编译原理LL(1)文法
从左向右扫描输入,然后产生最左推导(就是每次都把最左边的非终结字符用产生式代替)。
(一)First集合
比如有产生式 A-> + T | - P , 当我们读到串为 +开头的时候,我们可以很直接地判断选择 A-> + T 这个生成式;串为- 开头的时候,选择 A-> - P 这个生成式。但如果文法是类似于A →T | P 这样的都以非终结字符开头的呢?一眼就很难判断的,我们就需要知道,T 是怎么展开的,如果 T -> a |b ,P->c|d , 那当串以a或b开头的时候,我们显然需要选择A →T ,而当串以c或d开头的时候,就应该选择A->P 这个生成式了。也就是说,我们需要知道T这个分支和P这个分支,都可以用什么终结字符开头。因此我们需要计算每个生成式的开始记号的集合,也就是First集合。
下面给出First集合的算法:
exp→exp addop term | term addop→ +| - term →term mulop factor | factor mulop→∗|/ factor →(exp)|<number>
把它分解后变成
(1) exp→exp addop term (2) exp→term (3) addop→+ (4) addop→- (5) term→term mulop factor (6) term→factor (7) mulop→∗ (8) mulop→/ (9) factor→(exp) (10) factor→<number>
First(mulop)={*,/}
First(addop)={+,-}
First(factor)={(,<number>}
term的分支一边是term自己(就是说把term的First内容加到本身,不对自己产生变化),一边是factor(把factor的first集合内容加到term的first集合中),因此First(term)=First(factor) 同理First(exp)=First(term)
(二)Follow集合
A→Tb | P T→ε | a P→c
我们知道First(T) = {ε , a} Frist(P) = {c},当遇到a开头的串的时候,选择A→Tb,遇到c开头的串,选择 A-> P
A→Tb | P →(ε│a)b | P → (b| ab) | c
也就是说,当串以b开头的时候,其实选择的也是A→Tb
2的推导: S->EAT, A可以用…U代替,S->E…UT,所以A后面出现的终止符和U后面出现的终止符一样
2和3可得出: S->…U,那么Follow(S)的元素就在Follow(U)中,所以$在Follow(U)中
还是刚才的例子:
(1) exp→exp addop term (2) exp→term (3) addop→+ (4) addop→- (5) term→term mulop factor (6) term→factor (7) mulop→∗ (8) mulop→/ (9)factor→(exp) (10) factor→<number>
Exp为开始符号,所以把$放入Follow(exp)中,由式(1)知First(addop)要加入Follow(exp)中,此时Follow(exp)={+,-,$},同理,Follow(addop)={(,number},由式(2),把Follow(exp)加入到Follow(term)中……
