Prim算法(二)之 C++详解
本章是普里姆算法的C++实现。
目录
1. 普里姆算法介绍
2. 普里姆算法图解
3. 普里姆算法的代码说明
4. 普里姆算法的源码转载请注明出处:http://www.cnblogs.com/skywang12345/
更多内容:数据结构与算法系列 目录
普里姆算法介绍
普里姆(Prim)算法,是用来求加权连通图的最小生成树的算法。
基本思想
对于图G而言,V是所有顶点的集合;现在,设置两个新的集合U和T,其中U用于存放G的最小生成树中的顶点,T存放G的最小生成树中的边。
从所有uЄU,vЄ(V-U) (V-U表示出去U的所有顶点)的边中选取权值最小的边(u, v),将顶点v加入集合U中,将边(u, v)加入集合T中,如此不断重复,直到U=V为止,最小生成树构造完毕,这时集合T中包含了最小生成树中的所有边。
普里姆算法图解
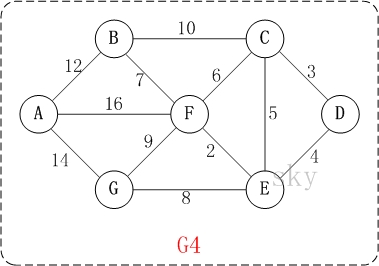
以上图G4为例,来对普里姆进行演示(从第一个顶点A开始通过普里姆算法生成最小生成树)。

初始状态:V是所有顶点的集合,即V={A,B,C,D,E,F,G};U和T都是空!
第1步:将顶点A加入到U中。
此时,U={A}。
第2步:将顶点B加入到U中。
上一步操作之后,U={A}, V-U={B,C,D,E,F,G};因此,边(A,B)的权值最小。将顶点B添加到U中;此时,U={A,B}。
第3步:将顶点F加入到U中。
上一步操作之后,U={A,B}, V-U={C,D,E,F,G};因此,边(B,F)的权值最小。将顶点F添加到U中;此时,U={A,B,F}。
第4步:将顶点E加入到U中。
上一步操作之后,U={A,B,F}, V-U={C,D,E,G};因此,边(F,E)的权值最小。将顶点E添加到U中;此时,U={A,B,F,E}。
第5步:将顶点D加入到U中。
上一步操作之后,U={A,B,F,E}, V-U={C,D,G};因此,边(E,D)的权值最小。将顶点D添加到U中;此时,U={A,B,F,E,D}。
第6步:将顶点C加入到U中。
上一步操作之后,U={A,B,F,E,D}, V-U={C,G};因此,边(D,C)的权值最小。将顶点C添加到U中;此时,U={A,B,F,E,D,C}。
第7步:将顶点G加入到U中。
上一步操作之后,U={A,B,F,E,D,C}, V-U={G};因此,边(F,G)的权值最小。将顶点G添加到U中;此时,U=V。
此时,最小生成树构造完成!它包括的顶点依次是:A B F E D C G。
普里姆算法的代码说明
以"邻接矩阵"为例对普里姆算法进行说明,对于"邻接表"实现的图在后面会给出相应的源码。
1. 基本定义
class MatrixUDG {
#define MAX 100
#define INF (~(0x1<<31)) // 无穷大(即0X7FFFFFFF)
private:
char mVexs[MAX]; // 顶点集合
int mVexNum; // 顶点数
int mEdgNum; // 边数
int mMatrix[MAX][MAX]; // 邻接矩阵
public:
// 创建图(自己输入数据)
MatrixUDG();
// 创建图(用已提供的矩阵)
//MatrixUDG(char vexs[], int vlen, char edges[][2], int elen);
MatrixUDG(char vexs[], int vlen, int matrix[][9]);
~MatrixUDG();
// 深度优先搜索遍历图
void DFS();
// 广度优先搜索(类似于树的层次遍历)
void BFS();
// prim最小生成树(从start开始生成最小生成树)
void prim(int start);
// 打印矩阵队列图
void print();
private:
// 读取一个输入字符
char readChar();
// 返回ch在mMatrix矩阵中的位置
int getPosition(char ch);
// 返回顶点v的第一个邻接顶点的索引,失败则返回-1
int firstVertex(int v);
// 返回顶点v相对于w的下一个邻接顶点的索引,失败则返回-1
int nextVertex(int v, int w);
// 深度优先搜索遍历图的递归实现
void DFS(int i, int *visited);
};
MatrixUDG是邻接矩阵对应的结构体。
mVexs用于保存顶点,mVexNum是顶点数,mEdgNum是边数;mMatrix则是用于保存矩阵信息的二维数组。例如,mMatrix[i][j]=1,则表示"顶点i(即mVexs[i])"和"顶点j(即mVexs[j])"是邻接点;mMatrix[i][j]=0,则表示它们不是邻接点。
