tensorflow中协调器 tf.train.Coordinator 和入队线程启动器 tf.train.start_queue_runners
TensorFlow的Session对象是支持多线程的,可以在同一个会话(Session)中创建多个线程,并行执行。在Session中的所有线程都必须能被同步终止,异常必须能被正确捕获并报告,会话终止的时候, 队列必须能被正确地关闭。
TensorFlow提供了两个类来实现对Session中多线程的管理:tf.Coordinator和 tf.QueueRunner,这两个类往往一起使用。
Coordinator类用来管理在Session中的多个线程,可以用来同时停止多个工作线程并且向那个在等待所有工作线程终止的程序报告异常,该线程捕获到这个异常之后就会终止所有线程。使用 tf.train.Coordinator()来创建一个线程管理器(协调器)对象。
QueueRunner类用来启动tensor的入队线程,可以用来启动多个工作线程同时将多个tensor(训练数据)推送入文件名称队列中,具体执行函数是 tf.train.start_queue_runners , 只有调用 tf.train.start_queue_runners 之后,才会真正把tensor推入内存序列中,供计算单元调用,否则会由于内存序列为空,数据流图会处于一直等待状态。
tf中的数据读取机制如下图:
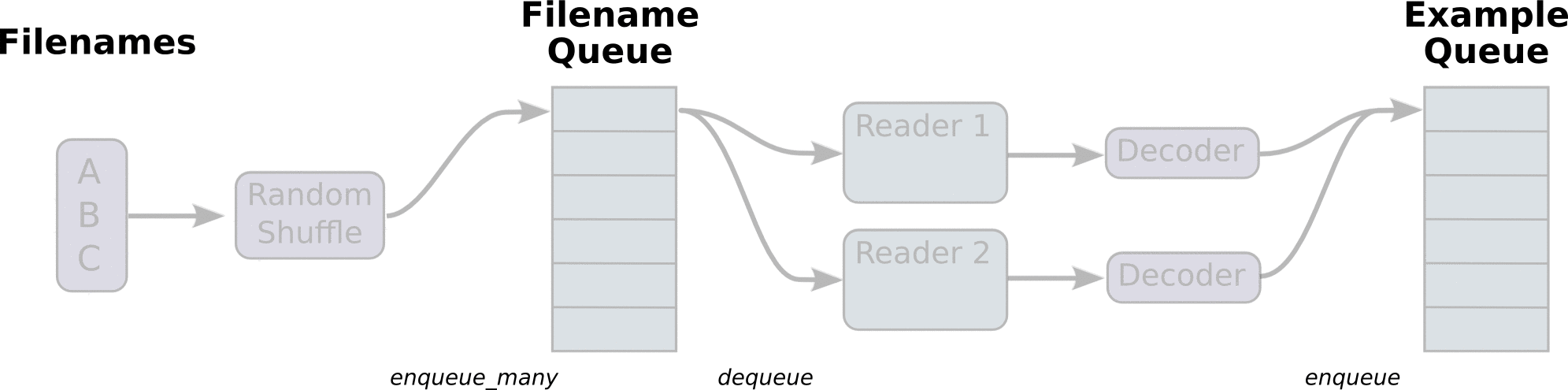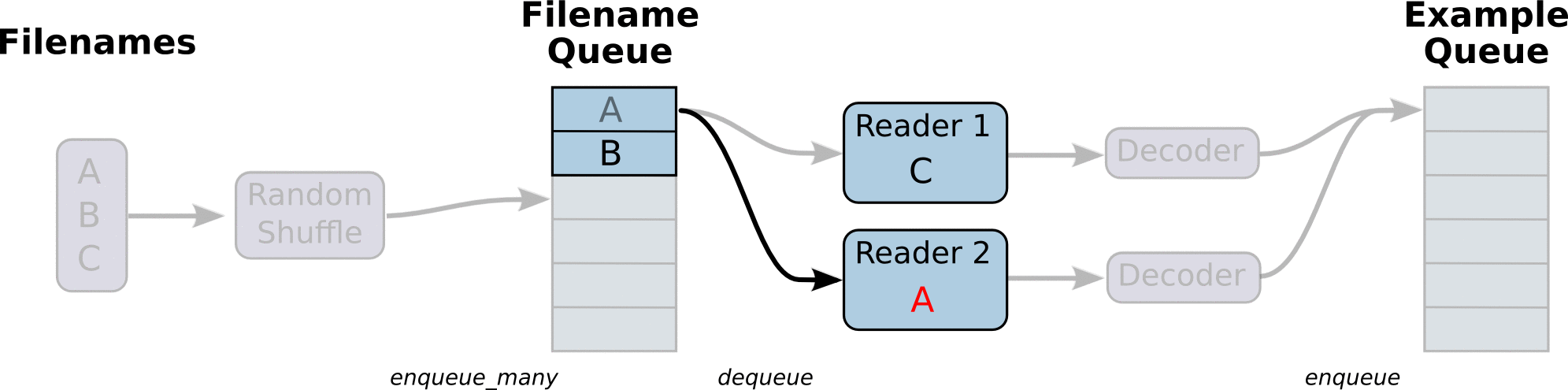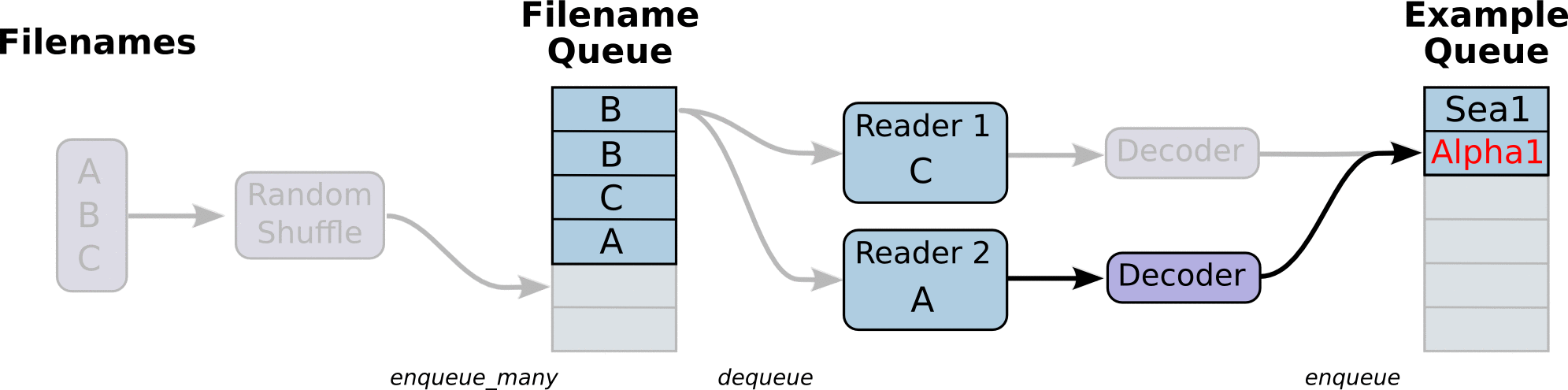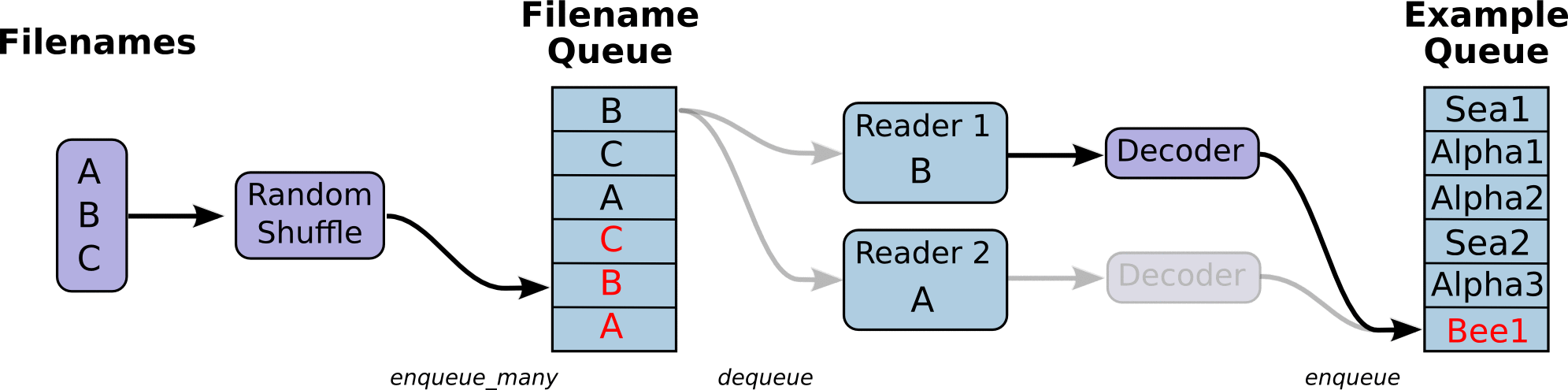
- 调用 tf.train.slice_input_producer,从 本地文件里抽取tensor,准备放入Filename Queue(文件名队列)中;
- 调用 tf.train.batch,从文件名队列中提取tensor,使用单个或多个线程,准备放入文件队列;
- 调用 tf.train.Coordinator() 来创建一个线程协调器,用来管理之后在Session中启动的所有线程;
- 调用tf.train.start_queue_runners, 启动入队线程,由多个或单个线程,按照设定规则,把文件读入Filename Queue中。函数返回线程ID的列表,一般情况下,系统有多少个核,就会启动多少个入队线程(入队具体使用多少个线程在tf.train.batch中定义);
- 文件从 Filename Queue中读入内存队列的操作不用手动执行,由tf自动完成;
- 调用sess.run 来启动数据出列和执行计算;
- 使用 coord.should_stop()来查询是否应该终止所有线程,当文件队列(queue)中的所有文件都已经读取出列的时候,会抛出一个 OutofRangeError 的异常,这时候就应该停止Sesson中的所有线程了;
- 使用coord.request_stop()来发出终止所有线程的命令,使用coord.join(threads)把线程加入主线程,等待threads结束。
