Python(序列化json,pickle,shelve)
序列化
参考:https://www.cnblogs.com/yuanchenqi/articles/5732581.html
# dic = str({'1':'111'})
#
# f = open('test', 'w')
# f.write(dic) #必须是str类型,不是set
file = open('test', 'r')
data = file.read()#data是字符串
print(eval(data)[''])#用eval将字符串类型的data转成dict类型
print(type(data))
print(type(eval(data)))
执行被注释的程序可得如下文件:
{'': ''}
执行未被注释的文件可得:
111
<class 'str'>
<class 'dict'> Process finished with exit code 0
可以看出需要通过eval将字符串类型的数据转成dict类型的。
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
1、json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串)
(1)json.dumps()函数是将一个Python数据类型列表进行json格式的编码(可以这么理解,json.dumps()函数是将字典转化为字符串)
(2)json.loads()函数是将json格式数据转换为字典(可以这么理解,json.loads()函数是将字符串转化为字典)
2、json.dump()和json.load()主要用来读写json文件函数
参考:https://www.cnblogs.com/xiaomingzaixian/p/7286793.html
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
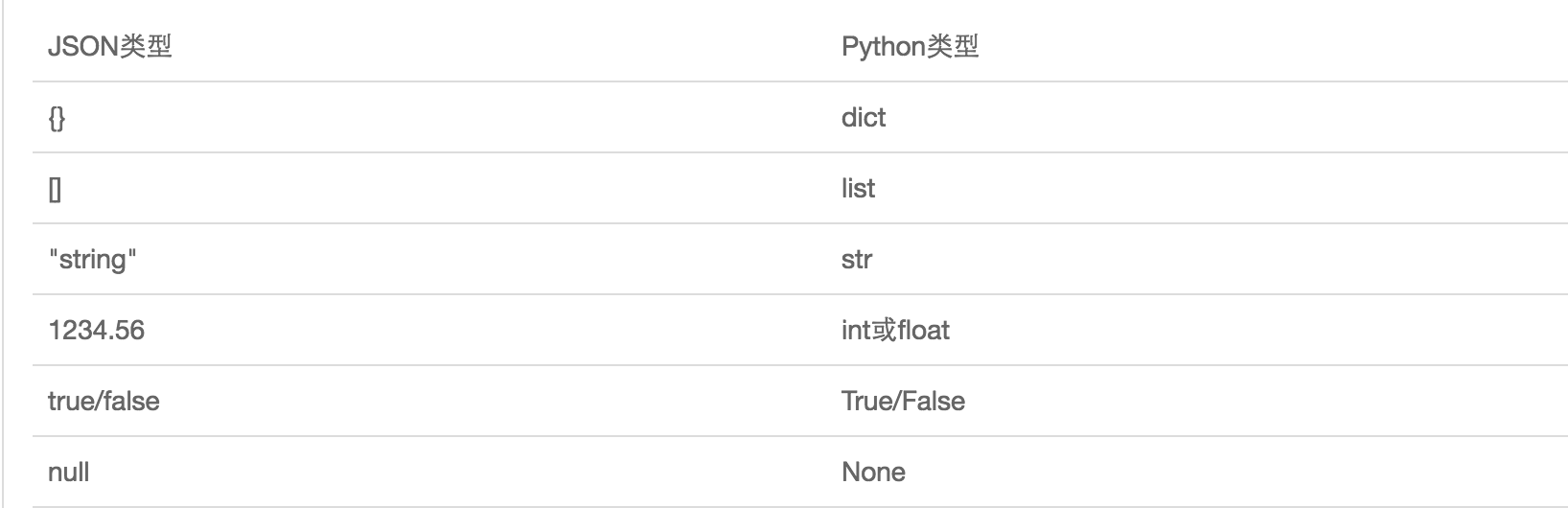
json_test.py(序列化)
import json
dict = {'name':'nizhipeng','age':''}
data = json.dumps(dict)#添加序列化内容
f = open('JSON_text', 'w')
f.write(data)
f.close()
生成文件JSON_test
{"age": "", "name": "nizhipeng"}
JSON_load.py(反序列化)
import json
f = open('JSON_text', 'r')
data = f.read()
data = json.loads(data)
print(data['name'])
执行结果:
nizhipeng Process finished with exit code 0
Pickle
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
pickle_test.py
import pickle def foo():
print('ok') data = pickle.dumps(foo)#添加序列化内容
f = open('pickle_text', 'wb') #b为二进制
f.write(data)
f.close()
生成pickle_text
pickle_load.py
import pickle def foo():#必须有
print('ok') f = open('pickle_text', 'rb')#二进制形式 #注意是w是写入str,wb是写入bytes,j是'bytes' data = f.read() print(type(data)) data()
执行结果:
<class 'function'>
ok Process finished with exit code 0
pickle可将函数序列化(只需了解一下)。但是函数内存地址已发生改变,所以需要在pickle_load.py处,重新再写一遍。
简化的方法dump,load
json_test.py
import json
dict = {'name':'nizhipeng','age':''}
f = open('json_text', 'w')
# data = json.dumps(dict)#添加序列化内容
# f.write(data)
json.dump(dict, f)#等价于以上两行
f.close()
用dump代替dumps。
生成json_text文件。
json_load.py
import json
f = open('json_text', 'r')
# data = f.read()
# data = json.loads(data)
data = json.load(f)#等价与以上两步
print(data['name'])
执行结果:
nizhipeng Process finished with exit code 0
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f = shelve.open('shelve_text')
#
f['info'] = {'name':'nizhipeng', 'age':''}
f['shopping'] = {'name':'alex', 'price':'-18'}
data = f.get('info') #info是键
print(data)
执行会生成一个shelve_text文件
{'name': 'nizhipeng', 'age': ''}
Process finished with exit code 0
补充(字典)
d = {'name':'nizhipeng', 'age':''}
print(d['name'])
print(d.get('name'))
print(d.get('sex', 'male'))#如果没有则返回后面的内容,本身没有sex键
执行结果:
nizhipeng
nizhipeng
male Process finished with exit code 0
Python(序列化json,pickle,shelve)的更多相关文章
- python学习之文件读写,序列化(json,pickle,shelve)
python基础 文件读写 凡是读写文件,所有格式类型都是字符串形式传输 只读模式(默认) r f=open('a.txt','r')#文件不存在会报错 print(f.read())#获取到文件所 ...
