Ensemble Learning
Ensemble Learning是机器学习里最常见的建模方法,RandomForest 和 GBDT 采用了Ensemble Learning模式,只是具体方法不同。
下面简单翻译下一 https://www.analyticsvidhya.com/blog/2015/09/questions-ensemble-modeling/ 这篇文章,再来理解一下Ensemble Learning模式。
与Ensemble Learning相关的常见问题
1、什么是Ensemble Learning?
2、什么是bagging, boosting, stacking?
3、同一个ML算法怎么做集成(ensemble)?
4、不同的模型如何确定权重?
5、ensemble模型有什么优势?
下面一个一个来回答。
1、什么是Ensemble Learning?
文中举了一个垃圾邮件检测的例子,简单来说就是,仅凭单个规则很难准确识别垃圾邮件,但是使用多条规则会提高识别的准确率。这个例子是为了说明,ensemble learning是一个“多合一”的方法。“多”指的是多个个体模型(individual models),注意,并非是多个独立模型;“合一”指的是多个模型共同形成一个识别/回归结果。Ensemble的一般特点是,多个模型间的相关性越低,合成之后的识别/回归效果越好。
具体的合成方法有多种,其中最典型的ensemble算法是随机森林(Random Forest)。引用文中的话是:
It (Random Forest)performs better compared to individual CART model by classifying a new object where each tree gives “votes” for that class and the forest chooses the classification having the most votes (over all the trees in the forest). In case of regression, it takes the average of outputs of different trees.
2、什么是bagging, boosting, stacking?
Bagging是对样本进行采样,构造出若干个新数据集,然后对应训练出若干个模型,再把这些模型合而为一,得到输出结果。其本质是降低了模型的方差(Variance)。
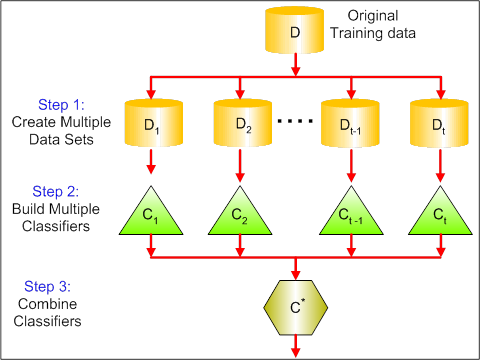
Boosting是一种模型迭代方法,初始化时,有一个简单的模型、各样本权重相等,由此得到识别结果,根据识别结果调整样本权重,判错的样本权重变大,据此得到新的模型,把新模型迭代到老模型上,再得到识别结果,如此循环迭代下去,最终若干个模型叠加在一起,得到最终的输出模型。
Boosting一般精确率比Bagging更高,但是容易过拟合(over-fit)。
常见的两种Boosting算法是 AdaBoost 和 Gradient Boosting。
[原文中的图没看懂,就不附图了]
Stacking就是简单的模型合成,先从原数据中训练得到若干个模型,然后用一个函数把若干个模型合成,输出最终的识别/回归结果。这里并没有介绍如何做合成,日后遇到具体案例再来细聊。
3、同一个ML算法怎么做集成(ensemble)?
可以把相同的模型集成起来,但是这样做的效果通常不会太好,更提倡的做法是把不同类型的模型集成起来,比如 把Random Forest , KNN 和 Naive Beyes集成起来,模型之间越是不同,集成后的效果往往越好。
文中举了个反直觉的例子,三个模型(A, B, C),识别的精确率分别是85%,80%和50%,A和B相关性很强,C和A, B的相关性很低,此时把A和B做集成是错误的,应该把A和C或者B和C做集成。
4、不同的模型如何确定权重?
不用动脑子的权重设置方法是等权重,动动脑子的方法有以下几个:
1. 计算多个base model的collinearity,基于得到的collinearity矩阵做model筛选,然后根据筛选出的model的cross validation score来确定model 的weight。 [这段话没有真正理解,需要实践来验证]
2. 利用单独的算法来确定权重,文中推荐了一篇文章 Finding Optimal Weights of Ensemble Learner using Neural Network 。
3. 可以借鉴其他算法,例如 Forward Selection of learners Selection with Replacement Bagging of ensemble methods 。
还可以到Kaggle上查找优秀的解决方案,学习那些方案中的ensemble方法。
5、ensemble模型有什么优势?
ensemble的优势在于两点:一是判别的精确率更高,二是模型更稳定,换一种说法是,ensemble可以减小偏差,减小方差,最终减小模型的泛化误差。
后记:ensemble learning方法本身不难理解,难在如何应用,待后续工作中有了应用案例再来写续篇。
Ensemble Learning的更多相关文章
- 7. ensemble learning & AdaBoost
1. ensemble learning 集成学习 集成学习是通过构建并结合多个学习器来完成学习任务,如下图: 集成学习通过将多个学习学习器进行结合,常可以获得比单一学习器更优秀的泛化性能 从理论上来 ...
