Solr学习之三 solr配置说明之一
严格来说,我这篇内容,主要是根据Solr in Action关于配置的说明,以及参考Solr的wiki写的算是读书笔记吧,所有的图片默认来自Solr in Action这本书。
这本书我觉得对学习Solr来说非常有用,虽然目前没有中文版,另外对于其理解可能有偏差的地方,大家谨慎阅读。
一、总览
solr的配置重要的有三个:solr.xml、solrConfig.xml、schema.xml
solr.xml 是整个Solr节点的配置,是定义关于core的管理、collection分片、solr云
和http请求处理,不过目前改动不多,也没仔细研究。
solrConfig.xml:关于core或collection的主要配置信息。
schema.xml :定义索引中的文档结构,包括字段名、字段类型、字段处理方法等,类似于表结构定义,比它更复杂。
二、Solr启动过程
1、solr启动的时候会找Java的全局变量:solr.solr.home ,作为根目录。
2、solr到根目录下面的每个子目录,去查找是否包含core.properties的文件,有的话自动启动这个collection或core的恢复工作。
core.properties 配置文件主要配置,core或collection名字、shard分片信息、存储的数据和日志信息以及定义的schemal.xml等。
在恢复过程中,solr会在这个子目录下面的conf文件夹下去找solrconfig.xml的配置。
下图是solr的例子程序启动过程:

三、solrconfig.xml 配置说明
3.1 基本概述
- 基本说明
1、在solr的管理界面上选择具体的core就可以在files里面找到这个配置文件。
2、solr的配置的xml元素里面有两个比较特别的元素,一个是<arr>标示是命名的数组,
<lst>标示是排序的name/pairs对。
3、如何使修改的配置生效那,可以通过:前台core管理地方通过reload或通过http请求进行reload。
比如:http://xx.xx.xx.xx:8983/solr/admin/collections?action=RELOAD&name=testspeed3
- 具体内容
1、solr使用的Lucene版本、使用到的Jar路径配置;JMX配置,用于MBeans监控。
2、定义如何处理查询、如何处理索引的内容。
3.2 查询配置
solr最重要的功能之一是查询,我们看下当我们发起一个查询的时候,它的处理过程如何的,
发起的solr的http的ulr例子如下:

如果按照solr官方的利用Jetty服务器的话,那么处理过程如下图:
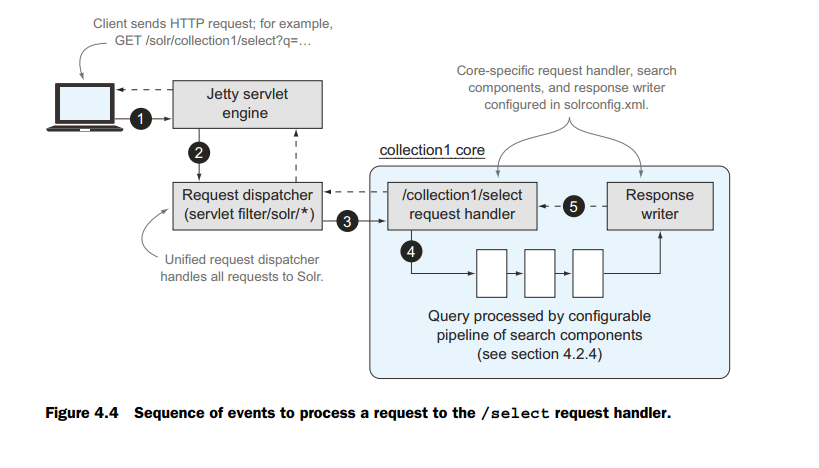
组件调用说明:
1、客户端发送HTTP的GET请求,查询关键字作为一个部分发送给Jetty服务器。
2、Jetty通过查询路径中的/solr上下文,通过调度器将这个请求映射到solr这个
web程序中去。
3、solr请求处理器,利用collection1这个路径来确定core或collection名字,通过select来找到注册在
solrconfig.xml中的请求处理器。
4、solrconfig.xml中注册的查询请求处理器执行一系列配置组件去处理。
5、按照solrconfig.xml中配置的返回处理组件,去设置返回的具体格式,执行返回。
查询请求处理器定义:
<requestHandler class="solr.SearchHandler" name="/select">
<lst name="defaults">
<str name="echoParams">explicit</str>
<int name="rows">10</int>
<str name="df">text</str>
</lst>
</requestHandler>
solr.SearchHandler 最终被解析为:org.apache.solr.handler.component.SearchHandler这个类进行处理。
solr其他的配置类似。
solr的查询过程的详细情况分为几个阶段,如下图:

1、请求参数装饰
1)defaults - 帮忙指定默认参数。
2)invariants-设置特定参数为固定值,重写客户端提供的值。
3)append - 在客户端的参数基础上进行参数的添加。
2、 第一组件
可选择配置的,用于查询处理前的预处理。