- Day 4-5 序列化 json & pickle &shelve
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 反序列化: 把字符转成内存里的数据类型. 用于序列化的两个模块.他 ...
- python 序列化 json pickle
python的pickle模块实现了基本的数据序列和反序列化.通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储:通过pickle模块的反序列化操作,我们能够从文件 ...
- python模块--json \ pickle \ shelve \ XML模块
一.json模块 之前学习过的eval内置方法可以将一个字符串转成一个python对象,不过eval方法时有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,e ...
- python序列化_json,pickle,shelve模块
序列化 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes 把内存数据 转成字符,叫序列化 把字符 转成内存数据,叫反序列化 模块 ...
- 序列化 json pickle shelve configparser
一 什么是 序列化 在我们存储数据或者 网络传输数据的时候,需要对我们的 对象进行处理,把对象处理成方便我们存储和传输的 数据格式,这个过程叫序列化,不同的序列化,结果也不相同,但是目的是一样的,都是 ...
- python序列化: json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- python 全栈开发,Day25(复习,序列化模块json,pickle,shelve,hashlib模块)
一.复习 反射 必须会 必须能看懂 必须知道在哪儿用 hasattr getattr setattr delattr内置方法 必须能看懂 能用尽量用__len__ len(obj)的结果依赖于obj. ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
随机推荐
- The Process of Google Hiring
[The Process of Google Hiring] 1.keynote 1: The Google hiring process is designed to hire the most t ...
- 虚拟机Mac系统中VMware_tools安装和vm共享文件夹的设置(转)
原文来源: http://wenku.baidu.com/link?url=KRgfG40q2SEwZfde9xA7HVKjCsFBkMcf83tyellnzsHYZ_ErU1hWpVmTHYZem0 ...
- js小例子之二级联动
联动原理 当用户点击省级的下拉选项,选择所在省,下一个下拉选项里的选项,则变成用户选择省下的所有市的信息,不会出现其它省市的信息. 省市数据 把省市数据,保存在js文件中,以json形式保存,以便读取 ...
- lammps模拟化学反应(1)
1. Can I use lammps to chemical reaction systems?Please note that you can only get as good an answer ...
- 611. Valid Triangle Number三角形计数
[抄题]: 给定一个整数数组,在该数组中,寻找三个数,分别代表三角形三条边的长度,问,可以寻找到多少组这样的三个数来组成三角形? [暴力解法]: 全部都用for循环 时间分析: 空间分析: [思维问题 ...
- h5 时间控件问题,怎么设置type =datetime-local 的值
在js中设置自定义时间到date控件的方法: 1.在html5中定义时间控件 <input type="date" id="datePicker" val ...
- gd库已打开,验证码不显示
ob_start(); ob_clean();
- [SoapUI] 如何让gzip和chunked的response显示出来 [设置Accept-Encoding为deflate]
如果response的Content-Encoding是gzip或者Transfer-Encoding是chunked,在SoapUI里面是无法显示出来的. 解决办法:在Request的Header里 ...
- Java设计模式(4)——单例模式
转载:http://wiki.jikexueyuan.com/project/java-design-pattern/singleton-pattern.html 单例模式根据实例化对象时机的不同分为 ...
- CodeForces 686A Free Ice Cream (水题模拟)
题意:给定初始数量的冰激凌,然后n个操作,如果是“+”,那么数量就会增加,如果是“-”,如果现有的数量大于等于要减的数量,那么就减掉,如果小于, 那么孩子就会离家.问你最后剩下多少冰激凌,和出走的孩子 ...