3. ################## subprocess.output ##############
驱动器 D 中的卷没有标签。
卷的序列号是 C6A1-5AD3 D:\Program\Python 的目录 2016/01/27 13:14 <DIR> .
2016/01/27 13:14 <DIR> ..
2016/01/27 10:44 <DIR> .idea
2016/01/27 11:23 159 log_analyse.py
2016/01/27 13:14 1,324 subprocessDemo.py
2 个文件 1,483 字节
3 个目录 26,334,232,576 可用字节
驱动器 D 中的卷没有标签。
卷的序列号是 C6A1-5AD3 D:\Program\Python 的目录 2016/01/27 13:14 <DIR> .
2016/01/27 13:14 <DIR> ..
2016/01/27 10:44 <DIR> .idea
2016/01/27 11:23 159 log_analyse.py
2016/01/27 13:14 1,324 subprocessDemo.py
2 个文件 1,483 字节
3 个目录 26,334,232,576 可用字节
call结果: 0
check_call结果: 0
check_output结果:
驱动器 D 中的卷没有标签。
卷的序列号是 C6A1-5AD3 D:\Program\Python 的目录 2016/01/27 13:14 <DIR> .
2016/01/27 13:14 <DIR> ..
2016/01/27 10:44 <DIR> .idea
2016/01/27 11:23 159 log_analyse.py
2016/01/27 13:14 1,324 subprocessDemo.py
2 个文件 1,483 字节
3 个目录 26,334,232,576 可用字节
可见,call/check_call 返回值均是命令的执行状态码,而check_output返回值是命令的执行结果。
如果在执行相关命令时,命令后带有参数,将程序名(即命令)和所带的参数一起放在一个列表中传递给相关犯法即可,例如:
>>> import subprocess
>>> retcode = subprocess.call(["ls", "-l"])
>>> print retcode
0
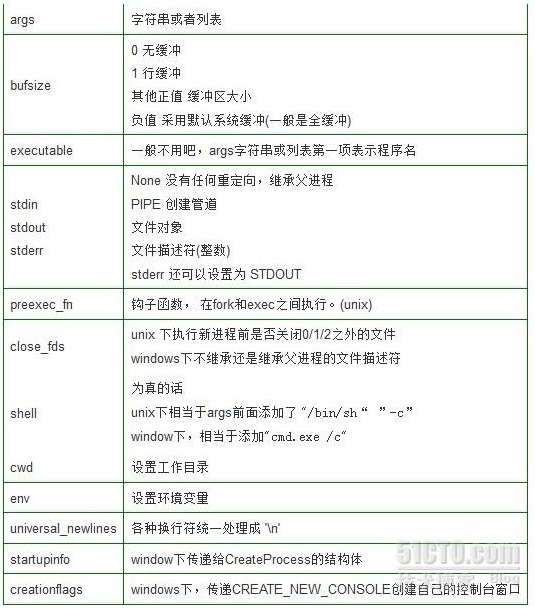
4. Popen
实际上,subprocess模块中只定义了一个类: Popen。上面的几个函数都是基于Popen()的封装(wrapper)。从Python2.4开始使用Popen来创建进程,用于连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值。这些封装的目的在于让我们容易使用子进程。当我们想要更个性化我们的需求的时候,就要转向Popen类,该类生成的对象用来代表子进程。
构造函数如下:
subprocess.Popen(args, bufsize=0, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=False, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0)
与上面的封装不同,Popen对象创建后,主程序不会自动等待子进程完成。我们必须调用对象的wait()方法,父进程才会等待 (也就是阻塞block)。
a) 不等待的子进程
#!/usr/bin/env python
import subprocess child = subprocess.Popen(['ping','-c','','www.baidu.com'])
print 'hello'
执行结果:
[root@localhost script]# python sub.py
hello
[root@localhost script]# PING www.a.shifen.com (61.135.169.125) 56(84) bytes of data.
