Win7+Eclipse+Hadoop2.6.4开发环境搭建
Hadoop开发环境搭建
感谢参考网站:http://www.cnblogs.com/huligong1234/p/4137133.html
一、软件准备
JDK:jdk-7u80-windows-x64.exe
http://www.oracle.com/technetwork/java/javase/archive-139210.html
Eclipse:eclipse-jee-mars-2-win32-x86_64.zip
http://www.eclipse.org/downloads/
Hadoop:hadoop-2.6.4.tar.gz
Hadoop-Src:hadoop-2.6.4-src.tar.gz
http://hadoop.apache.org/releases.html
Ant:apache-ant-1.9.6-bin.zip
http://ant.apache.org/bindownload.cgi
Hadoop-Common:hadoop2.6(x64)V0.2.zip (2.4以后)、(hadoop-common-2.2.0-bin-master.zip)
2.2:https://github.com/srccodes/hadoop-common-2.2.0-bin
2.6:http://download.csdn.net/detail/myamor/8393459
Hadoop-eclipse-plugin:hadoop-eclipse-plugin-2.6.0.jar
https://github.com/winghc/hadoop2x-eclipse-plugin
二、搭建环境
1. 安装JDK
执行“jdk-7u80-windows-x64.exe”,步骤选择默认下一步即可。
2. 配置JDK、Ant、Hadoop环境变量
解压hadoop-2.6.4.tar.gz、apache-ant-1.9.6-bin.zip、hadoop2.6(x64)V0.2.zip、hadoop-2.6.4-src.tar.gz到本地磁盘,位置任意。
配置系统环境变量JAVA_HOME、ANT_HOME、HADOOP_HOME,并将这些环境变量的bin子目录配置到path变量中。
将hadoop2.6(x64)V0.2下的hadoop.dll和winutils.exe复制到HADOOP_HOME/bin目录下。
3. 配置Eclipse
将hadoop-eclipse-plugin-2.6.0.jar复制到eclilpse的plugins目录下。
启动eclipse,并设置好workspace。插件安装成功的话,启动之后可以看到如下内容:
4. 配置hadoop
打开“window”-“Preferenes”-“Hadoop Mep/Reduce”,配置到Hadoop_Home目录。
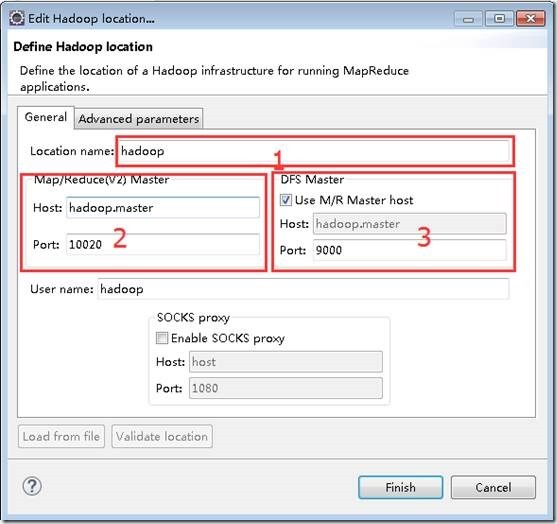
打开“window”-“show view” -“Mepreduce Tools” –“Mep/Reduce Locations”,创建一个Locations,配置如下。

1位置为配置的名称,任意。
2位置为mapred-site.xml文件中的mapreduce.jobhistory.address配置。
3位置为core-site.xml文件中的fs.default.name配置。
配置好以上信息之后,可以在Project Explorer中看到以下内容,即表示配置成功。
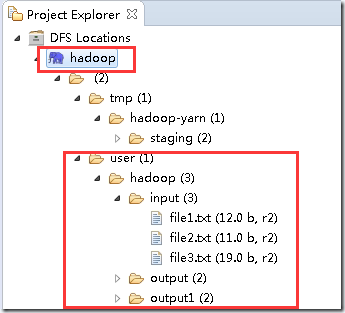
上图表示读取到了配置的hdfs信息,一共有3个文件夹input、output、output1,input目录下有3个文件。
注:以上内容为我自己环境中创建的,你看到的可能跟我的不一样。
内容可以通过在hadoop.master上执行
hadoop fs -mkdir input --创建文件夹
hadoop fs -put $localFilePath input --将本地文件上传到HDFS的input目录下
三、创建示例程序
1. 新建一个WordCount类
打开eclipse,创建一个Map/Reduce Project,并创建一个org.apache.hadoop.examples.WordCount类。
拷贝hadoop-2.6.4-src.tar.gz中hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples下的WordCount.java文件中的内容到新创建的类中。
2. 配置log4j
在src目录下,创建log4j.properties文件
log4j.rootLogger=debug,stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n
log4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=mapreduce_test.log
