python中的内容编码
一、python编码简介
1)编码格式简介
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ASCII),ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,注:此处说的的是最少2个字节,可能更多。
UTF-8,是对Unicode编码的压缩和优化,不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(python3.x默认UTF-8)。
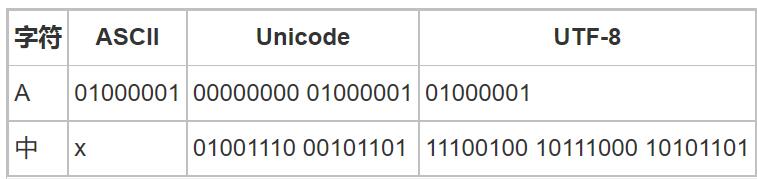
a="明"
# 查看a中的方法
print(dir(a))
# 显示a的数据类型
print(type(a))
# 显示a的码值
print(ord(a))
#
# 将码值转换成对应的字符
print(chr(26126))
# 明
a="明天"
# len-字符的长度
print(a.__len__())
# bytes的长度
print(a.encode("utf-8").__len__())
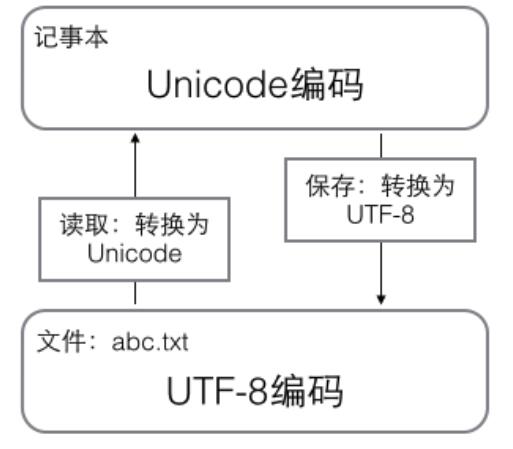
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
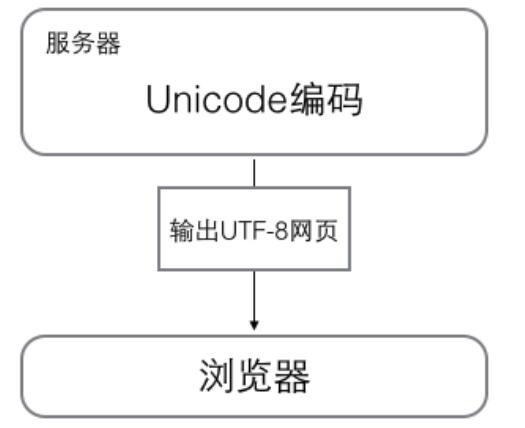
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器,所以你看到很多网页的源码上会有类似<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
2)byte
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes,bytes的每个字符都占有一个字节。反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
# 编码
a="ABC"
print(a.encode("utf-8"))
b="小明"
# 会报错,中文超出了ascii范围
# print(b.encode("ascii"))
print(b.encode("utf-8"))
# b'\xe5\xb0\x8f\xe6\x98\x8e'
# 解码
print(b'\xe5\xb0\x8f\xe6\x98\x8e'.decode("utf-8"))
print(b"abc".decode("ascii"))
1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
python中的内容编码的更多相关文章
- 如何在Python 中使用UTF-8 编码 && Python 使用 注释,Python ,UTF-8 编码 , Python 注释
如何在Python 中使用UTF-8 编码 && Python 使用 注释,Python ,UTF-8 编码 , Python 注释 PIP $ pip install beauti ...
- Python中进行Base64编码和解码
Base64编码 广泛应用于MIME协议,作为电子邮件的传输编码,生成的编码可逆,后一两位可能有“=”,生成的编码都是ascii字符.优点:速度快,ascii字符,肉眼不可理解缺点:编码比较长,非常容 ...
- python中的URL编码和解码
python中的URL编码和解码:test.py # 引入urllib的request模块 import urllib.request url = 'https://www.douban.com/j/ ...