2. 普里姆算法
/*
* prim最小生成树
*
* 参数说明:
* start -- 从图中的第start个元素开始,生成最小树
*/
void MatrixUDG::prim(int start)
{
int min,i,j,k,m,n,sum;
int index=0; // prim最小树的索引,即prims数组的索引
char prims[MAX]; // prim最小树的结果数组
int weights[MAX]; // 顶点间边的权值
// prim最小生成树中第一个数是"图中第start个顶点",因为是从start开始的。
prims[index++] = mVexs[start];
// 初始化"顶点的权值数组",
// 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。
for (i = 0; i < mVexNum; i++ )
weights[i] = mMatrix[start][i];
// 将第start个顶点的权值初始化为0。
// 可以理解为"第start个顶点到它自身的距离为0"。
weights[start] = 0;
for (i = 0; i < mVexNum; i++)
{
// 由于从start开始的,因此不需要再对第start个顶点进行处理。
if(start == i)
continue;
j = 0;
k = 0;
min = INF;
// 在未被加入到最小生成树的顶点中,找出权值最小的顶点。
while (j < mVexNum)
{
// 若weights[j]=0,意味着"第j个节点已经被排序过"(或者说已经加入了最小生成树中)。
if (weights[j] != 0 && weights[j] < min)
{
min = weights[j];
k = j;
}
j++;
}
// 经过上面的处理后,在未被加入到最小生成树的顶点中,权值最小的顶点是第k个顶点。
// 将第k个顶点加入到最小生成树的结果数组中
prims[index++] = mVexs[k];
// 将"第k个顶点的权值"标记为0,意味着第k个顶点已经排序过了(或者说已经加入了最小树结果中)。
weights[k] = 0;
// 当第k个顶点被加入到最小生成树的结果数组中之后,更新其它顶点的权值。
for (j = 0 ; j < mVexNum; j++)
{
// 当第j个节点没有被处理,并且需要更新时才被更新。
if (weights[j] != 0 && mMatrix[k][j] < weights[j])
weights[j] = mMatrix[k][j];
}
}
// 计算最小生成树的权值
sum = 0;
for (i = 1; i < index; i++)
{
min = INF;
// 获取prims[i]在mMatrix中的位置
n = getPosition(prims[i]);
// 在vexs[0...i]中,找出到j的权值最小的顶点。
for (j = 0; j < i; j++)
{
m = getPosition(prims[j]);
if (mMatrix[m][n]<min)
min = mMatrix[m][n];
}
sum += min;
}
// 打印最小生成树
cout << "PRIM(" << mVexs[start] << ")=" << sum << ": ";
for (i = 0; i < index; i++)
cout << prims[i] << " ";
cout << endl;
}
普里姆算法的源码
这里分别给出"邻接矩阵图"和"邻接表图"的普里姆算法源码。
Prim算法(二)之 C++详解的更多相关文章
- Prim算法(三)之 Java详解
前面分别通过C和C++实现了普里姆,本文介绍普里姆的Java实现. 目录 1. 普里姆算法介绍 2. 普里姆算法图解 3. 普里姆算法的代码说明 4. 普里姆算法的源码 转载请注明出处:http:// ...
- Floyd算法(二)之 C++详解
本章是弗洛伊德算法的C++实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明出处:http://www.cnblogs.c ...
- Dijkstra算法(二)之 C++详解
本章是迪杰斯特拉算法的C++实现. 目录 1. 迪杰斯特拉算法介绍 2. 迪杰斯特拉算法图解 3. 迪杰斯特拉算法的代码说明 4. 迪杰斯特拉算法的源码 转载请注明出处:http://www.cnbl ...
