Spark SQL的整体实现逻辑
1、sql语句的模块解析
当我们写一个查询语句时,一般包含三个部分,select部分,from数据源部分,where限制条件部分,这三部分的内容在sql中有专门的名称:
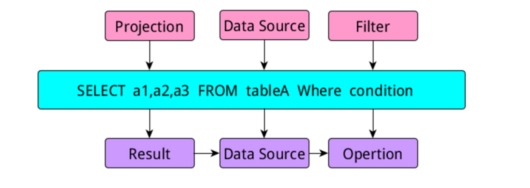
当我们写sql时,如上图所示,在进行逻辑解析时会把sql分成三个部分,project,DataSource,Filter模块,当生成执行部分时又把他们称为:Result模块、
DataSource模块和Opertion模块。
那么在关系数据库中,当我们写完一个查询语句进行执行时,发生的过程如下图所示:

整个执行流程是:query -> Parse -> Bind -> Optimize -> Execute
1、写完sql查询语句,sql的查询引擎首先把我们的查询语句进行解析,也就是Parse过程,解析的过程是把我们写的查询语句进行分割,把project,DataSource和Filter三个部分解析出来从而形成一个逻辑解析tree,在解析的过程中还会检查我们的sql语法是否有错误,比如缺少指标字段、数据库中不包含这张数据表等。当发现有错误时立即停止解析,并报错。当顺利完成解析时,会进入到Bind过程。
2、Bind过程,通过单词我们可看出,这个过程是一个绑定的过程。为什么需要绑定过程?这个问题需要我们从软件实现的角度去思考,如果让我们来实现这个sql查询引擎,我们应该怎么做?他们采用的策略是首先把sql查询语句分割,分割不同的部分,再进行解析从而形成逻辑解析tree,然后需要知道我们需要取数据的数据表在哪里,需要哪些字段,执行什么逻辑,这些都保存在数据库的数据字典中,因此bind过程,其实就是把Parse过程后形成的逻辑解析tree,与数据库的数据字典绑定的过程。绑定后会形成一个执行tree,从而让程序知道表在哪里,需要什么字段等等
3、完成了Bind过程后,数据库查询引擎会提供几个查询执行计划,并且给出了查询执行计划的一些统计信息,既然提供了几个执行计划,那么有比较就有优劣,数据库会根据这些执行计划的统计信息选择一个最优的执行计划,因此这个过程是Optimize(优化)过程。
4、选择了一个最优的执行计划,那么就剩下最后一步执行Execute,最后执行的过程和我们解析的过程是不一样的,当我们知道执行的顺序,对我们以后写sql以及优化都是有很大的帮助的.执行查询后,他是先执行where部分,然后找到数据源之数据表,最后生成select的部分,我们的最终结果。执行的顺序是:operation->DataSource->Result
虽然以上部分对SparkSQL没有什么联系,但是知道这些,对我们理解SparkSQL还是很有帮助的。
2、SparkSQL框架的架构
要想对这个框架有一个清晰的认识,首先我们要弄清楚,我们为什么需要sparkSQL呢?个人建议一般情况下在写sql能够直接解决的问题就不要使用sparkSQL,如果想刻意使用sparkSQL,也不一定能够加快开发的进程。使用sparkSQL是为了解决一般用sql不能解决的复杂逻辑,使用编程语言的优势来解决问题。我们使用sparkSQL一般的流程如下图:

如上图所示,一般情况下分为两个部分:a、把数据读入到sparkSQL中,sparkSQL进行数据处理或者算法实现,然后再把处理后的数据输出到相应的输出源中。
1、同样我们也是从如果让我们开发,我们应该怎么做,需要考虑什么问题来思考这个问题。
a、第一个问题是,数据源有几个,我们可能从哪些数据源读取数据?现在sparkSQL支持很多的数据源,比如:hive数据仓库、json文件,.txt,以及orc文件,同时现在还支持jdbc从关系数据库中取数据。功能很强大。
b、还一个需要思考的问题是数据类型怎么映射啊?我们知道当我们从一个数据库表中读入数据时,我们定义的表结构的字段的类型和编程语言比如scala中的数据类型映射关系是怎样的一种映射关系?在sparkSQL中有一种来解决这个问题的方法,来实现数据表中的字段类型到编程语言数据类型的映射关系。这个以后详细介绍,先了解有这个问题就行。
c、数据有了,那么在sparkSQL中我们应该怎么组织这些数据,需要什么样的数据结构呢,同时我们对这些数据都可以进行什么样的操作?sparkSQL采用的是DataFrame数据结构来组织读入到sparkSQL中的数据,DataFrame数据结构其实和数据库的表结构差不多,数据是按照行来进行存储,同是还有一个schema,就相当于数据库的表结构,记录着每一行数据属于哪个字段。