64 bytes from 61.135.169.125: icmp_seq=1 ttl=55 time=2.04 ms
64 bytes from 61.135.169.125: icmp_seq=2 ttl=55 time=1.58 ms
64 bytes from 61.135.169.125: icmp_seq=3 ttl=55 time=2.22 ms
64 bytes from 61.135.169.125: icmp_seq=4 ttl=55 time=2.13 ms --- www.a.shifen.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3008ms
rtt min/avg/max/mdev = 1.580/1.995/2.220/0.251 ms
可以看出,Python并没有等到child子进程执行的Popen操作完成就执行了print操作。
b) 添加子进程等待
#!/usr/bin/env python
import subprocess child = subprocess.Popen(['ping','-c','','www.baidu.com']) #创建一个子进程,进程名为child,执行操作ping -c 4 www.baidu.com
child.wait() #子进程等待
print 'hello'
执行结果:
[root@localhost script]# python sub.py
PING www.a.shifen.com (61.135.169.125) 56(84) bytes of data.
64 bytes from 61.135.169.125: icmp_seq=1 ttl=55 time=1.82 ms
64 bytes from 61.135.169.125: icmp_seq=2 ttl=55 time=1.65 ms
64 bytes from 61.135.169.125: icmp_seq=3 ttl=55 time=1.99 ms
64 bytes from 61.135.169.125: icmp_seq=4 ttl=55 time=2.08 ms --- www.a.shifen.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3009ms
rtt min/avg/max/mdev = 1.656/1.889/2.082/0.169 ms
hello
看出Python执行print操作是在child子进程操作完成以后才进行的。
此外,你还可以在父进程中对子进程进行其它操作,比如我们上面例子中的child对象:
child.poll() # 检查子进程状态
child.kill() # 终止子进程
child.send_signal() # 向子进程发送信号
child.terminate() # 终止子进程
ps: 子进程的PID存储在child.pid
子进程文本流控制
子进程的标准输入、标准输出和标准错误如下属性分别表示:
child.stdin | child.stdout | child.stderr
我们还可以在Popen()建立子进程的时候改变标准输入、标准输出和标准错误,并可以利用subprocess.PIPE将多个子进程的输入和输出连接在一起,构成管道(pipe),如下2个例子:
例1
#!/usr/bin/env python import subprocess child = subprocess.Popen(['ls','-l'],stdout=subprocess.PIPE) #将标准输出定向输出到subprocess.PIPE
print child.stdout.read() #使用 child.communicate() 也可
输出结果:
[root@localhost script]# python sub.py
total 12-rw-r--r--. 1 root root 36 Jan 23 07:38 analyse.sh
-rw-r--r--. 1 root root 446 Jan 25 19:35 sub.py
例2
#!/usr/bin/env python
import subprocess child1 = subprocess.Popen(['cat','/etc/passwd'],stdout=subprocess.PIPE)
child2 = subprocess.Popen(['grep','root'],stdin=child1.stdout,stdout=subprocess.PIPE) print child2.communicate()
输出结果为
('root:x:0:0:root:/root:/bin/bash\n, None)
subprocess.PIPE实际上为文本流提供一个缓存区。child1的stdout将文本输出到缓存区,随后child2的stdin从该PIPE中将文本读取走。child2的输出文本也被存放在PIPE中,直到communicate()方法从PIPE中读取出PIPE中的文本。
注意:communicate()是Popen对象的一个方法,该方法会阻塞父进程,直到子进程完成
子进程命令解释
在上面的例子中我们创建子进程时,全部是调用Python进行解释,但Python并没有将所有命令全部解释,当Python不能进行解释时,就绪要调用系统来进行执行。
#!/usr/bin/env python import subprocess subprocess.Popen(['ls','-l']) subprocess.Popen(['ifconfig|grep 127.0.0.1'],shell=True)
结果
>>> subprocess.Popen(['ifconfig|grep 127.0.0.1'],shell=True)
<subprocess.Popen object at 0x7f25eb0c1350>
>>> inet addr:127.0.0.1 Mask:255.0.0.0
Python基础篇【第6篇】: Python模块subprocess的更多相关文章
- python基础系列教程——Python3.x标准模块库目录
python基础系列教程——Python3.x标准模块库目录 文本 string:通用字符串操作 re:正则表达式操作 difflib:差异计算工具 textwrap:文本填充 unicodedata ...