以上对列(Queue)和 协调器(Coordinator)操作示例:
# -*- coding:utf-8 -*-
import tensorflow as tf
import numpy as np
# 样本个数
sample_num=5
# 设置迭代次数
epoch_num = 2
# 设置一个批次中包含样本个数
batch_size = 3
# 计算每一轮epoch中含有的batch个数
batch_total = int(sample_num/batch_size)+1
# 生成4个数据和标签
def generate_data(sample_num=sample_num):
labels = np.asarray(range(0, sample_num))
images = np.random.random([sample_num, 224, 224, 3])
print('image size {},label size :{}'.format(images.shape, labels.shape))
return images,labels
def get_batch_data(batch_size=batch_size):
images, label = generate_data()
# 数据类型转换为tf.float32
images = tf.cast(images, tf.float32)
label = tf.cast(label, tf.int32)
#从tensor列表中按顺序或随机抽取一个tensor准备放入文件名称队列
input_queue = tf.train.slice_input_producer([images, label], num_epochs=epoch_num, shuffle=False)
#从文件名称队列中读取文件准备放入文件队列
image_batch, label_batch = tf.train.batch(input_queue, batch_size=batch_size, num_threads=2, capacity=64, allow_smaller_final_batch=False)
return image_batch, label_batch
image_batch, label_batch = get_batch_data(batch_size=batch_size)
with tf.Session() as sess:
# 先执行初始化工作
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
# 开启一个协调器
coord = tf.train.Coordinator()
# 使用start_queue_runners 启动队列填充
threads = tf.train.start_queue_runners(sess, coord)
try:
while not coord.should_stop():
print '************'
# 获取每一个batch中batch_size个样本和标签
image_batch_v, label_batch_v = sess.run([image_batch, label_batch])
