urllib2的GET和POST请求(五)
urllib2默认只支持HTTP/HTTPS的GET和POST方法
urllib.urlencode()
urllib 和 urllib2 都是接受URL请求的相关模块,但是提供了不同的功能。两个最显著的不同如下:
urllib 仅可以接受URL,不能创建 设置了headers 的Request 类实例;
但是 urllib 提供
urlencode方法用来GET查询字符串的产生,而 urllib2 则没有。(这是 urllib 和 urllib2 经常一起使用的主要原因)编码工作使用urllib的
urlencode()函数,帮我们将key:value这样的键值对转换成"key=value"这样的字符串,解码工作可以使用urllib的unquote()函数。(注意,不是urllib2.urlencode() )
# IPython2 中的测试结果
In [1]: import urllib In [2]: word = {"wd" : "传智播客"} # 通过urllib.urlencode()方法,将字典键值对按URL编码转换,从而能被web服务器接受。
In [3]: urllib.urlencode(word)
Out[3]: "wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2" # 通过urllib.unquote()方法,把 URL编码字符串,转换回原先字符串。
In [4]: print urllib.unquote("wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2")
wd=传智播客
一般HTTP请求提交数据,需要编码成 URL编码格式,然后做为url的一部分,或者作为参数传到Request对象中。
Get方式
GET请求一般用于我们向服务器获取数据,比如说,我们用百度搜索传智播客:https://www.baidu.com/s?wd=传智播客
浏览器的url会跳转成如图所示:
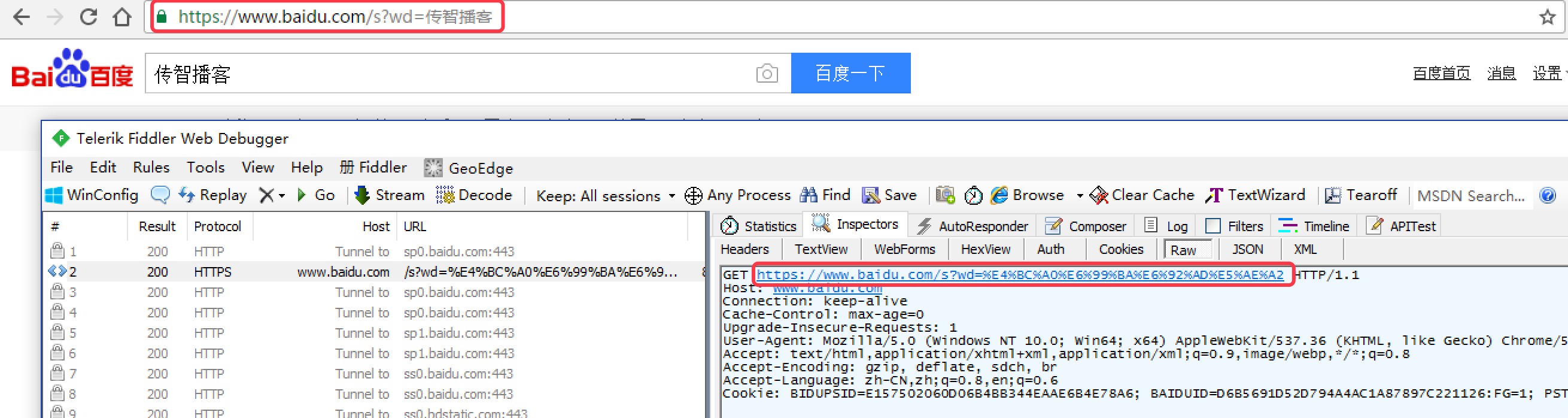
https://www.baidu.com/s?wd=%E4%BC%A0%E6%99%BA%E6%92%AD%E5%AE%A2
在其中我们可以看到在请求部分里,http://www.baidu.com/s? 之后出现一个长长的字符串,其中就包含我们要查询的关键词传智播客,于是我们可以尝试用默认的Get方式来发送请求。
# urllib2_get.py import urllib #负责url编码处理
import urllib2 url = "http://www.baidu.com/s"
word = {"wd":"传智播客"}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
newurl = url + "?" + word # url首个分隔符就是 ? headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"} request = urllib2.Request(newurl, headers=headers) response = urllib2.urlopen(request) print response.read()
批量爬取贴吧页面数据
首先我们创建一个python文件, tiebaSpider.py,我们要完成的是,输入一个百度贴吧的地址,比如:
百度贴吧LOL吧第一页:http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0
第二页: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=50
第三页: http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=100
发现规律了吧,贴吧中每个页面不同之处,就是url最后的pn的值,其余的都是一样的,我们可以抓住这个规律。
简单写一个小爬虫程序,来爬取百度LOL吧的所有网页。
- 先写一个main,提示用户输入要爬取的贴吧名,并用urllib.urlencode()进行转码,然后组合url,假设是lol吧,那么组合后的url就是:
http://tieba.baidu.com/f?kw=lol
# 模拟 main 函数
if __name__ == "__main__": kw = raw_input("请输入需要爬取的贴吧:")
# 输入起始页和终止页,str转成int类型
beginPage = int(raw_input("请输入起始页:"))
endPage = int(raw_input("请输入终止页:")) url = "http://tieba.baidu.com/f?"