log4j.appender.R.MaxFileSize=1MB
log4j.appender.R.MaxBackupIndex=1
log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%
log4j.logger.com.codefutures=DEBUG
3. 配置运行参数
选择“run”-“run configurations”,在“Arguments”里加入“hdfs://hadoop.master:9000/user/hadoop/input hdfs://hadoop.master:9000/user/hadoop/output1”。
格式为“输入路径 输出路径”,如果输出路径必须为空或未创建,否则会报错。
如下图:
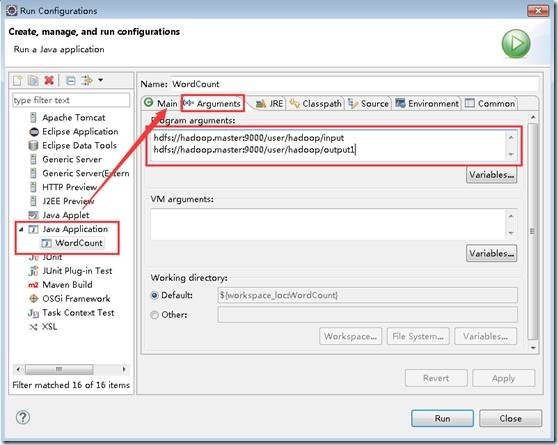
注:如果”Java Application”下面没有“WordCount”,可以选择右键,New一个即可。
4. 执行查看结果
配置好之后,执行。查看控制台输出以下内容,表示执行成功:
|
INFO - Job job_local1914346901_0001 completed successfully INFO - Counters: 38 FILE: Number of bytes read=4109 FILE: Number of bytes written=1029438 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=134 HDFS: Number of bytes written=40 HDFS: Number of read operations=37 HDFS: Number of large read operations=0 HDFS: Number of write operations=6 Map-Reduce Framework Map input records=3 Map output records=7 Map output bytes=70 Map output materialized bytes=102 Input split bytes=354 Combine input records=7 Combine output records=7 Reduce input groups=5 Reduce shuffle bytes=102 Reduce input records=7 Reduce output records=5 Spilled Records=14 Shuffled Maps =3 Failed Shuffles=0 Merged Map outputs=3 GC time elapsed (ms)=21 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=1556611072 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=42 File Output Format Counters Bytes Written=40 |
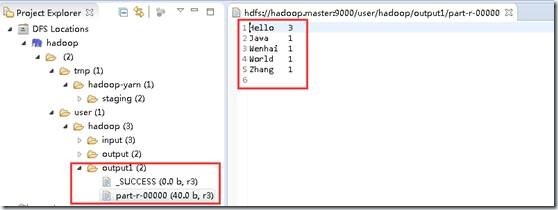
在“DFS Locations”下,刷新刚创建的“hadoop”看到本次任务的输出目录下是否有输出文件。
四、问题FAQ
1. 问题1:NativeCrc32.nativeComputeChunkedSumsByteArray错误
【问题描述】启动示例程序时,报nativeComputeChunkedSumsByteArray异常。控制台日志显示如下:
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
at org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(Native Method)
【原因分析】hadoop.dll文件版本错误,替换对应的版本文件。由于hadoop.dll 版本问题出现的,这是由于hadoop.dll 版本问题,2.4之前的和自后的需要的不一样,需要选择正确的版本(包括操作系统的版本),并且在 Hadoop/bin和 C:\windows\system32 上将其替换。
【解决措施】下载对应的文件替换即可。http://download.csdn.net/detail/myamor/8393459 (2.6.X_64bit)
Win7+Eclipse+Hadoop2.6.4开发环境搭建的更多相关文章
- Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例【附详细代码】
http://blog.csdn.net/xiefu5hh/article/details/51707529 Spark+ECLIPSE+JAVA+MAVEN windows开发环境搭建及入门实例[附 ...