d、当数据处理完以后,我们需要把数据放入到什么地方,并切以什么样的格式进行对应,这个a和b要解决的问题是相同的。
2、sparkSQL对于以上问题的实现逻辑也很明确,从上图已经很清楚,主要分为两个阶段,每个阶段都对应一个具体的类来实现。
a、 对于第一个阶段,sparkSQL中存在两个类来解决这些问题:HiveContext,SQLContext,同时hiveContext继承了SQLContext的所有方法,同时又对其进行了扩展。因为我们知道, hive和mysql的查询还是有一定的差别的。HiveContext只是用来处理从hive数据仓库中读入数据的操作,SQLContext可以处理sparkSQL能够支持的剩下的所有的数据源。这两个类处理的粒度是限制在对数据的读写上,同时对表级别的操作上,比如,读入数据、缓存表、释放缓存表表、注册表、删除注册的表、返回表的结构等的操作。
b、sparkSQL处理读入的数据,采用的是DataFrame中提供的方法。因为当我们把数据读入到sparkSQL中,这个数据就是DataFrame类型的。同时数据都是按照Row进行存储的。其中 DataFrame中提供了很多有用的方法。以后会细说。
c、在spark1.6版本以后,又增加了一个类似于DataFrame的数据结构Dataset,增加此数据结构的目的是DataFrame有软肋,他只能处理按照Row进行存储的数据,并且只能使用DataFrame中提供的方法,我们只能使用一部分RDD提供的操作。实现Dataset的目的就是让我们能够像操作RDD一样来操作sparkSQL中的数据。
d、其中还有一些其他的类,但是现在在sparkSQL中最主要的就是上面的三个类,其他类以后碰到了会慢慢想清楚。
3、sparkSQL的hiveContext和SQLContext的运行原理
hiveContext和SQLContext与我第一部分讲到的sql语句的模块解析实现的原理其实是一样的,采用了同样的逻辑过程,并且网上有好多讲这一块的,就直接粘贴复制啦!!
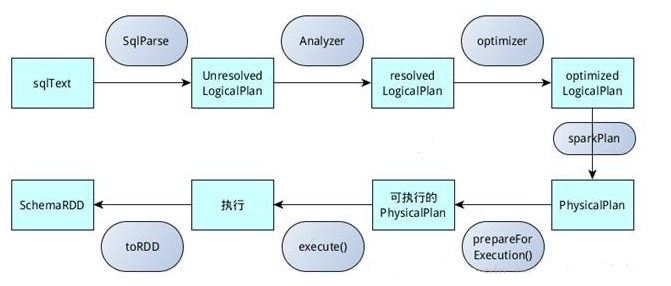
sqlContext总的一个过程如下图所示:
1.SQL语句经过SqlParse解析成UnresolvedLogicalPlan;
2.使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
3.使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan;
4.使用SparkPlan将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.生成SchemaRDD。
在整个运行过程中涉及到多个SparkSQL的组件,如SqlParse、analyzer、optimizer、SparkPlan等等
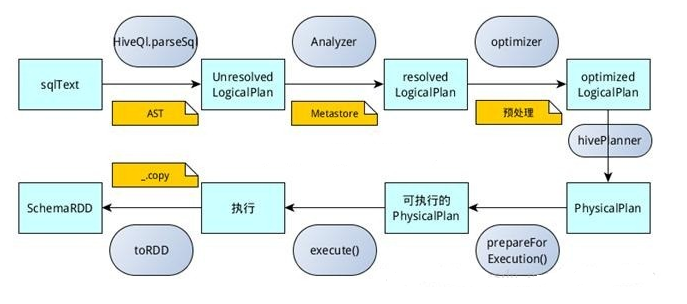
hiveContext总的一个过程如下图所示:
1.SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树,然后再进行解析;
2.使用analyzer结合数据hive、源数据Metastore(新的catalog)进行绑定,生成resolved LogicalPlan;
3.使用optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理;
4.使用hivePlanner将LogicalPlan转换成PhysicalPlan;
5.使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
6.使用execute()执行可执行物理计划;
7.执行后,使用map(_.copy)将结果导入SchemaRDD。
Spark SQL的整体实现逻辑的更多相关文章
- Spark SQL / Catalyst 内部原理 与 RBO
原创文章,转载请务必将下面这段话置于文章开头处. 本文转发自技术世界,原文链接 http://www.jasongj.com/spark/rbo/ 本文所述内容均基于 2018年9月10日 Spark ...