key = urllib.urlencode({"kw" : kw}) # 组合后的url示例:http://tieba.baidu.com/f?kw=lol
url = url + key
tiebaSpider(url, beginPage, endPage)
- 接下来,我们写一个百度贴吧爬虫接口,我们需要传递3个参数给这个接口, 一个是main里组合的url地址,以及起始页码和终止页码,表示要爬取页码的范围。
def tiebaSpider(url, beginPage, endPage):
"""
作用:负责处理url,分配每个url去发送请求
url:需要处理的第一个url
beginPage: 爬虫执行的起始页面
endPage: 爬虫执行的截止页面
""" for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50 filename = "第" + str(page) + "页.html"
# 组合为完整的 url,并且pn值每次增加50
fullurl = url + "&pn=" + str(pn)
#print fullurl # 调用loadPage()发送请求获取HTML页面
html = loadPage(fullurl, filename)
# 将获取到的HTML页面写入本地磁盘文件
writeFile(html, filename)
- 我们已经之前写出一个爬取一个网页的代码。现在,我们可以将它封装成一个小函数loadPage,供我们使用。
def loadPage(url, filename):
'''
作用:根据url发送请求,获取服务器响应文件
url:需要爬取的url地址
filename: 文件名
'''
print "正在下载" + filename headers = {"User-Agent": "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"} request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
return response.read()
- 最后如果我们希望将爬取到了每页的信息存储在本地磁盘上,我们可以简单写一个存储文件的接口。
def writeFile(html, filename):
"""
作用:保存服务器响应文件到本地磁盘文件里
html: 服务器响应文件
filename: 本地磁盘文件名
"""
print "正在存储" + filename
with open(filename, 'w') as f:
f.write(html)
print "-" * 20
其实很多网站都是这样的,同类网站下的html页面编号,分别对应网址后的网页序号,只要发现规律就可以批量爬取页面了。
POST方式:
上面我们说了Request请求对象的里有data参数,它就是用在POST里的,我们要传送的数据就是这个参数data,data是一个字典,里面要匹配键值对。
有道词典翻译网站:
输入测试数据,再通过使用Fiddler观察,其中有一条是POST请求,而向服务器发送的请求数据并不是在url里,那么我们可以试着模拟这个POST请求。

于是,我们可以尝试用POST方式发送请求。
import urllib
import urllib2 # POST请求的目标URL
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null" headers={"User-Agent": "Mozilla...."} formdata = {
"type":"AUTO",
"i":"i love python",
"doctype":"json",
"xmlVersion":"1.8",
"keyfrom":"fanyi.web",
"ue":"UTF-8",
"action":"FY_BY_ENTER",
"typoResult":"true"
} data = urllib.urlencode(formdata) request = urllib2.Request(url, data = data, headers = headers)
response = urllib2.urlopen(request)
print response.read()
发送POST请求时,需要特别注意headers的一些属性:
Content-Length: 144: 是指发送的表单数据长度为144,也就是字符个数是144个。
X-Requested-With: XMLHttpRequest:表示Ajax异步请求。
Content-Type: application/x-www-form-urlencoded: 表示浏览器提交 Web 表单时使用,表单数据会按照 name1=value1&name2=value2 键值对形式进行编码。
获取AJAX加载的内容
有些网页内容使用AJAX加载,只要记得,AJAX一般返回的是JSON,直接对AJAX地址进行post或get,就返回JSON数据了。
"作为一名爬虫工程师,你最需要关注的,是数据的来源"
import urllib
import urllib2 # demo1 url = "https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action" headers={"User-Agent": "Mozilla...."} # 变动的是这两个参数,从start开始往后显示limit个
formdata = {
'start':'',
'limit':''
}
data = urllib.urlencode(formdata) request = urllib2.Request(url, data = data, headers = headers)
response = urllib2.urlopen(request) print response.read() # demo2 url = "https://movie.douban.com/j/chart/top_list?"