- Python基础之【第一篇】
Python简介: python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语 ...
- Python 基础【第八篇】变量
1.变量定义: 给数据进行命名,数据的名字就叫做变量 2.变量格式: [变量名] = [值] 注:变量名命名需要满足下面两条准则 准则一:标示符开头不能为数字.不能包含空格.特殊字符准则二:标示符不能 ...
- python基础【第四篇】
python第二节 1.while循环 Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务.基本形式为: while 条件: 循环体 ...
- Python基础【day01】:初始模块(五)
本节内容 1.标准库 1.sys 2.os 2.第三方库 1.for mac 2.for linux Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的P ...
- python基础之面向过程编程,模块
面向过程编程 面向过程的核心是过程,指的是解决问题的步骤,即先干什么再干什么,就好像设计一条流水线. 优点:复杂的问题流程化,进而简单化 缺点:可扩展性差,修改流水线的任意一个阶段,都会牵一发而动全身 ...
- Python基础入门(8)- Python模块和包
1.包与模块的定义与导入 1.1.什么是python的包与模块 包就是文件夹,包中还可以有包,也就是子文件夹 一个个python文件模块 1.2.包的身份证 __init__.py是每一个python ...
- Python基础【day01】:python介绍发展史(一)
本节内容 Python介绍 发展史 Python 2 or 3? 一. Python介绍 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- 『Python基础』第2节: Python简介及入门
一. Python介绍 Python是一门高级计算机程序设计语言,1989年,荷兰的Guido von Rossum创造了它.Guido是是一个牛人,1982年,他从阿姆斯特丹大学获得了数学和计算机硕 ...
- (Python基础教程之十三)Python中使用httplib2 – HTTP GET和POST示例
Python基础教程 在SublimeEditor中配置Python环境 Python代码中添加注释 Python中的变量的使用 Python中的数据类型 Python中的关键字 Python字符串操 ...
随机推荐
- AIX上通过IPSEC进行IP包过滤
AIX上的IPSEC 在AIX可以通过以下步骤打开IP Security smitty ipsec4 --> Start/Stop IP Security --> Start IP Sec ...
- SQL Server 阻止了对组件 'Ad Hoc Distributed Queries' 的 STATEMENT 'OpenRowset/OpenDatasource' 的访问
消息 15281,级别 16,状态 1,第 2 行SQL Server 阻止了对组件 'Ad Hoc Distributed Queries' 的 STATEMENT 'OpenRowset/Open ...
- Windows 下安装cryptography-1.6
由于proxy限制不能使用pip install cryptography命令安装cryptography,所以安装这个python库折腾了一天多的时间,差点就怀疑人生了,好在柳暗花明,惊喜出现了.下 ...
- c数据结构 顺序表和链表 相关操作
编译器:vs2013 内容: #include "stdafx.h"#include<stdio.h>#include<malloc.h>#include& ...
- TYVJ 1117 BFS
无限WA..参考了一下题解和同学写的....... 可以在bfs的基础上改一下.. 读入的时候平地权值是2 草地是0 bfs的时候如果搜到的是平地,那么直接加入,如果搜到的是草地,那么记录是草地. 从 ...
- 让xterm更舒服的设置
转自:http://codespider.is-programmer.com/posts/25247.html X11相关的配置位于/etc/X11下. xterm的配置是/etc/X11/app-d ...
- 【WEB前端】使用百度ECharts,绘制项目质量报表
一.下载ECharts的js库 下载地址:http://echarts.baidu.com/download.html 由于我们对体积无要求,所以我们采用了完整版本,功能齐全,在项目中,我们只需要像普 ...
- System.DateUtils 2. IsInLeapYear 判断是否是闰年
编译版本:Delphi XE7 function IsInLeapYear(const AValue: TDateTime): Boolean; implementation // 判断是否是闰年 f ...
- 如何分析解决Android ANR
来自: http://blog.csdn.net/tjy1985/article/details/6777346 http://blog.csdn.net/tjy1985/article/detail ...
- Makefile经典教程(掌握这些足够)
makefile很重要 什么是makefile?或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了这个工作,但我觉得要作一个好的和professional的程序员 ...