- am start的总结,-d参数的总结,以及python中传递内容包含中文及特殊字符&的解决方案
一.am start的内容的整理 主要包含以下内容:am start的常规操作及参数的含义,-d 参数的含义,以及如何在APK中设置参数获取 使用命令如下:adb shell am start -n ...
- Python中的Base64编码的加密与解密
Base64 可以干些啥? Base64编码的作用: 由于某些系统中只能使用ASCII字符.Base64就是用来将非ASCII字符的数据转换成ASCII字符的一种方法. 图片(and种子)base64 ...
- 在python中实现BASE64编码
什么是Base64编码 BASE64是用于传输8Bit字节的编码方式之一,是一种基于64个可打印字符来表示二进制数据的方法. 如下是转换表:The Base64 Alphabet Base64编码可以 ...
- python中zipfile文件名编码的问题
在python中编程导入压缩包,利用zipfile包,从zipinfo读取文件名总是出错,创建的文件名是乱码,写入pgsql更是出错. 但在ubuntu下测试却正常,在windows下测试总是失败. ...
- python中Url链接编码处理(urlencode,urldecode)
做完了flask-web应用,这几天想用爬虫做个好玩的电影链接整合器,平时找电影都是在dytt或者dy2018之类的网站,在用dytt搜索电影<美国队长时>,发现他的搜索链接是这样的:ht ...
- Python中的Unicode编码和UTF-8编码
下午看廖雪峰的Python2.7教程,看到 字符串和编码 一节,有一点感受,结合崔庆才的Python博客 ,把这种感受记录下来: ASCII码:是用一个字节(8bit, 0-255)中的127个字母表 ...
随机推荐
- Mac下包管理平台homebrew的使用
一.安装 参考:http://www.cnblogs.com/EasonJim/p/6287098.html 二.使用 假设我要安装node,命令如下: 安装软件 brew install node ...
- Mac下JDK卸载方法
注:要卸载 Java,必须具有管理员权限,并且必须以 root 用户身份或者使用 sudo 工具来执行删除命令. 按照下面所示,删除一个目录和一个文件(符号链接): 1.单击位于停靠栏中的 Finde ...
- 在linux上一行代码不用写实现自动采集+hadoop分词
在linux上一行代码不用写实现自动采集+hadoop分词 将下面的shell脚本保存成到xxx.sh,然后执行即可 cd /opt/hadoop mkdir spider wget -O spide ...
- encodeURI、encodeURIComponent、btoa及其应用场景
escape不编码字符有69个:*,+,-,.,/,@,_,0-9,a-z,A-Z encodeURI不编码字符有82个:!,#,$,&,’,(,),*,+,,,-,.,/,:,;,=,?,@ ...
- CentOS 6.4下安装JIRA6.3.6破解汉化
JIRA产品非常完善且功能强大,安装配置简单,多语言支持.界面十分友好,和其他系统如CVS.Subversion(SVN).VSS.LDAP.邮件服务整合得相当好,文档齐全,可用性以及可扩展性方面都十 ...
- MultipartFile的使用小结
Multipartfile转File?File转MultipartFile?可千万别转晕了. 题图:from Google 1. MultipartFile类型转File类型 想要将Multipart ...
- CI中使用log4php调试程序
下载log4php.我下载的版本是:apache-log4php-2.3.0-src.zip.借压缩,将压缩文件中的src/main/php/文件夹拷贝到CI的application/thrid_pa ...
- spring mongodb中去掉_class列
调用mongoTemplate的save方法时, spring-data-mongodb的TypeConverter会自动给document添加一个_class属性, 值是你保存的类名. 这种设计并没 ...
- Redis常用命令整理
doc 环境下使用命令: keys 命令 ? 匹配一个字符 * 匹配任意个(包括0个)字符 [] 匹配括号间的任一个字符, ...
- Virtualbox/Vagrant安装
它们分别是什么? VirtualBox: 号称是最强的免费虚拟机软件和VM类似. 不仅具有丰富的特色,而且性能也很优异. Vagrant: 是一个基于Ruby的工具,用于创建和部署虚拟化开发环境. 使 ...