headers={"User-Agent": "Mozilla...."} # 处理所有参数
formdata = {
'type':'',
'interval_id':'100:90',
'action':'',
'start':'',
'limit':''
}
data = urllib.urlencode(formdata) request = urllib2.Request(url, data = data, headers = headers)
response = urllib2.urlopen(request) print response.read()
问题:为什么有时候POST也能在URL内看到数据?
GET方式是直接以链接形式访问,链接中包含了所有的参数,服务器端用Request.QueryString获取变量的值。如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。
POST则不会在网址上显示所有的参数,服务器端用Request.Form获取提交的数据,在Form提交的时候。但是HTML代码里如果不指定 method 属性,则默认为GET请求,Form中提交的数据将会附加在url之后,以
?分开与url分开。表单数据可以作为 URL 字段(method="get")或者 HTTP POST (method="post")的方式来发送。比如在下面的HTML代码中,表单数据将因为 (method="get") 而附加到 URL 上:
<form action="form_action.asp" method="get">
<p>First name: <input type="text" name="fname" /></p>
<p>Last name: <input type="text" name="lname" /></p>
<input type="submit" value="Submit" />
</form>

处理HTTPS请求 SSL证书验证
现在随处可见 https 开头的网站,urllib2可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,如果网站的SSL证书是经过CA认证的,则能够正常访问,如:https://www.baidu.com/等...
如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,比如浏览器在访问12306网站如:https://www.12306.cn/mormhweb/的时候,会警告用户证书不受信任。(据说 12306 网站证书是自己做的,没有通过CA认证)

urllib2在访问的时候则会报出SSLError:
import urllib2
url = "https://www.12306.cn/mormhweb/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
request = urllib2.Request(url, headers = headers)
response = urllib2.urlopen(request)
print response.read()
运行结果:
urllib2.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590)>
所以,如果以后遇到这种网站,我们需要单独处理SSL证书,让程序忽略SSL证书验证错误,即可正常访问。
import urllib
import urllib2
# 1. 导入Python SSL处理模块
import ssl # 2. 表示忽略未经核实的SSL证书认证
context = ssl._create_unverified_context() url = "https://www.12306.cn/mormhweb/" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} request = urllib2.Request(url, headers = headers) # 3. 在urlopen()方法里 指明添加 context 参数
response = urllib2.urlopen(request, context = context) print response.read()
关于CA
CA(Certificate Authority)是数字证书认证中心的简称,是指发放、管理、废除数字证书的受信任的第三方机构,如北京数字认证股份有限公司、上海市数字证书认证中心有限公司等...
CA的作用是检查证书持有者身份的合法性,并签发证书,以防证书被伪造或篡改,以及对证书和密钥进行管理。
现实生活中可以用身份证来证明身份, 那么在网络世界里,数字证书就是身份证。和现实生活不同的是,并不是每个上网的用户都有数字证书的,往往只有当一个人需要证明自己的身份的时候才需要用到数字证书。
普通用户一般是不需要,因为网站并不关心是谁访问了网站,现在的网站只关心流量。但是反过来,网站就需要证明自己的身份了。
比如说现在钓鱼网站很多的,比如你想访问的是www.baidu.com,但其实你访问的是www.daibu.com”,所以在提交自己的隐私信息之前需要验证一下网站的身份,要求网站出示数字证书。