- Spark SQL catalyst概述和SQL Parser的具体实现
之前已经对spark core做了较为深入的解读,在如今SQL大行其道的背景下,spark中的SQL不仅在离线batch处理中使用广泛,structured streamming的实现也严重依赖spa ...
- 第四篇:Spark SQL Catalyst源码分析之TreeNode Library
/** Spark SQL源码分析系列文章*/ 前几篇文章介绍了Spark SQL的Catalyst的核心运行流程.SqlParser,和Analyzer,本来打算直接写Optimizer的,但是发现 ...
- Spark SQL CLI 实现分析
背景 本文主要介绍了Spark SQL里眼下的CLI实现,代码之后肯定会有不少变动,所以我关注的是比較核心的逻辑.主要是对照了Hive CLI的实现方式,比較Spark SQL在哪块地方做了改动,哪些 ...
- Spark SQL整体架构
0.整体架构 注意:Spark SQL是Spark Core之上的一个模块,所有SQL操作最终都通过Catalyst翻译成类似的Spark程序代码被Spark Core调度执行,其过程也有Job.St ...
- spark sql的agg函数,作用:在整体DataFrame不分组聚合
.agg(expers:column*) 返回dataframe类型 ,同数学计算求值 df.agg(max("age"), avg("salary")) df ...
- Spark源码系列(九)Spark SQL初体验之解析过程详解
好久没更新博客了,之前学了一些R语言和机器学习的内容,做了一些笔记,之后也会放到博客上面来给大家共享.一个月前就打算更新Spark Sql的内容了,因为一些别的事情耽误了,今天就简单写点,Spark1 ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark SQL笔记——技术点汇总
目录 概述 原理 组成 执行流程 性能 API 应用程序模板 通用读写方法 RDD转为DataFrame Parquet文件数据源 JSON文件数据源 Hive数据源 数据库JDBC数据源 DataF ...
随机推荐
- 如何通过XAMPP来实现单个服务器上建多个网站
xampp 是一个非常方便的本地 apache + php + mysql 的调试环境,在本地安装测试 WordPress 等各种博客.论坛程序非常方便.今天我们来给大家介绍一下,如何使用 XAMPP ...
- linux安装oracle11g步骤
1. 修改用户限制 root用户:修改 /etc/security/limits.conf 文件,加上下面的参数 oracle soft nproc 2047 oracle hard nproc 16 ...
- Zookeeper(三)-- JAVA原生API
一.前提 jar包:zookeeper-3.4.9.jar,slf4j-api-1.6.1.jar,slf4j-log4j12-1.6.1.jar,log4j-1.2.15.jar 二.Demo pa ...
- 管理开机启动:systemd
一.CentOS7 systemd 介绍 在 CentOS7 中,使用 systemd 来管理其他服务是否开机启动,systemctl 是 systemd 服务的命令行工具 [root@localho ...
- ubuntu下code::blocks设置运行窗口为gnome命令行
code::blocks编译运行C++程序(F9)默认出现的运行串口在有鼠标的情况下进行粘贴还是很方便的,只要按下鼠标滑轮,位与剪切板中的数据就能粘贴到运行串口中.但是对于用笔记本而且没有鼠标地童鞋这 ...
- iOS-代码修改Info.plist文件
解决办法: 1.首先系统的Info.Plist文件是只读文件 并不能 写入.目前我个人是没有办法存入,官方属性 可以看到是readOnly 2.那么我们 就想代码修改Info.Plist文件怎么办呢, ...
- vue-学习笔记(更新中...)
vue学习笔记 2017-08-23 11:10:28 Vue实例: var vm = new Vue({ // 选项 }) 实例化Vue.Vue实例,构造函数Vue.创建一个Vue的根实例,Vue ...
- LeetCode——Sqrt(x)
Description: Implement int sqrt(int x). Compute and return the square root of x. 好好学习数学还是非常有用的,牛顿迭代法 ...
- 封装JDBC工具类
JDBC连接数据库基本的步骤是固定的,这样就可以考虑封装一个工具类来简化数据库操作. 封装时用到了Java中的properties配置文件,是以一种键值对的形式存在的,可以把连接数据库要动态的信息保存 ...
- EUI组件之Button
一.Button的常规使用 用到的按钮素材,分别为按钮的正常.按下.禁用图片 拖动一个Button到exml,并设置正常.按下.禁用.标签等属性 点击效果 其他: 1. 按钮的标签字体颜色大小怎么改变 ...