scrapy爬虫框架入门实例(一)
流程分析
抓取内容(百度贴吧:网络爬虫吧)
页面: http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=utf-8
数据:1.帖子标题;2.帖子作者;3.帖子回复数
通过观察页面html代码来帮助我们获得所需的数据内容。
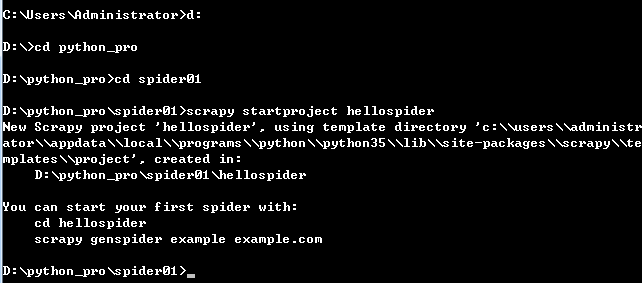
一、工程建立
在控制台模式下进入你要建立工程的文件夹执行如下命令创建工程:

二、实现过程
1、在items.py中定义自己要抓取的数据:
import scrapy class DetailItem(scrapy.Item):
# 抓取内容:1.帖子标题;2.帖子作者;3.帖子回复数
title = scrapy.Field()
author = scrapy.Field()
reply = scrapy.Field()
2、然后在spiders目录下编辑myspider.py那个文件:
import scrapy
from hellospider.items import DetailItem
import sys class MySpider(scrapy.Spider):
"""
name:scrapy唯一定位实例的属性,必须唯一
allowed_domains:允许爬取的域名列表,不设置表示允许爬取所有
start_urls:起始爬取列表
start_requests:它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入
我们自定义的规律的链接
parse:回调函数,处理response并返回处理后的数据和需要跟进的url
log:打印日志信息
closed:关闭spider
"""
# 设置name
name = "spidertieba"
# 设定域名
allowed_domains = ["baidu.com"]
# 填写爬取地址
start_urls = [
"http://tieba.baidu.com/f?kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&ie=utf-8",
] # 编写爬取方法
def parse(self, response):
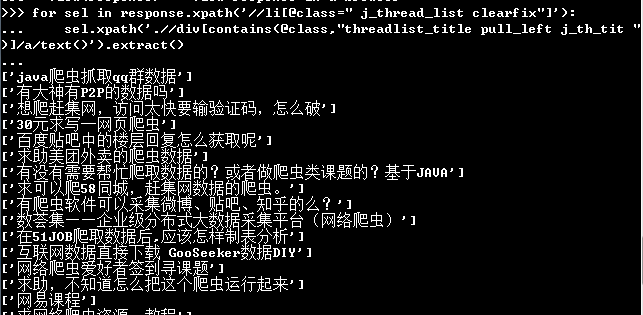
for line in response.xpath('//li[@class=" j_thread_list clearfix"]'):
# 初始化item对象保存爬取的信息
item = DetailItem()
# 这部分是爬取部分,使用xpath的方式选择信息,具体方法根据网页结构而定
item['title'] = line.xpath('.//div[contains(@class,"threadlist_title pull_left j_th_tit ")]/a/text()').extract()
item['author'] = line.xpath('.//div[contains(@class,"threadlist_author pull_right")]//span[contains(@class,"frs-author-name-wrap")]/a/text()').extract()
item['reply'] = line.xpath('.//div[contains(@class,"col2_left j_threadlist_li_left")]/span/text()').extract()
yield item
【注】xpath语法可参考:http://www.w3school.com.cn/xpath/xpath_syntax.asp


3、执行命令 scrapy crawl [类中name值]