- Kruskal算法(二)之 C++详解
本章是克鲁斯卡尔算法的C++实现. 目录 1. 最小生成树 2. 克鲁斯卡尔算法介绍 3. 克鲁斯卡尔算法图解 4. 克鲁斯卡尔算法分析 5. 克鲁斯卡尔算法的代码说明 6. 克鲁斯卡尔算法的源码 转 ...
- 转:JAVAWEB开发之权限管理(二)——shiro入门详解以及使用方法、shiro认证与shiro授权
原文地址:JAVAWEB开发之权限管理(二)——shiro入门详解以及使用方法.shiro认证与shiro授权 以下是部分内容,具体见原文. shiro介绍 什么是shiro shiro是Apache ...
- 二叉搜索树详解(Java实现)
1.二叉搜索树定义 二叉搜索树,是指一棵空树或者具有下列性质的二叉树: 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值: 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根 ...
- 数据结构图文解析之:二叉堆详解及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- Java进阶(三十二) HttpClient使用详解
Java进阶(三十二) HttpClient使用详解 Http协议的重要性相信不用我多说了,HttpClient相比传统JDK自带的URLConnection,增加了易用性和灵活性(具体区别,日后我们 ...
- Spring Boot 启动(二) 配置详解
Spring Boot 启动(二) 配置详解 Spring 系列目录(https://www.cnblogs.com/binarylei/p/10198698.html) Spring Boot 配置 ...
随机推荐
- html5+css3 制作音乐播放器
//css// body , html{ margin:0; padding:0; font:12px Arial, Helvetica, sans-serif; } .Mus ...
- C/C++头文件一览
C.传统 C++ #include <assert.h> //设定插入点 #include <ctype.h> //字符处理 #include <errno.h> ...
- cocoapods的时候出现的问题 _OBJC_CLASS_$_XXX
最新的cocoapod导入xmpp的时候,会出现循环依赖,所以撸主选择了手动导入. 一开始还用的挺开心的,后来,使用cocoapods导入其他的框架,发现调用的时候总是报错. Undefined sy ...
- MVC+EF6使用MySQL+CodeFirst的详细配置
环境: WIN7(64位旗舰版)+VS2012+MySQL5.6(32位版,在另一台服务器中,环境是win2003) 1.下载并安装MysqlforVisualStudio.zip,此软件功能是让VS ...
- C#实现 word、pdf、ppt 转为图片
office word文档.pdf文档.powerpoint幻灯片是非常常用的文档类型,在现实中经常有需求需要将它们转换成图片 -- 即将word.pdf.ppt文档的每一页转换成一张对应的图片,就像 ...
- 学习设计模式第三 - 基础使用UML表示关系
面向对象的思想中存在如下几种关系,一般为了方便交流都使用UML的类图来展现类之间的关系.所以了解类图中符号的含义对看懂类图,尤其是用类图展示的设计模式很有帮助.下面依次介绍这几种关系 类继承关系 继承 ...
- Silverlight4中实现Theme的动态切换
Silverlight一般用来开发一些企业的应用系统,如果用户一直面对同一种风格的页面,时间长了难免厌烦,所以一般都会提供好几种风格及Theme供用户选中,下面就来说一下如何在不重新登录系统的情况下, ...
- 谈谈对BPM的理解
BPM的产生缘由 近年来,随着计算机技术的发展和互联网时代的到来,我们已经进入了信息时代,也称为数字化时代,在这数字化的时代里,企业的经营管理都受到了极大的挑战.从上世纪90年代起至今,企业的信息化工 ...
- 依据BOM和已经存在的文件生成其他种类的文件
在BOM中记录中有物料编码,物料名称,物料规格等,而且依据BOM已经生成了一些的文件,如采购规格书,这个时候需要生成相应的检验规格书模板,可以使用下面的VBA代码,具体代码如下: Function I ...
- 分享最新的博客到LinkedIn Timeline
使用Octopress作为我的博客框架有两年了.使用起来一直很顺手,这个工具真正的把博客跟写代码等同起来,非常酷炫.再加上各种各样的定制化,简直是随心所欲.我针对自己的需求对Octopress框架进行 ...