一般正常的网站都会主动出示自己的数字证书,来确保客户端和网站服务器之间的通信数据是加密安全的。
urllib2的GET和POST请求(五)的更多相关文章
- urllib2特点--urllib2.Request对象,定制请求头部信息
# -*- coding: cp936 -*- #python 27 #xiaodeng #urllib2特点--urllib2.Request对象,定制请求 import urllib2 def r ...
- WebApi接口传参不再困惑(4):传参详解 一、get请求 二、post请求 三、put请求 四、delete请求 五、总结
前言:还记得刚使用WebApi那会儿,被它的传参机制折腾了好久,查阅了半天资料.如今,使用WebApi也有段时间了,今天就记录下API接口传参的一些方式方法,算是一个笔记,也希望能帮初学者少走弯路.本 ...
- Python +urllib+urllib2 带数据的post请求实例
#coding:utf-8 ''' Created on 2017年11月2日 @author: li.liu ''' import urllib import urllib2 import re f ...
- python爬虫(五)_urllib2:Get请求和Post请求
本篇将介绍urllib2的Get和Post方法,更多内容请参考:python学习指南 urllib2默认只支持HTTP/HTTPS的GET和POST方法 urllib.urlencode() urll ...
- urllib2 的get请求与post请求
urllib2默认只支持HTTP/HTTPS的GET和POST方法 urllib.urlencode() urllib和urllib2都是接受URL请求的相关参数,但是提供了不同的功能.两个最显著的不 ...
- python通过get方式,post方式发送http请求和接收http响应-urllib urllib2
python通过get方式,post方式发送http请求和接收http响应-- import urllib模块,urllib2模块, httplib模块 http://blog.163.com/xyc ...
- python爬虫入门(一)urllib和urllib2
爬虫简介 什么是爬虫? 爬虫:就是抓取网页数据的程序. HTTP和HTTPS HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的 ...
- 【Python网络爬虫二】使用urllib2抓去网页内容
在Python中通过导入urllib2组件,来完成网页的抓取工作.在python3.x中被改为urllib.request. 爬取具体的过程类似于使用程序模拟IE浏览器的功能,把URL作为HTTP请求 ...
- urllib2
import urllib2response = urllib2.urlopen("http://www.baidu.com")print response.read() urlo ...
随机推荐
- redhat7下mysql5.7.12重启电脑后起不来问题
环境介绍: 64位reahat7 mysql5.7.12 初次安装后mysql运行是正常的,重启操作系统后检查mysql运行状态如下: [root@localhost ~]# systemctl st ...
- 安装完Linux Mint后,发现系统中竟没有中文输入法
安装完Linux Mint后,发现系统中竟没有中文输入法,语言支持之后自动更新过程中有些安装包下载失败. 可以采取下面的方法安装上中文输入法. 1. 安装iBus: sudo add-apt-repo ...
- h5桌面通知Notification
H5中的桌面通知Notification 前言: 对于一个前端开发者,逛网页总会留意一些新奇的功能,对于上班总会用到Teambition的我,总是能收到Notification...所以今天就来研究下 ...
- powerdesigner安装图解
- [转载]字符串匹配的KMP算法
作者: 阮一峰 日期: 2013年5月 1日 字符串匹配是计算机的基本任务之一. 举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另 ...
- Hibernate入门2.简单的项目开发实例
Hibernate入门2.简单的项目开发实例 这一节通过一个简单的项目学习Hibernate项目的配置 代码下载 : 链接: http://pan.baidu.com/s/1zlgjl 密码: p34 ...
- Unit Test Generator 简介
从Visual Studio 2012开始,创建单元测试从右键菜单中消失了,这让开发者感觉很不习惯.其实创建单元测试并不是消失了,只是独立成一个扩展Unit Test Generator,单独安装这个 ...
- 利用javascript:void(0)制作假的提交按钮替代button
在写html页面,我们很自然的在表单提交的地方采用button来作为提交按钮,但是,用<button type=”button”>按钮</button>作为提交代码会有个问题, ...
- 1元抢卡巴KAV_不限量疯抢即日起至2013.10.31截止
活动地址:http://img.kaba365.com/mail_files/kaba1yuan.html
- L196 Hospital educations
Surprisingly,no one knows how many children receive education in English hospitals,still less the co ...