3、查询组件链
至少包含查询组件,用于执行具体的查询工作。
4、最后组件
用于处理查询后最后工作,比如拼写检查组件。
具体的定义,可以看下solrconfig.xml中提供的一个/browse定义的相关查询整个过程的配置。
3.3 搜索器(Searcher)
- 搜索器说明
在solr中,具体执行的搜索工作是通过搜索器执行的,如上面的图所示。在一个solr节点中,只有一个注册的搜索器。
它是一个基于Lucene索引的可读快照,当文档被添加到索引中,不是立刻可以搜索到。
让新添加的文档可以被搜索到,需要关闭老的搜索器,打开新的搜索器。一般来说commit操作就会执行这个操作。
这个过程是比较耗时的,关闭老的搜索器的时候,如果有用户正在查询,你的关闭动作需要等待。
另外所有的缓存都是基于旧的索引的,所以所有的缓存将失效,除非重新预热。
- 预热搜索器
如上文所述,搜索器在commit后需要重新打开,如果原来用户正在执行查询,缓存数据完全失效了,会促使重新执行查询,
导致用户体验差,所以需要预热。
一般来说,预热做两个事情,一执行预热语句、二用新的查询到的缓存数据代替老的缓存数据。
注意,多的预热语句,将会导致打开新的搜索器变慢,影响实时性,频繁提交的话将会导致内存等占用过大问题。
- 使用冷搜索器
如果说预热好的搜索器称为热的搜索器:)虽然没看到这个说法,那么没有预热的搜索器称为冷搜索器,配置如下:
<useColdSearcher>false</useColdSearcher> 如果这个配置为true,则来查询的时候,如果没有注册的
搜索器,有的搜索器正在预热,那不管是否预热完成,直接使用这个搜索器。
(这里面有个矛盾,既然所有的搜索器都是在新的预热好,老的才被关闭的,那么这种情况怎么存在,也许是第一次执行查询的时候)。
- 最大预热搜索器
当每次commit都会打开一个新的搜索器进行预热,那么如果commit操作在程序里面控制,在并发的情况下,可能有多个搜索器被打开,
有个配置项:<maxWarmingSearchers>2</maxWarmingSearchers>,通过它来配置可以打开的最大搜索器的个数,超过这个阀值,
commit操作会失败,如果经常因为这个失败,要看下是不是因为预热的时间过长。
3.4 缓存配置
- solr中缓存管理
1)缓存的尺寸和管理策略
Solr中设置缓存的尺寸是对象的数量,当超过这个数量的时候,Solr利用相关策略进行清除。
有两个主要策略LRU(即Least Recently Used )将最近最少使用的实体移出缓存;
LFU(least frequently used)是将最少使用次数的实体移出缓存,过滤器缓存比较适合LFU策略。
有个误区是在内存准许的情况下,尽可能设置你的缓存为尽可能的大。这个认识是错误的。
因为在commit后,缓存会失效,这将导致JVM回收这些内存,缓存大,导致JVM回收垃圾时间长,
服务被暂停的时间长。
2)缓存的命中和拆迁
命中率是指在缓存中发现一个查询请求的比例。代表你的程序从缓存中获得的好处。
期望是100%,驱逐数量显示根据前面的缓存策略,多少对象被驱逐出缓存,拆迁量大
可能意味着你的缓存设置的小。
3)缓存对象的失效
在solr中,所有的缓存对象和搜索器都是关联的,只要这个搜索器不关闭,这些缓存就是有效的。
4)自动预热新缓存
在一个commit之后,新的搜索器被打开,但是不立刻关闭老的搜索器,直到这个新的搜索器被完全预热。这个晚关闭策略主要用于填充新的搜索器的缓存。
每个solr缓存都支持一个autowarmCount的属性去设置最大的对象数量或者老的缓存的尺寸比例,去自动预热。
- 过滤器缓存( Filter Cache)
过滤器缓存影响最终文档结果,不影响打分。当你执行不同的查询语句,而相同过滤条件的时候,过滤器缓存就可以起作用。
过滤器缓存可以跨查询应用,可以显著优化查询的性能。
配置如下:
<filterCache class="solr.FastLRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
当你的过滤条件复杂,或你索引中的文档数量很多的时候,过滤器的创建和保存在内存中是很耗时间的,所以你希望可以预热过滤器缓存。如果一个过滤在你的程序中对很多请求都通用,那么缓存过滤器是有意义的。
每个对象在缓存中都有个key,在过滤器缓存中,这个key就是过滤器的查询语句,比如前面例子中:manu:belkin. 当预热一个过滤器缓存时候,旧的缓存中的key被抽取出来,在新的搜索器上被重新执行。如果你有上百个过滤器缓存,那么在预热的时候,solr必须执行这个100个过滤器的查询,这将消耗大量的时间。