- Hadoop-2.8.0 开发环境搭建(Mac)
Hadoop是一个由Apache基金会开发的分布式系统架构,简称HDFS,具有高容错性.可伸缩性等特点,并且可以部署在低配置的硬件上:同时,提供了高吞吐量的数据访问性能,适用于超大数据集的应用程序,以 ...
- 【hadoop之翊】——windows 7使用eclipse下hadoop应用开发环境搭建
由于一些缘故,这节内容到如今才写.事实上弄hadoop有一段时间了,能够编写一些小程序了,今天来还是来说说环境的搭建.... 说明一下:这篇文章的步骤是接上一篇的hadoop文章的:http://bl ...
- hadoop2.6---windows下开发环境搭建
一.准备插件 1.自己编译 1.1 安装Ant 官网下载Ant,apache-ant-1.9.6-bin.zip 配置环境变量,新建ANT_HOME,值是E:\apache-ant-1.9.6:PAT ...
- Windows下基于eclipse的Spark应用开发环境搭建
原创文章,转载请注明: 转载自www.cnblogs.com/tovin/p/3822985.html 一.软件下载 maven下载安装 :http://10.100.209.243/share/so ...
- Ubuntu+Eclipse+ADT+Genymotion+VirtualBox开发环境搭建
1.Eclispe安装就不说了 2.以下说说怎样安装ADT插件.有两种途径: (1)在线安装: 地址:https://dl-ssl.google.com/android/eclipse/(只是近期天朝 ...
- Android开发环境搭建(图文教程)
昨天又搭建了一次Android的开发环境,尝试了好几种方式,也遇到了一些问题,在此分享一下. 注意:官网公布的最新版本号的SDK和ADT(23.0.0),对于和Eclipse集成的开发环境是有BUG存 ...
- [转]Android开发环境搭建(图文教程)
转自:http://www.cnblogs.com/yxwkf/p/3853046.html 昨天又搭建了一次Android的开发环境,尝试了好几种方式,也遇到了一些问题,在此分享一下. 注意:官网公 ...
- mac10.9下eclipse的storm开发环境搭建
--------------------------------------- 博文作者:迦壹 博客地址:http://idoall.org/home.php?mod=space&uid=1& ...
随机推荐
- oracle 数据库 时间差 年数、月数、天数、小时数、分钟数、秒数
declare l_start date := to_date('2015-04-29 01:02:03', 'yyyy-mm-dd hh24:mi:ss'); l_end date := to_da ...
- *HDU3339 最短路+01背包
In Action Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- 2016huasacm暑假集训训练四 DP_B
题目链接:http://acm.hust.edu.cn/vjudge/contest/125308#problem/M 题意:有N件物品和一个容量为V的背包.第i件物品的费用是体积c[i],价值是w[ ...
- java读取项目中文件路径及乱码解决
this.getClass.getResource(path).getPath(); 如果出现中文乱码,可以使用java.net.URLDecoder.decode方法进行处理 如:URLDecode ...
- 关于div的滚动条滚动到底部,内容显示不全的问题。(已解决)
今天我做了一个带有滚动条,底部有两个按钮的div. 当我拖动滚动条到底部, 按钮没有显示出来. 我看了看我的样式设置,是这样的: /* 内容样式 */ #contentPartDiv{ posit ...
- AD Local Domain groups, Global groups and Universal groups
http://ss64.com/nt/syntax-groups.html Rules that govern when a group can be added to another group ( ...
- surface pro 4 wifi掉线问题
更新你的无线网卡驱动到最新版本15.68.9032.47,重启.或者运行regedit修改注册表 HKEY_LOCAL_MACHINE\SYSTEM\ControlSet001\Services\mr ...
- JAVA修饰符
修饰符用来定义类.方法或者变量,通常放在语句的最前端.我们通过下面的例子来说明: public class className { // ... } private boolean myFlag; s ...
- VC 6中配置OpenGL开发环境
2010,2012中配置类似 http://hi.baidu.com/yanzi52351/item/f9a600dffa4caa4ddcf9be1d VC 6中配置OpenGL开发环境 这里,我习惯 ...
- 【leedcode】 Median of Two Sorted Arrays
https://leetcode.com/problems/median-of-two-sorted-arrays/ There are two sorted arrays nums1 and num ...