(三) 从First,Follow到预测分析表
由First集合和Follow集合就可以得出我们需要的预测分析表了,先来感官性地认识一下:
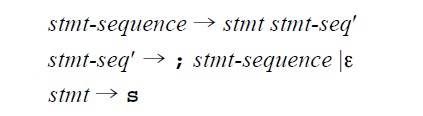
我们可以看到表格的Y方向是所有的非终结符(也就是所有生成式的左边部分的集合),X方向是所有终结符。
表格的每一项表示,当我目前在N这个非终结符,遇到T这个终结符之后,应该选择的生成式。 比如在stmt时候,如果遇到s,则选择stmt->s这个生成式。
从开始符号出发,每遇到一个输入,就判断往哪边走,最后走完为止,如果中间没有路可以走了,就说明语法有错。
下面来看预测分析表是怎么生成的。其实跟刚才First集合和Follow集合的思路一致。
就是正常的话直接看终结符,在哪个分支就往哪个分支走。但如果这个分支的First集合里有ε,那么需要看它后面的终止字符集合。
例子:
E→nE′ E′→ +nE′ | ε
First(E) = { n }
First(E’)= { + , ε}
Follow(E) = Follow(E’) = {$}
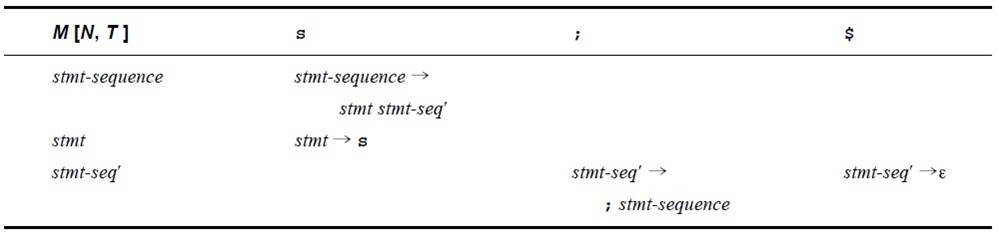
| M[N,T] | n | + | $ |
| E | E→nE′ | ||
| E' | E′→ +nE′ | E′→ε |
根据它来做的出栈入栈如下,比如分析 3+4=5(栈中的#只是为了计算结果,可以不理)
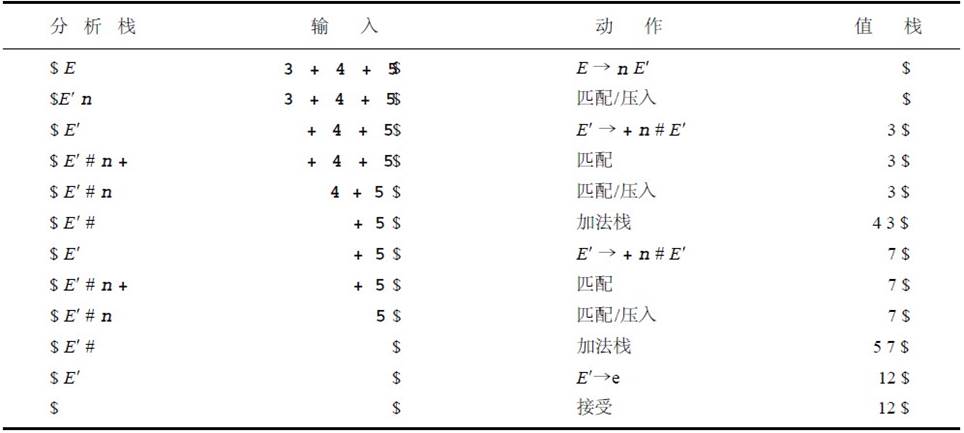
首先把$和开始字符E入栈,然后读取输入串。第一个字符是3,也就是n,M[E,n]是E→nE′,所以我们把E出栈,把n和E’入栈。从右到左入栈,即先入E’,再入n。这个时候,输入n和栈顶n匹配,把n出栈,读取字符串的下一个字符,即+,栈顶的E'遇到+根据表格知道应该选择E′→ +nE′ ,把E’出栈,E’,n,+入栈,+和输入的+匹配,出栈,顶端为E’.......依次下去,直到匹配结束。
编译原理LL(1)文法的更多相关文章
- 【编译原理】LL1文法语法分析器
上篇文章[编译原理]语法分析--自上向下分析 分析了LL1语法,文章最后说给出栗子,现在补上去. 说明: 这个语法分析器是利用LL1分析方法实现的. 预测分析表和终结符以及非终结符都是针对一个特定文法 ...
- 编译原理(一)绪论概念&文法与语言
绪论概念&文法与语言 以老师PPT为标准,借鉴部分教材内容,AlvinZH学习笔记. 绪论基本概念 1. 低级语言:字位码.机器语言.汇编语言.与特定的机器有关,功效高,但使用复杂.繁琐.费时 ...
- 《编译原理》-用例题理解-自顶向下语法分析及 FIRST,FOLLOW,SELECT集,LL(1)文法
<编译原理>-用例题理解-自顶向下语法分析及 FIRST,FOLLOW,SELECT集,LL(1)文法 此编译原理确定某高级程序设计语言编译原理,理论基础,学习笔记 本笔记是对教材< ...
- Java 实现《编译原理》简单-语法分析功能-LL(1)文法 - 程序解析
Java 实现<编译原理>简单-语法分析功能-LL(1)文法 - 程序解析 编译原理学习,语法分析程序设计 (一)要求及功能 已知 LL(1) 文法为: G'[E]: E→TE' E'→+ ...