- 【软件分析与挖掘】Multiple kernel ensemble learning for software defect prediction
摘要: 利用软件中的历史缺陷数据来建立分类器,进行软件缺陷的检测. 多核学习(Multiple kernel learning):把历史缺陷数据映射到高维特征空间,使得数据能够更好地表达: 集成学习( ...
- Ensemble Learning 之 Bagging 与 Random Forest
Bagging 全称是 Boostrap Aggregation,是除 Boosting 之外另一种集成学习的方式,之前在已经介绍过关与 Ensemble Learning 的内容与评价标准,其中“多 ...
- Ensemble Learning: Bootstrap aggregating (Bagging) & Boosting & Stacked generalization (Stacking)
Booststrap aggregating (有些地方译作:引导聚集),也就是通常为大家所熟知的bagging.在维基上被定义为一种提升机器学习算法稳定性和准确性的元算法,常用于统计分类和回归中. ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 壁虎书7 Ensemble Learning and Random Forests
if you aggregate the predictions of a group of predictors,you will often get better predictions than ...
- 7. 集成学习(Ensemble Learning)Stacking
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 6. 集成学习(Ensemble Learning)算法比较
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 5. 集成学习(Ensemble Learning)GBDT
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 3. 集成学习(Ensemble Learning)随机森林(Random Forest)
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
随机推荐
- 《FPGA全程进阶---实战演练》第三章之PCB叠层
1.双面板 在双层板设计layout时,最好不要不成梳状结构,因为这样构成的电路,回路面积较大,但是只要对较重要的信号加以地保护,布线完成之后将空的地方敷上地铜皮,并在多个过孔将两个地连接起来,可以弥 ...
- 关于C++输出中文乱码的解决方案
把页面编码转换为UTP-8的编码 1.打开G:\vs2013way\VC\vcprojectitems目录 在 file.h newc++file.cpp 中写两句话 #pragma once#pra ...
- Configurations of Vim/GVim of dsp
Linux环境写到用户主目录下的.vimrc文件(没有则新建),Windows环境则为GVim安装目录下的_vimrc(没有则新建),内容如下: "分上下两屏 "sp " ...
- Binding to a Service
应用组件(客户端)可以通过 bindService()方法绑定到service,Android系统随后会调用service的 onBind()方法,返回一个 IBinder 用于和service交互. ...
- 使用Ultra Librarian转换芯片的Altium Designer封装格式
第一步:找到对应芯片的CAD文件,以OPA350为例: http://www.ti.com/product/opa350 RE: 使用Ultra Librarian转换TI芯片的Altium De ...
- PHP中替换换行符方法总结
<?php header("content-type:text/html;charset=utf-8"); $str = "aaaa bbbb cccc dddd& ...
- c++ json cpp
一 编译链接 1 在相应官网下载jsoncpp 2 解压得到jsoncpp-src-0.5.0文件 3 打开jsoncpp-src-0.5.0 -> makefiles -> vs71 - ...
- <img/>标签onerror事件在IE下的bug和解决方法
IE下打开网页时,会弹出“Stack overflow at line: 0”的弹框.经分析,这个bug是由于img标签的onerror事件引起的.程序中用到的代码片段如下:正常情况下显示src所指路 ...
- 【matlab】图像直方图
使用imhist函数(要先用rgb2gray转化为灰度图像) 利用matlab计算图像直方图函数为imhist() 具体用法: imhist( i );直接显示图像i的灰度直方图: imhist(i, ...
- Win8快捷键收集大汇总
键盘党的用户有福了,熟悉操作系统快捷键,提高开发效率. Windows 8 常用快捷键: Windows 键 可在开始屏幕主菜单及最后一个应用程序间循环切换 Windows 键 + C 打开“超级按钮 ...