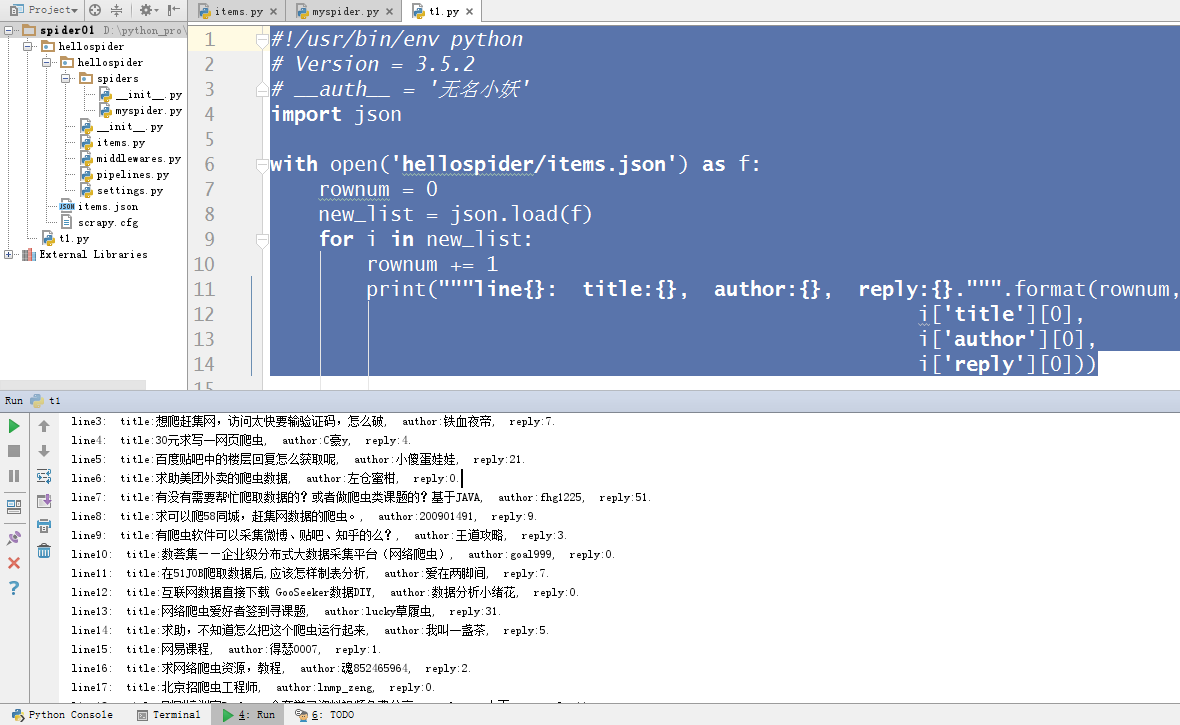
#!/usr/bin/env python
# Version = 3.5.2
# __auth__ = '无名小妖'
import json with open('hellospider/items.json') as f:
rownum = 0
new_list = json.load(f)
for i in new_list:
rownum += 1
print("""line{}: title:{}, author:{}, reply:{}.""".format(rownum,
i['title'][0],
i['author'][0],
i['reply'][0]))
至此,scrapy的最简单的应用就完成了。
后续还会有更复杂的爬虫示例,敬请关注!
scrapy爬虫框架入门实例(一)的更多相关文章
- Python之Scrapy爬虫框架 入门实例(一)
一.开发环境 1.安装 scrapy 2.安装 python2.7 3.安装编辑器 PyCharm 二.创建scrapy项目pachong 1.在命令行输入命令:scrapy startproject ...
- Scrapy 爬虫框架入门案例详解
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者:崔庆才 Scrapy入门 本篇会通过介绍一个简单的项目,走一遍Scrapy抓取流程,通过这个过程,可以对 ...
- 【python】Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- [Python] Scrapy爬虫框架入门
说明: 本文主要学习Scrapy框架入门,介绍如何使用Scrapy框架爬取页面信息. 项目案例:爬取腾讯招聘页面 https://hr.tencent.com/position.php?&st ...
- scrapy爬虫框架入门教程
scrapy安装请参考:安装指南. 我们将使用开放目录项目(dmoz)作为抓取的例子. 这篇入门教程将引导你完成如下任务: 创建一个新的Scrapy项目 定义提取的Item 写一个Spider用来爬行 ...
- scrapy爬虫框架入门实战
博客 https://www.jianshu.com/p/61911e00abd0 项目源码 https://github.com/ppy2790/jianshu/blob/master/jiansh ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
随机推荐
- Windows 驱动程序工具包中的头文件
MSDN原文:https://msdn.microsoft.com/zh-cn/library/windows/hardware/ff554695(v=vs.85).aspx Windows 驱动程序 ...
- 让一个端口同时做两件事:http/https和ssh
相信很多人都在YY:能不能让80端口分析连接协议,如果是http协议就让服务器交给http服务程序(如Apache.Nginx等)处理,如果是ssh协议就交给ssh服务程序(如OpenSSH Serv ...
- Server Name Indication(SNI)
转载自: http://openwares.net/misc/server_name_indication.html Server Name Indication是用来改善SSL(Secure Soc ...
- Axure 使用心得总结
Axure的本意是高效快捷的完成原型制作,能够清晰的说明功能,交互就是好的,"够漂亮"就行,不需要做到很完美,至于完美还是交给专业的UI吧. 一些心得记录下来: 1.下载一些常用的 ...
- kubernetes 内网节点部署笔记(一)
在Centos7上部署kubernetes时,碰到很多坑,特别在摸拟在内网部署时,有来自GFW的障碍,有来自Firewalld的阻塞,反正是各种不服,终于慢慢理顺了思路,自己记录一下,防止遗忘. 环境 ...
- ImageJ 学习第一篇
ImageJ是世界上最快的纯Java的图像处理程序.它可以过滤一个2048x2048的图像在0.1秒内(*).这是每秒40万像素!ImageJ的扩展通过使用内置的文本编辑器和Java编译器的Image ...
- c++容器
1.vector:实质是动态堆数组,连续存储的内存区域,支持快速的随机访问. 2.list:实质是双向循环链表,支持在中间进行快速的插入删除,但是不能支持快速的随机访问.非连续的内存区域. 3.deq ...
- Geodatabase数据模型
1 Geodatabase概念 Geodatabase是ArcInfo8引入的一种全新的面向对象的空间数据模型,是建立在DBMS之上的统一的.智能的空间数据模型.“统一”是指,Geodatabase ...
- java路径问题
使用了java这么久一直对java获取路径存在困惑,将一些常用的获取路径方式记录如下: val property = System.getProperty("user.dir")) ...
- android微信分享要注意的地方
最近在做android端分享的功能,在微信开放平台查看了下官网上的开发文档,一步一步的按文档上的步骤来: 1.申请你的AppID 2.下载开发工具包 3.搭建开发环境,引入libammsdk.jar文 ...