print(image_batch_v.shape, label_batch_v)
except tf.errors.OutOfRangeError: #如果读取到文件队列末尾会抛出此异常
print("done! now lets kill all the threads……")
finally:
# 协调器coord发出所有线程终止信号
coord.request_stop()
print('all threads are asked to stop!')
coord.join(threads) #把开启的线程加入主线程,等待threads结束
print('all threads are stopped!')输出:
************
((3, 224, 224, 3), array([0, 1, 2], dtype=int32))
************
((3, 224, 224, 3), array([3, 4, 0], dtype=int32))
************
((3, 224, 224, 3), array([1, 2, 3], dtype=int32))
************
done! now lets kill all the threads……
all threads are asked to stop!
all threads are stopped!
以上程序在 tf.train.slice_input_producer 函数中设置了 num_epochs 的数量, 所以在文件队列末尾有结束标志,读到这个结束标志的时候抛出 OutofRangeError 异常,就可以结束各个线程了。
如果不设置 num_epochs 的数量,则文件队列是无限循环的,没有结束标志,程序会一直执行下去。
tensorflow中协调器 tf.train.Coordinator 和入队线程启动器 tf.train.start_queue_runners的更多相关文章
- tensorflow|tf.train.slice_input_producer|tf.train.Coordinator|tf.train.start_queue_runners
#### ''' tf.train.slice_input_producer :定义样本放入文件名队列的方式[迭代次数,是否乱序],但此时文件名队列还没有真正写入数据 slice_input_prod ...
- tfsenflow队列|tf.train.slice_input_producer|tf.train.Coordinator|tf.train.start_queue_runners
#### ''' tf.train.slice_input_producer :定义样本放入文件名队列的方式[迭代次数,是否乱序],但此时文件名队列还没有真正写入数据 slice_input_pr ...
- TensorFlow中的显存管理器——BFC Allocator
背景 作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] 使用GPU训练时,一次训练任务无论是模型参数还是中间结果都需要占用大量显存.为了 ...