我们建议预热的过滤器缓存,应该将autowarmCount设置为一个比较小的值。此外建议使用
LFU策略,下面是建议的配置:

过滤缓存器所占用的内存大小,当然和你在内存中缓存的文档数量有关,需要的内存是你文档数这么多的byte内存。
1000万的文档数大概占1.2MB内存。
- 查询结果缓存(Query result cache)
查询结果集缓存保存的是查询结果集。多次执行同一个查询的时候,后面的查询结果一般从查询结果缓存中直接得到,而不是在索引中再次执行相同的查询,这是优化花费高查询的强大方法。
查询结果集缓存定义如下:
<queryResultCache class="solr.LRUCache"
size="512" initialSize="512" autowarmCount="0">
查询结果集缓存了查询语句作为key,内部的Lucene文档ID链表作为value。
文档ID在索引中增加新的文档的时候或合并的时候可能发生变化,所以预热的时候,
缓存值需要被重新计算。
为了预热一个结果集,solr必须重新执行查询,相同的建议是保持autowarmCount为一个较小的值而不是默认的0,你将从中获益。还有些关于些杂项来设置查询结果集。
- 查询结果窗口大小
查询窗口<queryResultWindowsSize> 元素,在你执行一个查询的时候,给你提供额外的页面。
假设你的程序一页提供10个文档,在大多数情况下,用户只看第一和第二页。你可以设置这个值为20,这样在查看第二页的时候就不用再次查询了。
一般情况下,这个值设置为你一页需要查询的文档数量2-3倍,多了会给你的查询带来不必要的负担。
- 查询结果最大文档缓存
在前面,给缓存设置的值的大小,代表缓存的数量,每个缓存的最大大小也可以设置一个值。
<queryResultMaxDocsCached>200</queryResultMaxDocsCached>就是设置一个缓存实体可以缓存的最大文档数量。
- 准许延迟字段加载
具体配置为:<enableLazyFieldLoading>true</enableLazyFieldLoading>,设置了后,如果你的查询是查询文档集
中的一部分,那么只有需要的字段才被加载,其他字段不加载。
(默认的值为true。这样solr在根据读取Document信息时,如果enableLazyFieldLoading为True,把要返回的Field集合封装为一个SetNonLazyFieldSelector,
这里的Field的值都是立即加载的,即到索引库里把该Field的值取出来保存到Doc中的。doc的其他的Field的值则是通过延迟加载的。
也是就在document调用具体的get(String name)方式时,由LazyField去取值的。可见设置延迟加载为enableLazyFieldLoading
为True,
而且我们要返回的Field也很少时,那我们去读索引库所花的时间就少了)
- 文档缓存(Document Cache)
查询结果缓存是保存匹配查询的一系列文档内部ID,即使查询结果在缓存中。solr仍然需要从磁盘中加载搜索结果的文档信息。文档缓存,存储的key为内部文档ID,值为从磁盘加载进来的文档内容。因此查询结果集缓存可以利用文档缓存去查询在查询结果集中对应的文档信息。
<documentCache class="solr.LRUCache"
size="512"
initialSize="512"
autowarmCount="0"/>
- 字段值缓存(Field Cache)
它在排序的时候使用,严格来说属于Lucen来管理的。字段值缓存提供了通过文档ID来快速访问字段值。
Solr学习之三 solr配置说明之一的更多相关文章
- Solr学习之四-Solr配置说明之二
上一篇的配置说明主要是说明solrconfig.xml配置中的查询部分配置,在solr的功能中另外一个重要的功能是建索引,这是提供快速查询的核心. 按照Solr学习之一所述关于搜索引擎的原理中说明了建 ...
- Solr学习总结 Solr的安装与配置
接着前一篇,这里总结下Solr的安装与配置 1.准备 1.安装Java8 和 Tomcat9 ,java和tomcat 的安装这里不再重复.需要注意的是这两个的版本兼容问题.貌似java8 不支持,t ...