- 编译原理实验之SLR1文法分析
---内容开始--- 这是一份编译原理实验报告,分析表是手动造的,可以作为借鉴. 基于 SLR(1) 分析法的语法制导翻译及中间代码生成程序设计原理与实现1 .理论传授语法制导的基本概念,目标代码结 ...
- 跟vczh看实例学编译原理——三:Tinymoe与无歧义语法分析
文章中引用的代码均来自https://github.com/vczh/tinymoe. 看了前面的三篇文章,大家应该基本对Tinymoe的代码有一个初步的感觉了.在正确分析"print ...
- Compiler Theory(编译原理)、词法/语法/AST/中间代码优化在Webshell检测上的应用
catalog . 引论 . 构建一个编译器的相关科学 . 程序设计语言基础 . 一个简单的语法制导翻译器 . 简单表达式的翻译器(源代码示例) . 词法分析 . 生成中间代码 . 词法分析器的实现 ...
- 【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集
近来复习编译原理,语法分析中的自上而下LL(1)分析法,需要构造求出一个文法的FIRST和FOLLOW集,然后构造分析表,利用分析表+一个栈来做自上而下的语法分析(递归下降/预测分析),可是这个FIR ...
- 必要的软件架构师——编译原理·语法
最近软测试.我观看进程的视频! 发现里面有很多内容已经在自我不错的接触过程.而占80%比例! 但其中的一部分.我很奇怪的一部分.研究,在这里,将我研究的内容整理分享给大家! 编译原理: 首先,我第一眼 ...
随机推荐
- CodeForces 572D Minimization(DP)
题意翻译 给定数组AAA 和值kkk ,你可以重排AAA 中的元素,使得∑i=1n−k∣Ai−Ai+k∣\displaystyle\sum_{i=1}^{n-k} |A_i-A_{i+k}|i=1∑n ...
- CDI(Weld)高级<4> Event(事件) (转)
目录[-] 1. Event payload(事件的有效载入) 2. Event observers(event的观察者) 3. Event producers(event生产者) 4.Annotat ...
- python, C++, C# 计算速度简单对比
有个简单的运算, ; ; ; i < n ; i ++) { ; j < n; j ++) { lResult += (ulong) ( i * j ); } } return lResu ...
- 【转】Leader-Follower线程模型
上图就是L/F多线程模型的状态变迁图,共6个关键点: (1)线程有3种状态:领导leading,处理processing,追随following (2)假设共N个线程,其中只有1个leading线程( ...
- .NET Core调用WCF的最佳实践
现在.NET Core貌似很火,与其他.NET开发者交流不说上几句.NET Core都感觉自己落伍了一样.但是冷静背后我们要也看到.NET Core目前还有太多不足,别的不多说,与自家的服务框架WCF ...
- ASP.NET WebAPI 测试文档 (Swagger)
ASP.NET WebAPI使用Swagger生成测试文档 SwaggerUI是一个简单的Restful API测试和文档工具.简单.漂亮.易用(官方demo).通过读取JSON配置显示API .项目 ...
- Android优化之内存优化倒计时篇
本文来自网易云社区 作者:聂雷震 本篇文章介绍的内容是如何在安卓手机上实现高效的倒计时效果,这个高效有两个标准:1.刷新频率足够高,让用户觉得这个倒计时的确是倒计时,而不是幻灯片:2.不能占用太多的内 ...
- RabbitMq初探——消息均发
消息均发 前言 由前文 RabbitMq初探——消息分发 可知,rabbitmq自带分发机制——消息会按顺序的投放到该队列下的多个消费者,例如1,3,5投放消费者C1,2,4,6投放消费者C2. 这就 ...
- 【bzoj 2716】[Violet 3]天使玩偶 (CDQ+树状数组)
题目描述 Ayu 在七年前曾经收到过一个天使玩偶,当时她把它当作时间囊埋在了地下.而七年后 的今天,Ayu 却忘了她把天使玩偶埋在了哪里,所以她决定仅凭一点模糊的记忆来寻找它. 我们把 Ayu 生活的 ...
- SDN定义网络
http://edu.51cto.com/course/course_id-4466.html http://edu.51cto.com/course/course_id-4497.html