- 深度学习原理与框架-Tfrecord数据集的读取与训练(代码) 1.tf.train.batch(获取batch图片) 2.tf.image.resize_image_with_crop_or_pad(图片压缩) 3.tf.train.per_image_stand..(图片标准化) 4.tf.train.string_input_producer(字符串入队列) 5.tf.TFRecord(读
1.tf.train.batch(image, batch_size=batch_size, num_threads=1) # 获取一个batch的数据 参数说明:image表示输入图片,batch_ ...
- TensorFlow中数据读取—如何载入样本
考虑到要是自己去做一个项目,那么第一步是如何把数据导入到代码中,何种形式呢?是否需要做预处理?官网中给的实例mnist,数据导入都是写好的模块,那么自己的数据呢? 一.从文件中读取数据(CSV文件.二 ...
- tensorflow中数据批次划分示例教程
1.简介 将数据划分成若干批次的数据,使用的函数主要有: tf.train.slice_input_producer(tensor_list,shuffle=True,seed=None,capaci ...
- 深度学习原理与框架-Tfrecord数据集的制作 1.tf.train.Examples(数据转换为二进制) 3.tf.image.encode_jpeg(解码图片加码成jpeg) 4.tf.train.Coordinator(构建多线程通道) 5.threading.Thread(建立单线程) 6.tf.python_io.TFR(TFR读入器)
1. 配套使用: tf.train.Examples将数据转换为二进制,提升IO效率和方便管理 对于int类型 : tf.train.Examples(features=tf.train.Featur ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数(转)
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
- tensorflow中 tf.train.slice_input_producer 和 tf.train.batch 函数
tensorflow数据读取机制 tensorflow中为了充分利用GPU,减少GPU等待数据的空闲时间,使用了两个线程分别执行数据读入和数据计算. 具体来说就是使用一个线程源源不断的将硬盘中的图片数 ...
随机推荐
- golang 复制对象的正确做法
需求 实际运用种,传参是一对象指针,现在如何最简便地复制一对象? 实现 坑:&* 先拿到值再指针? package main import ( "time" " ...
- pssh批量远程管理工具
Linux下批量管理工具pssh使用记录 pssh是一款开源的软件,使用python实现,用于批量ssh操作大批量机器:pssh是一个可以在多台服务器上执行命令的工具,同时支持拷贝文件,是同类工具 ...
- Mybatis入门和简单Demo
一.Mybatis的诞生 回顾下传统的数据库开发,JDBC和Hibernate是使用最普遍的技术,但这两种ORM框架都存在一定的局限性: JDBC:最原生的技术,简单易学,执行速度快,效率高,适合大数 ...
- 内置函数——format
说明: 1. 函数功能将一个数值进行格式化显示. 2. 如果参数format_spec未提供,则和调用str(value)效果相同,转换成字符串格式化. >>> format(3.1 ...
- 新版samba安装过程
yum install samba samba-client samba-swat cp -p /etc/samba/smb.conf /etc/samba/smb.conf.orig /bin ...
- 1、安装electron
安装electron安装并非一帆风顺,我有FQ哈,所以网络方面我就不说了,你们不行的话,可以用cnpm,我说的是另一个问题 我是这样解决的,用以下命令就好了 sudo npm install -g e ...
- 2018-2019 ACM-ICPC, Asia East Continent Finals Solution
D. Deja vu of … Go Players 签. #include <bits/stdc++.h> using namespace std; int t, n, m; int m ...
- jquery实现ajax跨域请求
1.跨域问题: 是因为浏览器的同源策略是对ajax请求进行阻拦了,但是不是所有的请求都给做跨域,像是一般的href属性,a标签什么的都不拦截. 如: 项目一:p1.html <body> ...
- Spring MVC 复习笔记04
复习 springmvc框架: DispatcherServlet前端控制器:接收request,进行response HandlerMapping处理器映射器:根据url查找Handler.(可以通 ...
- window 下相关命令
1. 启动window服务(各种应用启动设置的地方)命令方式: 1). window 按钮(输入CMD的地方)处输入:services.msc ,然后执行. // 输入命令正确,上面的待选框中会出 ...