- 02——Solr学习之Solr安装与配置(linux上的安装)
借鉴博客:https://www.jianshu.com/p/1100f54fcbd8 https://www.cnblogs.com/jepson6669/p/9134652.html 1.准备一个 ...
- 03——Solr学习之Solr的使用(不会用)
1.先放上次在linux搭建成功的solr管理UI界面 2.有个很蛋疼的问题我就要吐槽一下了 由于没接触过solr这玩意,在百度上一顿操作搜索怎么用,怎么导入数据,建索引库什么的,看了一大片别人的博客 ...
- 我的solr学习笔记--solr admin 页面 检索调试
前言 Solr/Lucene是一个全文检索引擎,全文引擎和SQL引擎所不同的是强调部分相关度高的内容返回,而不是所有内容返回,所以部分内容包含在索引库中却无法命中是正常现象. 多数情况下我们 ...
- lucene&solr学习——solr学习(二) Solr管理索引库
1.什么是solrJ solrj是访问Solr服务的java客户端,提供索引和搜索的请求方法,SolrJ通常在嵌入在业务系统中,通过SolrJ的API接口操作Solr服务,如下图: 依赖jar包: 2 ...
- Solr学习总结(六)SolrNet的高级用法(复杂查询,分页,高亮,Facet查询)
上一篇,讲到了SolrNet的基本用法及CURD,这个算是SolrNet 的入门知识介绍吧,昨天写完之后,有朋友评论说,这些感觉都被写烂了.没错,这些基本的用法,在网上百度,资料肯定一大堆,有一些写的 ...
- Solr学习总结(五)SolrNet的基本用法及CURD
上一篇已经讲到了Solr 查询的相关的参数.这里在讲讲C#是如何通过客户端请求和接受solr服务器的数据, 这里推荐使用SolrNet,主要是:SolrNet使用非常方便,而且用户众多,一直都在更新, ...
- Solr学习总结(一)Solr介绍
最近一直在搞Solr的问题,研究Solr 的优化,搜索引擎的bug修改等,这几天终于有时间,闲下来总结分享,以便大家参考,与大家一起来共同学习. Solr是一个基于Lucene的全文搜索引擎,同 ...
随机推荐
- 解决Linux SSH登录慢
出现ssh登录慢一般有两个原因:DNS反向解析的问题和ssh的gssapi认证 :ssh的gssapi认证问题 GSSAPI ( Generic Security Services Applicati ...
- google kaptcha 验证码组件使用简介
kaptcha 是一个非常实用的验证码生成工具.有了它,你可以生成各种样式的验证码,因为它是可配置的.kaptcha工作的原理是调用 com.google.code.kaptcha.servlet.K ...
- web页面中可以包含多个对象
# encoding=utf-8 #python 2.7.10 #xiaodeng #web页面中可以包含多个对象 #HTTP权威指南 10页 #应用程序完成一项任务时通常会发布多个http事务.如: ...
- 学习KNN
转:© 著作权归作者所有 by ido 什么是KNN算法呢?顾名思义,就是K-Nearest neighbors Algorithms的简称.我们可能都知道最近邻算法,它就是KNN算法在k=1时的特例 ...
- Android网络开发之HttpURLConnection
http是一个可靠的传输,建立在TCP/IP连接之上,缺省端口是80,其他端口号也可以用.Android可以用HttpURLConnection或HttpClient接口来开发http程序. http ...
- 一般web典型的项目目录结构
本文转自:http://blog.sina.com.cn/s/blog_4758a28b0100l3lp.html WebRoot- -common (系统框架公用jsp 如foote ...
- HDUOJ------Worm
Worm Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...
- Python 装饰器学习心得
最近打算重新开始记录自己的学习过程,于是就捡起被自己废弃了一年多的博客.这篇学习笔记主要是记录近来看的有关Python装饰器的东西. 0. 什么是装饰器? 本质上来说,装饰器其实就是一个特殊功能的函数 ...
- 【LeetCode】144. Binary Tree Preorder Traversal (3 solutions)
Binary Tree Preorder Traversal Given a binary tree, return the preorder traversal of its nodes' valu ...
- HighCharts: 设置时间图x轴的宽度
这个x轴宽度的设置整了好久,被老板催的要死 highcharts的api文档很难找,找了半天也没找到,网上资料少,说的试了下,也没有,我用的图里api文档里没有介绍,这个属性不知道的话,根本不好找.为 ...